 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSome Strategies to Capture Karaka-Yogyata with Special Reference to apadana
Jan 05, 2022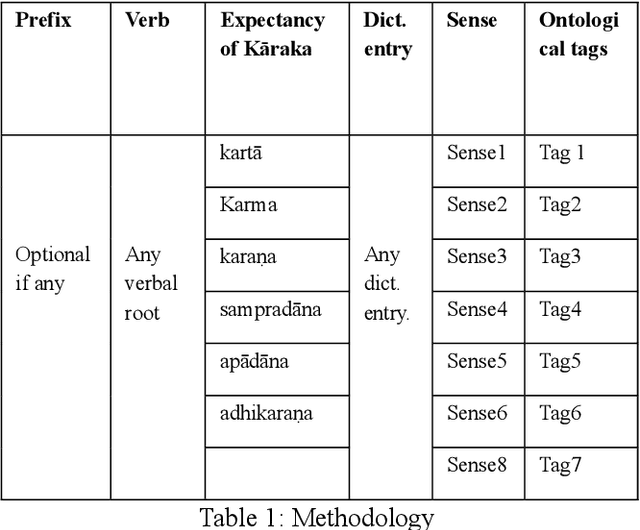
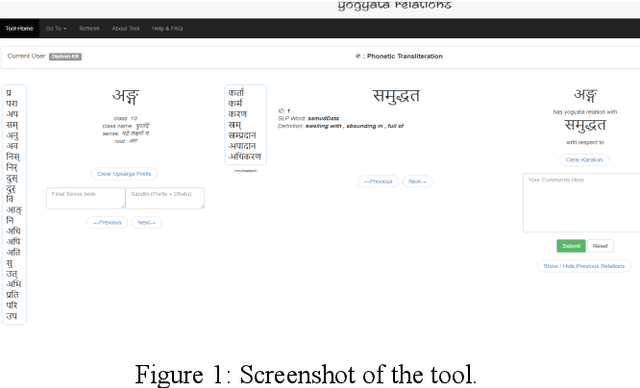
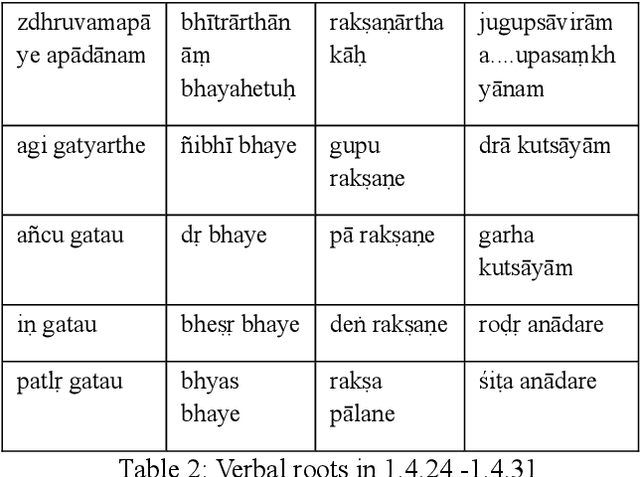
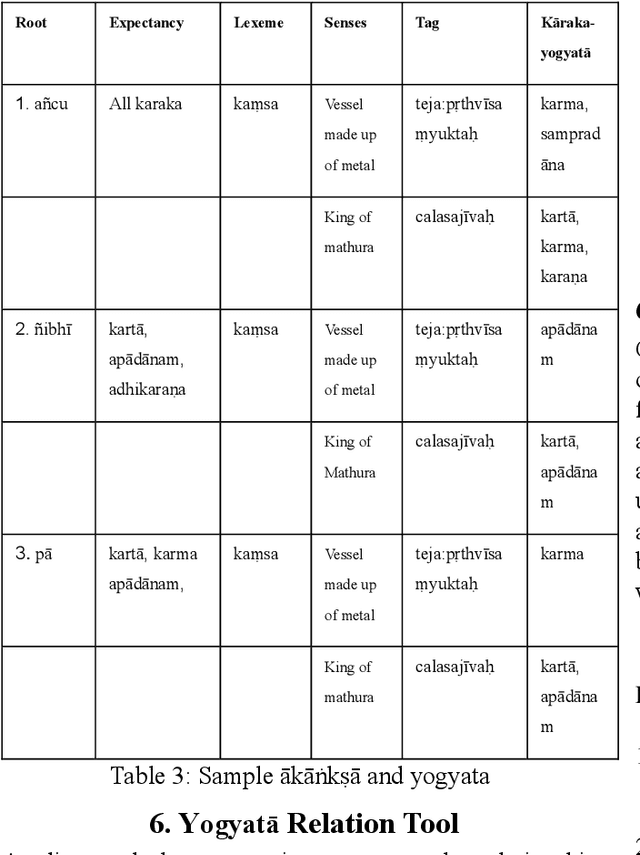
In today's digital world language technology has gained importance. Several softwares, have been developed and are available in the field of computational linguistics. Such tools play a crucial role in making classical language texts easily accessible. Some Indian philosophical schools have contributed towards various techniques of verbal cognition to analyze sentences correctly. These theories can be used to build computational tools for word sense disambiguation (WSD). In the absence of WSD, one cannot have proper verbal cognition. These theories considered the concept of 'Yogyat\=a' (congruity or compatibility) as the indispensable cause of verbal cognition. In this work, we come up with some insights on the basis of these theories to create a tool that will capture Yogyat\=a of words. We describe the problem of ambiguity in a text and present a method to resolve it computationally with the help of Yogyat\=a. Here, only two major schools i.e. Ny\=aya and Vy\=akarana are considered. Our paper attempts to show the implication of the creation of our tool in this area. Also, our tool involves the creation of an 'ontological tag-set' as well as strategies to mark up the lexicon. The introductory description of ablation is also covered in this paper. Such strategies and some case studies shall form the core of our paper.
Strategies of Effective Digitization of Commentaries and Sub-commentaries: Towards the Construction of Textual History
Jan 05, 2022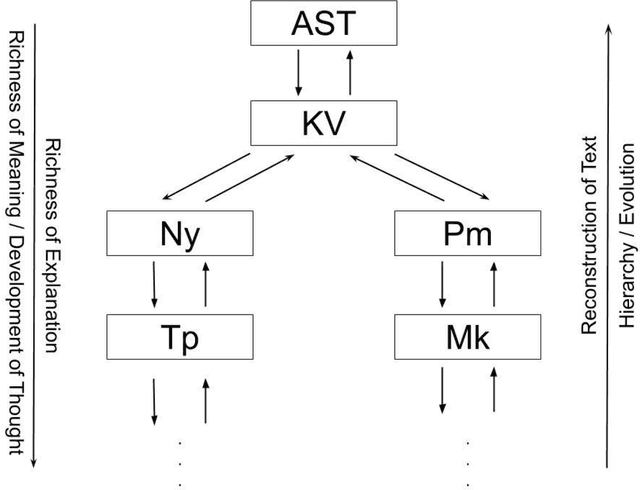


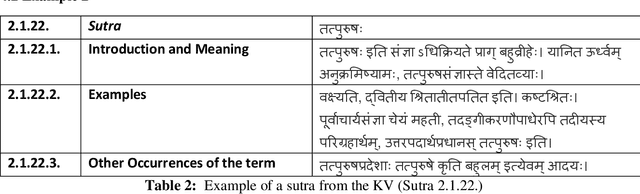
This paper describes additional aspects of a digital tool called the 'Textual History Tool'. We describe its various salient features with special reference to those of its features that may help the philologist digitize commentaries and sub-commentaries on a text. This tool captures the historical evolution of a text through various temporal stages, and interrelated data culled from various types of related texts. We use the text of the K\=a\'sik\=avrtti (KV) as a sample text, and with the help of philologists, we digitize the commentaries available to us. We digitize the Ny\=asa (Ny), the Padama\~njar\=i (Pm) and sub commentaries on the KV text known as the Tantraprad\=ipa (Tp), and the Makaranda (Mk). We divide each commentary and sub-commentary into functional units and describe the methodology and motivation behind the functional unit division. Our functional unit division helps generate more accurate phylogenetic trees for the text, based on distance methods using the data entered in the tool.
Utilizing Wordnets for Cognate Detection among Indian Languages
Dec 30, 2021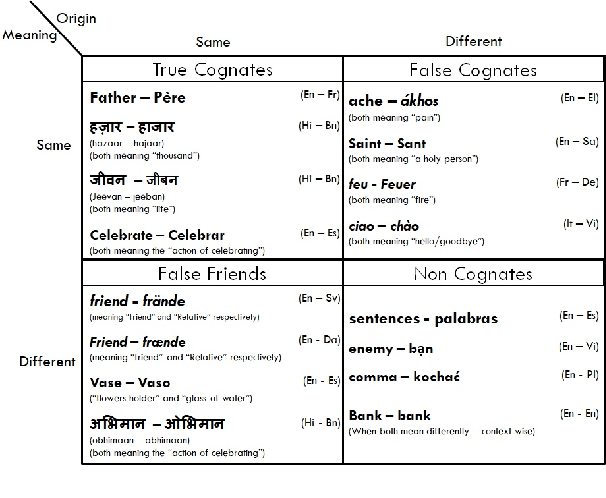
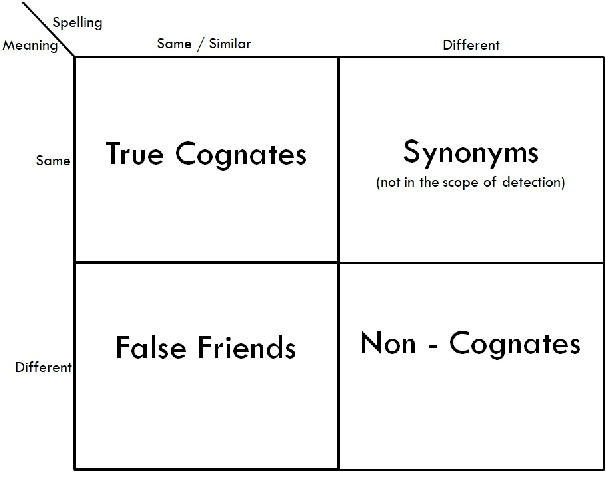
Automatic Cognate Detection (ACD) is a challenging task which has been utilized to help NLP applications like Machine Translation, Information Retrieval and Computational Phylogenetics. Unidentified cognate pairs can pose a challenge to these applications and result in a degradation of performance. In this paper, we detect cognate word pairs among ten Indian languages with Hindi and use deep learning methodologies to predict whether a word pair is cognate or not. We identify IndoWordnet as a potential resource to detect cognate word pairs based on orthographic similarity-based methods and train neural network models using the data obtained from it. We identify parallel corpora as another potential resource and perform the same experiments for them. We also validate the contribution of Wordnets through further experimentation and report improved performance of up to 26%. We discuss the nuances of cognate detection among closely related Indian languages and release the lists of detected cognates as a dataset. We also observe the behaviour of, to an extent, unrelated Indian language pairs and release the lists of detected cognates among them as well.
Challenge Dataset of Cognates and False Friend Pairs from Indian Languages
Dec 17, 2021
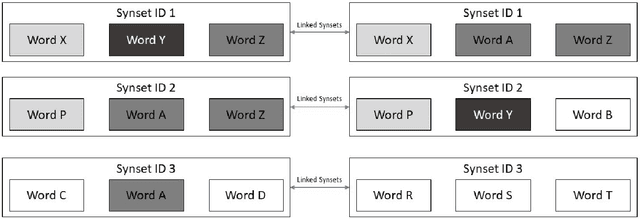


Cognates are present in multiple variants of the same text across different languages (e.g., "hund" in German and "hound" in English language mean "dog"). They pose a challenge to various Natural Language Processing (NLP) applications such as Machine Translation, Cross-lingual Sense Disambiguation, Computational Phylogenetics, and Information Retrieval. A possible solution to address this challenge is to identify cognates across language pairs. In this paper, we describe the creation of two cognate datasets for twelve Indian languages, namely Sanskrit, Hindi, Assamese, Oriya, Kannada, Gujarati, Tamil, Telugu, Punjabi, Bengali, Marathi, and Malayalam. We digitize the cognate data from an Indian language cognate dictionary and utilize linked Indian language Wordnets to generate cognate sets. Additionally, we use the Wordnet data to create a False Friends' dataset for eleven language pairs. We also evaluate the efficacy of our dataset using previously available baseline cognate detection approaches. We also perform a manual evaluation with the help of lexicographers and release the curated gold-standard dataset with this paper.
Harnessing Cross-lingual Features to Improve Cognate Detection for Low-resource Languages
Dec 16, 2021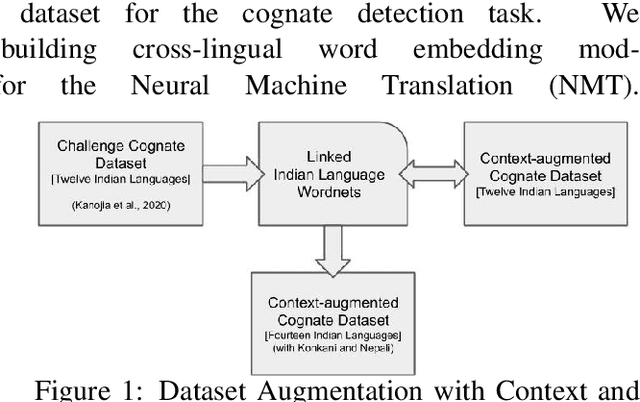
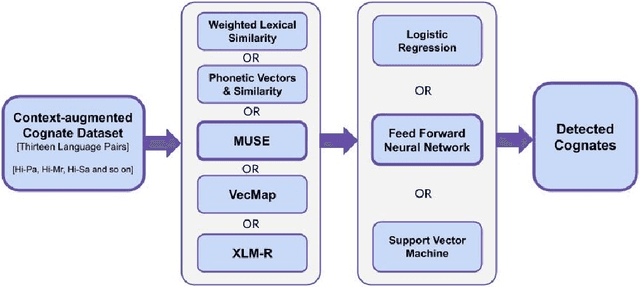
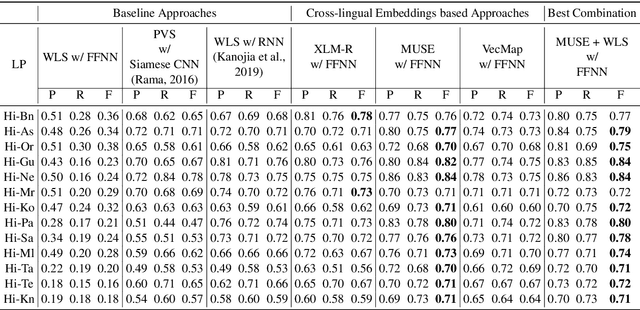

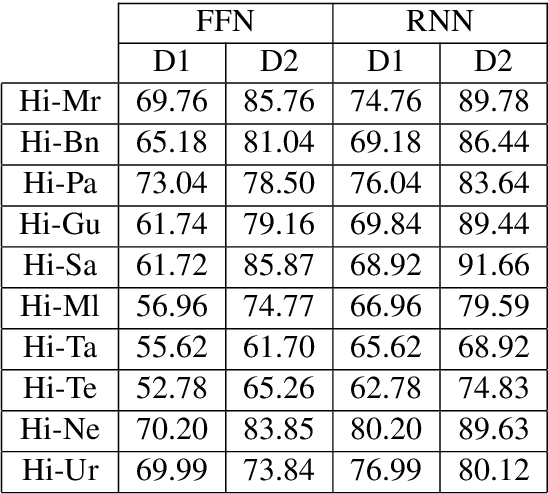
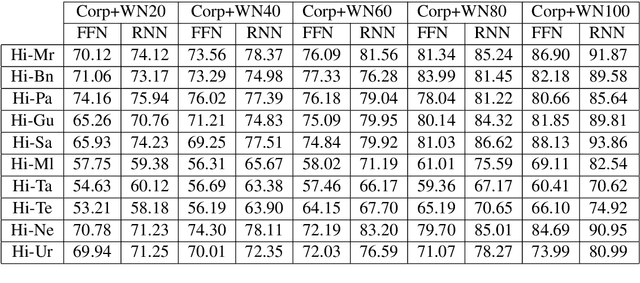
Cognates are variants of the same lexical form across different languages; for example 'fonema' in Spanish and 'phoneme' in English are cognates, both of which mean 'a unit of sound'. The task of automatic detection of cognates among any two languages can help downstream NLP tasks such as Cross-lingual Information Retrieval, Computational Phylogenetics, and Machine Translation. In this paper, we demonstrate the use of cross-lingual word embeddings for detecting cognates among fourteen Indian Languages. Our approach introduces the use of context from a knowledge graph to generate improved feature representations for cognate detection. We, then, evaluate the impact of our cognate detection mechanism on neural machine translation (NMT), as a downstream task. We evaluate our methods to detect cognates on a challenging dataset of twelve Indian languages, namely, Sanskrit, Hindi, Assamese, Oriya, Kannada, Gujarati, Tamil, Telugu, Punjabi, Bengali, Marathi, and Malayalam. Additionally, we create evaluation datasets for two more Indian languages, Konkani and Nepali. We observe an improvement of up to 18% points, in terms of F-score, for cognate detection. Furthermore, we observe that cognates extracted using our method help improve NMT quality by up to 2.76 BLEU. We also release our code, newly constructed datasets and cross-lingual models publicly.
Cognition-aware Cognate Detection
Dec 15, 2021
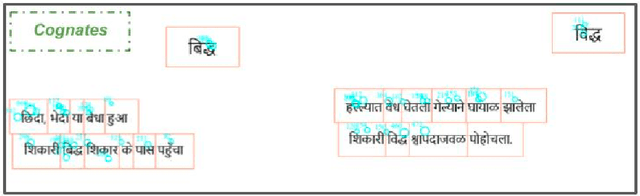

Automatic detection of cognates helps downstream NLP tasks of Machine Translation, Cross-lingual Information Retrieval, Computational Phylogenetics and Cross-lingual Named Entity Recognition. Previous approaches for the task of cognate detection use orthographic, phonetic and semantic similarity based features sets. In this paper, we propose a novel method for enriching the feature sets, with cognitive features extracted from human readers' gaze behaviour. We collect gaze behaviour data for a small sample of cognates and show that extracted cognitive features help the task of cognate detection. However, gaze data collection and annotation is a costly task. We use the collected gaze behaviour data to predict cognitive features for a larger sample and show that predicted cognitive features, also, significantly improve the task performance. We report improvements of 10% with the collected gaze features, and 12% using the predicted gaze features, over the previously proposed approaches. Furthermore, we release the collected gaze behaviour data along with our code and cross-lingual models.
New Vistas to study Bhartrhari: Cognitive NLP
Oct 10, 2018
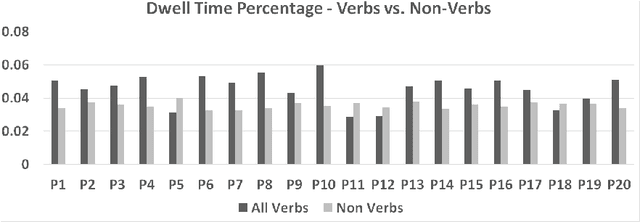
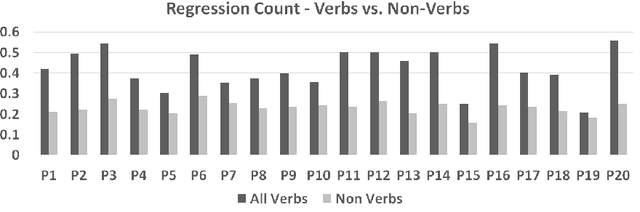
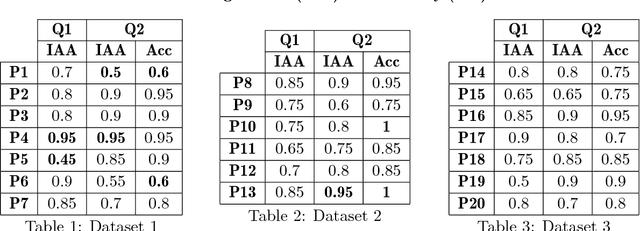
The Sanskrit grammatical tradition which has commenced with Panini's Astadhyayi mostly as a Padasastra has culminated as a Vakyasastra, at the hands of Bhartrhari. The grammarian-philosopher Bhartrhari and his authoritative work 'Vakyapadiya' have been a matter of study for modern scholars, at least for more than 50 years, since Ashok Aklujkar submitted his Ph.D. dissertation at Harvard University. The notions of a sentence and a word as a meaningful linguistic unit in the language have been a subject matter for the discussion in many works that followed later on. While some scholars have applied philological techniques to critically establish the text of the works of Bhartrhari, some others have devoted themselves to exploring philosophical insights from them. Some others have studied his works from the point of view of modern linguistics, and psychology. Few others have tried to justify the views by logical discussions. In this paper, we present a fresh view to study Bhartrhari, and his works, especially the 'Vakyapadiya'. This view is from the field of Natural Language Processing (NLP), more specifically, what is called as Cognitive NLP. We have studied the definitions of a sentence given by Bhartrhari at the beginning of the second chapter of 'Vakyapadiya'. We have researched one of these definitions by conducting an experiment and following the methodology of silent-reading of Sanskrit paragraphs. We collect the Gaze-behavior data of participants and analyze it to understand the underlying comprehension procedure in the human mind and present our results. We evaluate the statistical significance of our results using T-test, and discuss the caveats of our work. We also present some general remarks on this experiment and usefulness of this method for gaining more insights in the work of Bhartrhari.