 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgeb-it-bots RoboCup@Work Team Description Paper 2023
Dec 29, 2023This paper presents the b-it-bots RoboCup@Work team and its current hardware and functional architecture for the KUKA youBot robot. We describe the underlying software framework and the developed capabilities required for operating in industrial environments including features such as reliable and precise navigation, flexible manipulation, robust object recognition and task planning. New developments include an approach to grasp vertical objects, placement of objects by considering the empty space on a workstation, and the process of porting our code to ROS2.
Indian Language Wordnets and their Linkages with Princeton WordNet
Jan 09, 2022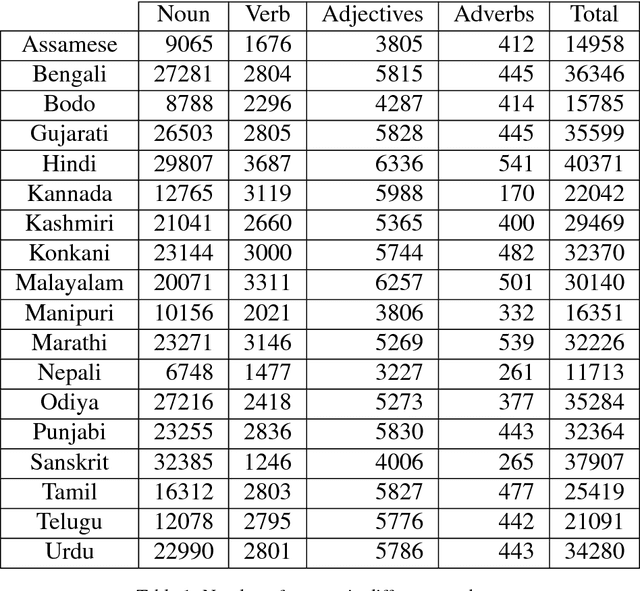
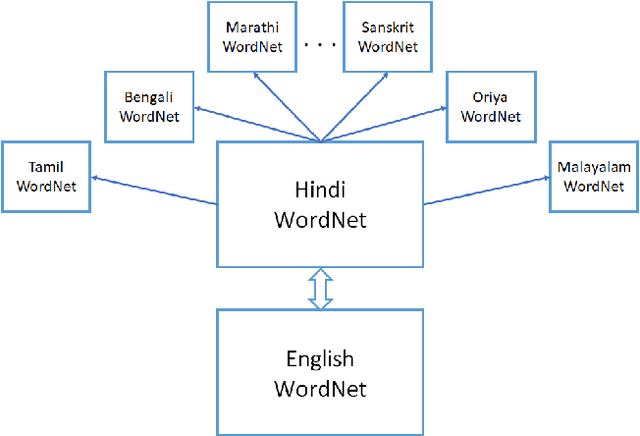

Wordnets are rich lexico-semantic resources. Linked wordnets are extensions of wordnets, which link similar concepts in wordnets of different languages. Such resources are extremely useful in many Natural Language Processing (NLP) applications, primarily those based on knowledge-based approaches. In such approaches, these resources are considered as gold standard/oracle. Thus, it is crucial that these resources hold correct information. Thereby, they are created by human experts. However, human experts in multiple languages are hard to come by. Thus, the community would benefit from sharing of such manually created resources. In this paper, we release mappings of 18 Indian language wordnets linked with Princeton WordNet. We believe that availability of such resources will have a direct impact on the progress in NLP for these languages.
Semi-automatic WordNet Linking using Word Embeddings
Jan 05, 2022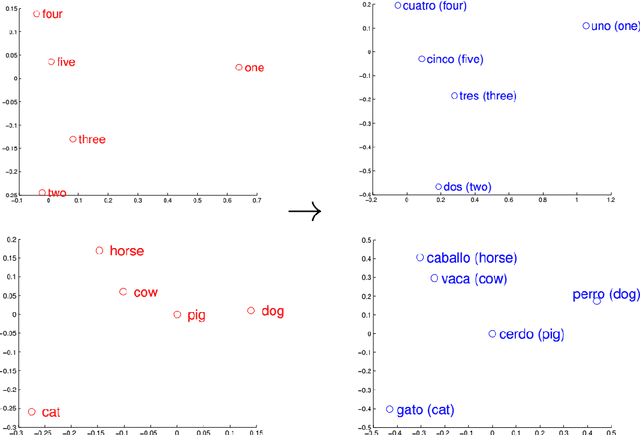

Wordnets are rich lexico-semantic resources. Linked wordnets are extensions of wordnets, which link similar concepts in wordnets of different languages. Such resources are extremely useful in many Natural Language Processing (NLP) applications, primarily those based on knowledge-based approaches. In such approaches, these resources are considered as gold standard/oracle. Thus, it is crucial that these resources hold correct information. Thereby, they are created by human experts. However, manual maintenance of such resources is a tedious and costly affair. Thus techniques that can aid the experts are desirable. In this paper, we propose an approach to link wordnets. Given a synset of the source language, the approach returns a ranked list of potential candidate synsets in the target language from which the human expert can choose the correct one(s). Our technique is able to retrieve a winner synset in the top 10 ranked list for 60% of all synsets and 70% of noun synsets.
Utilizing Wordnets for Cognate Detection among Indian Languages
Dec 30, 2021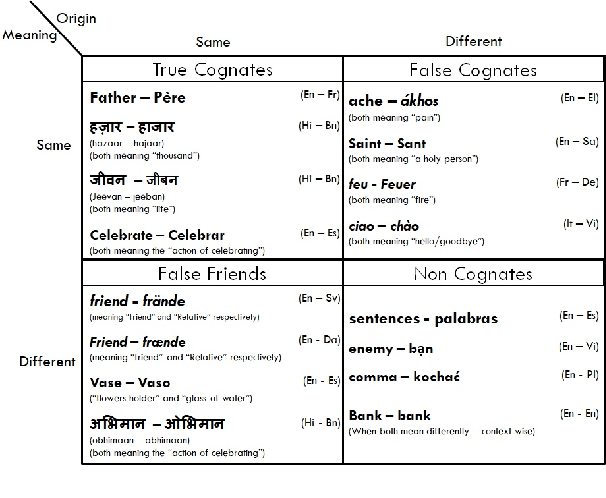
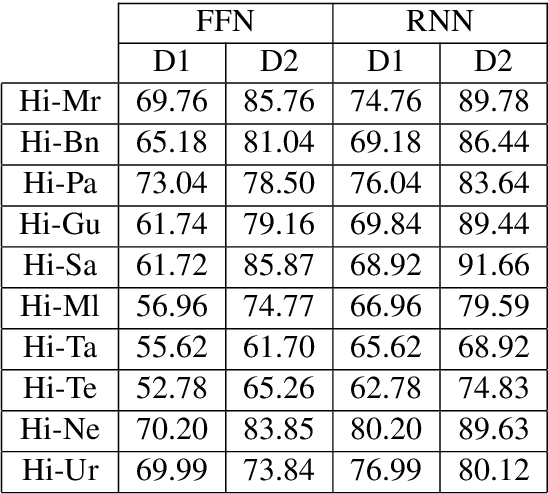
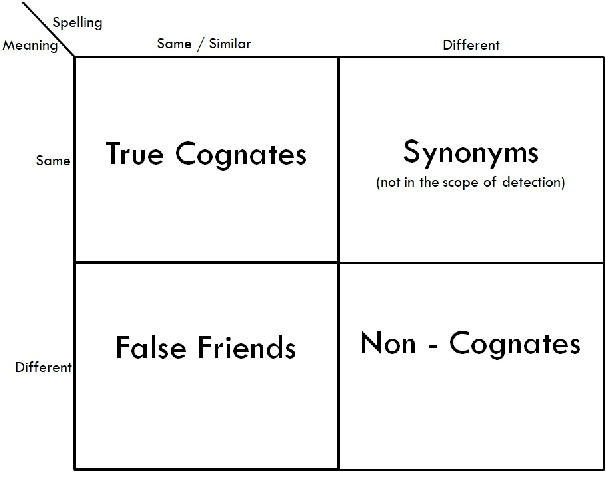
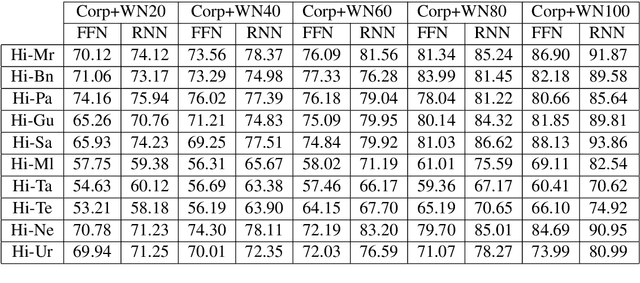
Automatic Cognate Detection (ACD) is a challenging task which has been utilized to help NLP applications like Machine Translation, Information Retrieval and Computational Phylogenetics. Unidentified cognate pairs can pose a challenge to these applications and result in a degradation of performance. In this paper, we detect cognate word pairs among ten Indian languages with Hindi and use deep learning methodologies to predict whether a word pair is cognate or not. We identify IndoWordnet as a potential resource to detect cognate word pairs based on orthographic similarity-based methods and train neural network models using the data obtained from it. We identify parallel corpora as another potential resource and perform the same experiments for them. We also validate the contribution of Wordnets through further experimentation and report improved performance of up to 26%. We discuss the nuances of cognate detection among closely related Indian languages and release the lists of detected cognates as a dataset. We also observe the behaviour of, to an extent, unrelated Indian language pairs and release the lists of detected cognates among them as well.
Eyes are the Windows to the Soul: Predicting the Rating of Text Quality Using Gaze Behaviour
Oct 11, 2018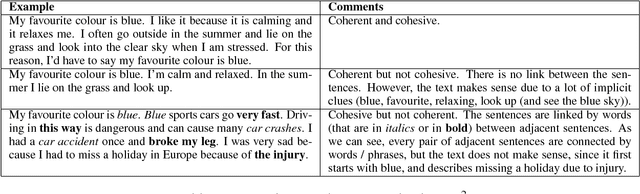



Predicting a reader's rating of text quality is a challenging task that involves estimating different subjective aspects of the text, like structure, clarity, etc. Such subjective aspects are better handled using cognitive information. One such source of cognitive information is gaze behaviour. In this paper, we show that gaze behaviour does indeed help in effectively predicting the rating of text quality. To do this, we first model text quality as a function of three properties - organization, coherence and cohesion. Then, we demonstrate how capturing gaze behaviour helps in predicting each of these properties, and hence the overall quality, by reporting improvements obtained by adding gaze features to traditional textual features for score prediction. We also hypothesize that if a reader has fully understood the text, the corresponding gaze behaviour would give a better indication of the assigned rating, as opposed to partial understanding. Our experiments validate this hypothesis by showing greater agreement between the given rating and the predicted rating when the reader has a full understanding of the text.
Are Word Embedding-based Features Useful for Sarcasm Detection?
Oct 04, 2016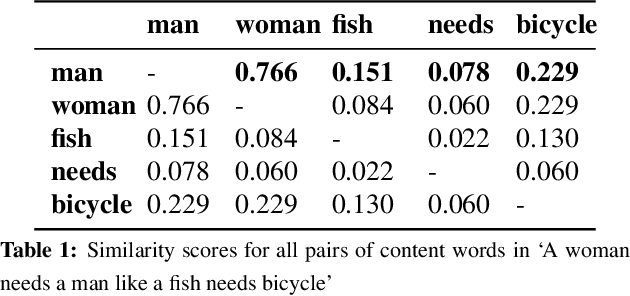
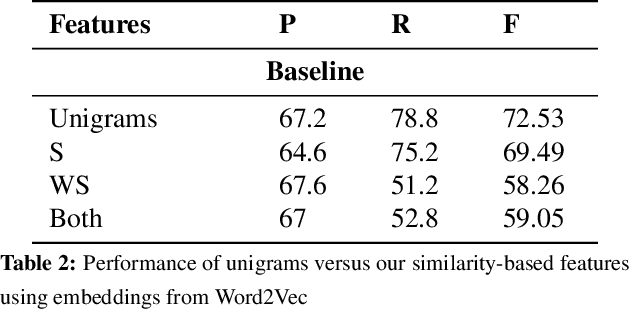
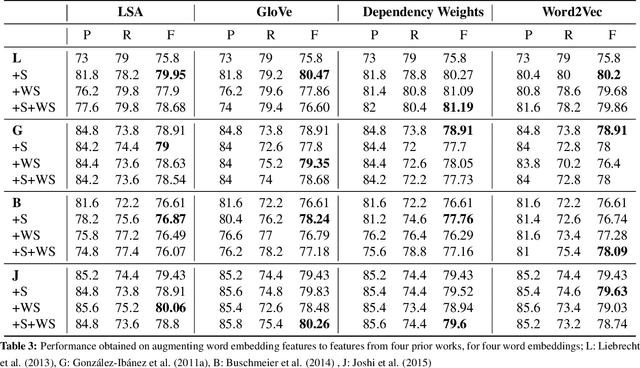
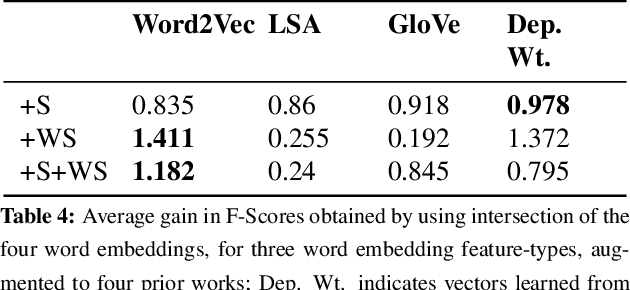
This paper makes a simple increment to state-of-the-art in sarcasm detection research. Existing approaches are unable to capture subtle forms of context incongruity which lies at the heart of sarcasm. We explore if prior work can be enhanced using semantic similarity/discordance between word embeddings. We augment word embedding-based features to four feature sets reported in the past. We also experiment with four types of word embeddings. We observe an improvement in sarcasm detection, irrespective of the word embedding used or the original feature set to which our features are augmented. For example, this augmentation results in an improvement in F-score of around 4\% for three out of these four feature sets, and a minor degradation in case of the fourth, when Word2Vec embeddings are used. Finally, a comparison of the four embeddings shows that Word2Vec and dependency weight-based features outperform LSA and GloVe, in terms of their benefit to sarcasm detection.