 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Secure Biometric Authentication without Auxiliary Identifiers
Apr 27, 2026The prevalence of biometric authentication has been on the rise due to its ease of use and elimination of weak passwords. To date, most biometric authentication systems have been designed for on-device authentication of the device owner (e.g., smartphones and laptops). Recently, biometric authentication systems have started to emerge that are designed to authenticate users against cloud databases storing representations of biometrics for large numbers of users (potentially millions), such as those facilitating biometric payments. However, the use of a large cloud database introduces a significant attack vector, as a breach of the database could lead to the compromise of all enrolled users' sensitive biometric data. Indeed, all such existing systems either do not adequately protect against such a breach, or are impractical to deploy and use due to their high computational overhead. In this work, we present a new biometric authentication system that provides provable security guarantees against data breaches, while remaining scalable and performant. To do so, we marry artificial intelligence with advanced cryptographic techniques in a novel fashion, providing several optimizations along the way. Our work is the first to show that real-world scalable privacy-preserving biometric authentication without auxiliary identifiers is feasible, and we believe that it will spur widespread industrial adoption and further research in this area.
PLOD: An Abbreviation Detection Dataset for Scientific Documents
Apr 28, 2022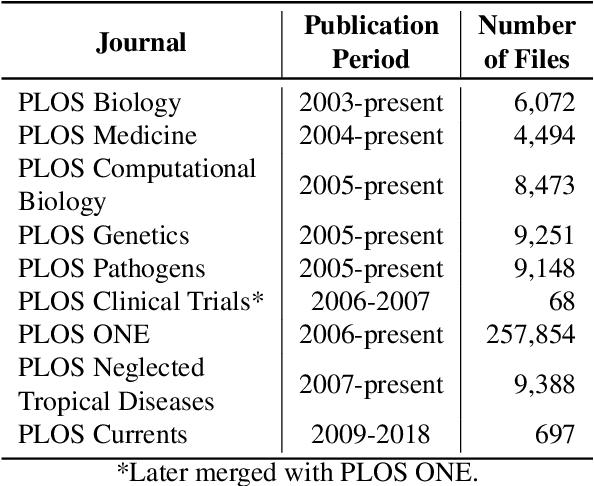
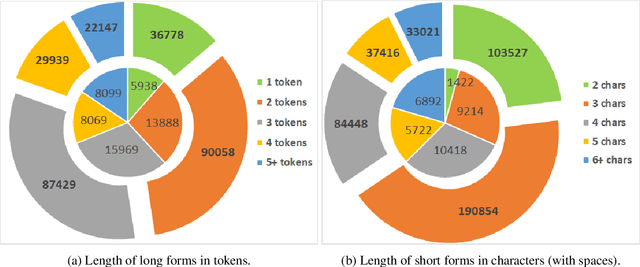
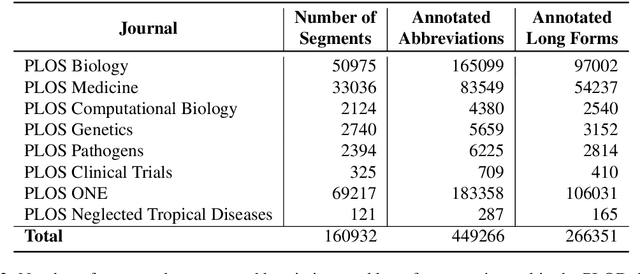
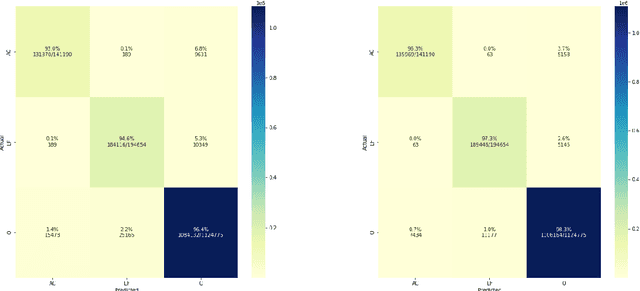
The detection and extraction of abbreviations from unstructured texts can help to improve the performance of Natural Language Processing tasks, such as machine translation and information retrieval. However, in terms of publicly available datasets, there is not enough data for training deep-neural-networks-based models to the point of generalising well over data. This paper presents PLOD, a large-scale dataset for abbreviation detection and extraction that contains 160k+ segments automatically annotated with abbreviations and their long forms. We performed manual validation over a set of instances and a complete automatic validation for this dataset. We then used it to generate several baseline models for detecting abbreviations and long forms. The best models achieved an F1-score of 0.92 for abbreviations and 0.89 for detecting their corresponding long forms. We release this dataset along with our code and all the models publicly in https://github.com/surrey-nlp/PLOD-AbbreviationDetection
An Ensemble Approach to Acronym Extraction using Transformers
Jan 09, 2022
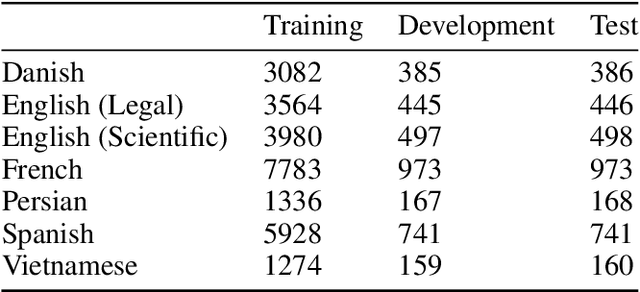
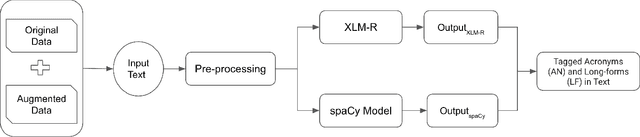
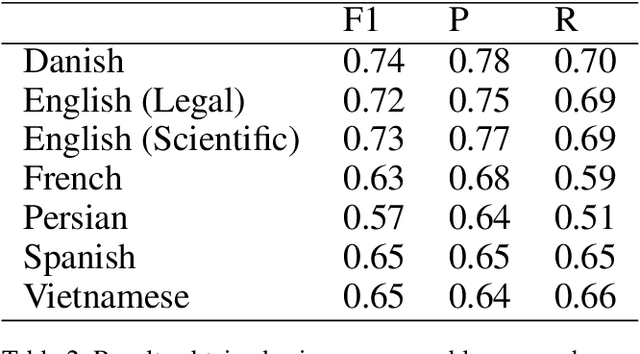
Acronyms are abbreviated units of a phrase constructed by using initial components of the phrase in a text. Automatic extraction of acronyms from a text can help various Natural Language Processing tasks like machine translation, information retrieval, and text summarisation. This paper discusses an ensemble approach for the task of Acronym Extraction, which utilises two different methods to extract acronyms and their corresponding long forms. The first method utilises a multilingual contextual language model and fine-tunes the model to perform the task. The second method relies on a convolutional neural network architecture to extract acronyms and append them to the output of the previous method. We also augment the official training dataset with additional training samples extracted from several open-access journals to help improve the task performance. Our dataset analysis also highlights the noise within the current task dataset. Our approach achieves the following macro-F1 scores on test data released with the task: Danish (0.74), English-Legal (0.72), English-Scientific (0.73), French (0.63), Persian (0.57), Spanish (0.65), Vietnamese (0.65). We release our code and models publicly.
Cognition-aware Cognate Detection
Dec 15, 2021
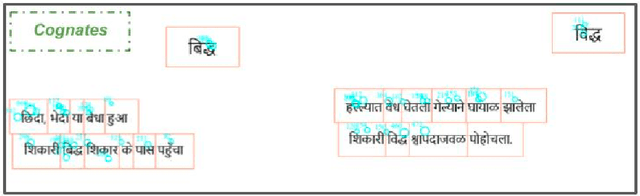

Automatic detection of cognates helps downstream NLP tasks of Machine Translation, Cross-lingual Information Retrieval, Computational Phylogenetics and Cross-lingual Named Entity Recognition. Previous approaches for the task of cognate detection use orthographic, phonetic and semantic similarity based features sets. In this paper, we propose a novel method for enriching the feature sets, with cognitive features extracted from human readers' gaze behaviour. We collect gaze behaviour data for a small sample of cognates and show that extracted cognitive features help the task of cognate detection. However, gaze data collection and annotation is a costly task. We use the collected gaze behaviour data to predict cognitive features for a larger sample and show that predicted cognitive features, also, significantly improve the task performance. We report improvements of 10% with the collected gaze features, and 12% using the predicted gaze features, over the previously proposed approaches. Furthermore, we release the collected gaze behaviour data along with our code and cross-lingual models.
Structuring an unordered text document
Jan 29, 2019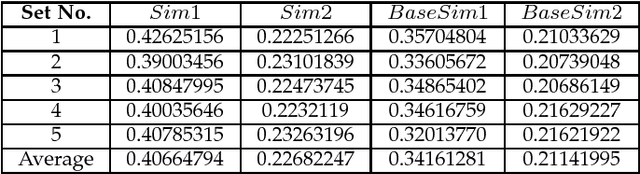
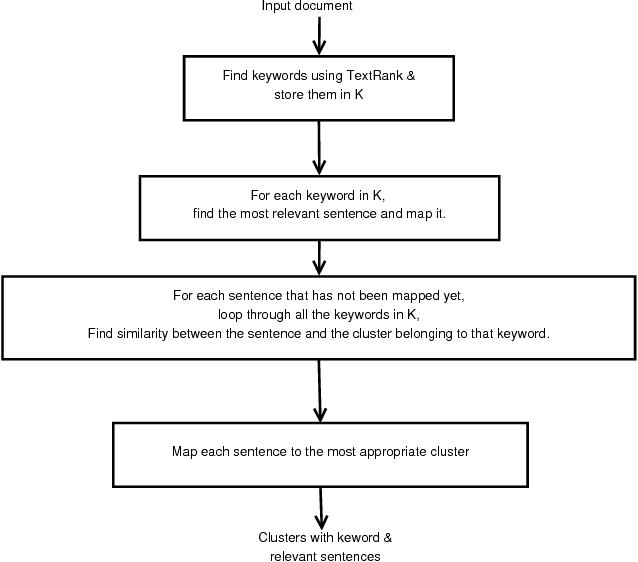
Segmenting an unordered text document into different sections is a very useful task in many text processing applications like multiple document summarization, question answering, etc. This paper proposes structuring of an unordered text document based on the keywords in the document. We test our approach on Wikipedia documents using both statistical and predictive methods such as the TextRank algorithm and Google's USE (Universal Sentence Encoder). From our experimental results, we show that the proposed model can effectively structure an unordered document into sections.
Real time error detection in metal arc welding process using Artificial Neural Netwroks
Mar 10, 2016
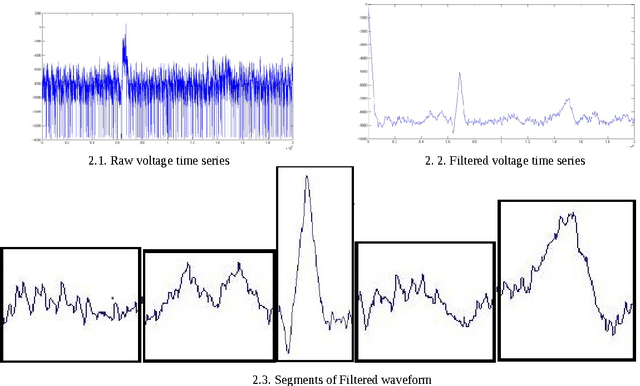
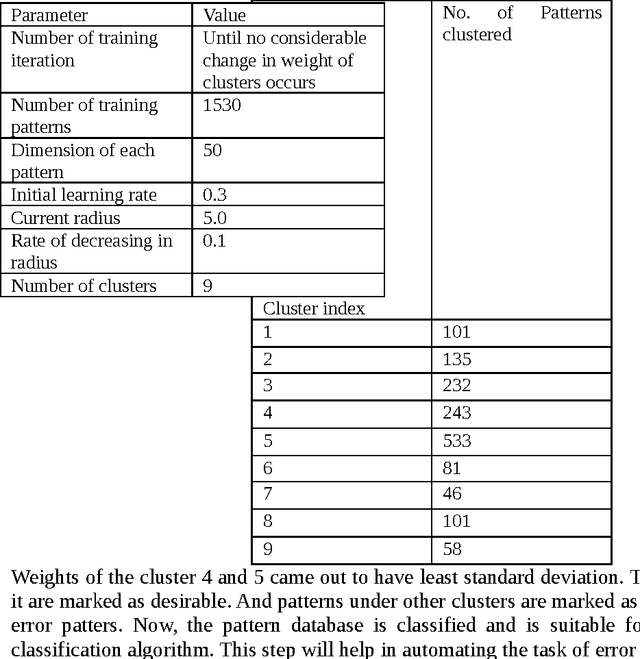
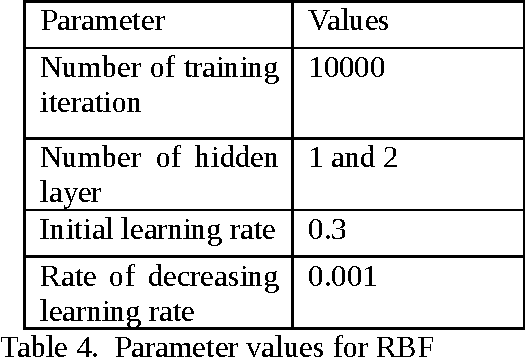
Quality assurance in production line demands reliable weld joints. Human made errors is a major cause of faulty production. Promptly Identifying errors in the weld while welding is in progress will decrease the post inspection cost spent on the welding process. Electrical parameters generated during welding, could able to characterize the process efficiently. Parameter values are collected using high speed data acquisition system. Time series analysis tasks such as filtering, pattern recognition etc. are performed over the collected data. Filtering removes the unwanted noisy signal components and pattern recognition task segregate error patterns in the time series based upon similarity, which is performed by Self Organized mapping clustering algorithm. Welder quality is thus compared by detecting and counting number of error patterns appeared in his parametric time series. Moreover, Self Organized mapping algorithm provides the database in which patterns are segregated into two classes either desirable or undesirable. Database thus generated is used to train the classification algorithms, and thereby automating the real time error detection task. Multi Layer Perceptron and Radial basis function are the two classification algorithms used, and their performance has been compared based on metrics such as specificity, sensitivity, accuracy and time required in training.