 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSYNAPSE: Neuro-Symbolic Visual Thought-to-Text Decoding via Topological Semantic Denoising
May 27, 2026Recent advances in large language models have accelerated open-vocabulary EEG-to-imagined-text decoding, where non-invasive neural activity recorded during visual perception is translated into coherent natural language descriptions of viewed stimuli. However, existing systems remain highly vulnerable to biological noise, where corrupted neural projections induce hallucinated or semantically unstable generation in frozen language models. We introduce SYNAPSE (Symbolic Neural Alignment for Precise Semantic Extraction), a lightweight neuro-symbolic framework that stabilizes neural text generation through inference-time symbolic regularization. By purifying EEG-derived semantic candidates using commonsense graph structure and latent exemplars, SYNAPSE improves semantic stability without end-to-end LLM fine-tuning. Experiments across popular EEG decoding benchmarks and multiple frozen LLM backends demonstrate consistent gains over unconstrained prompting baselines, robustness under object-label ablation, and performance commensurate with substantially more resource-intensive fine-tuned systems, while preserving biometric privacy by localizing raw EEG processing entirely within the encoder stack.
Emotion Entanglement and Bayesian Inference for Multi-Dimensional Emotion Understanding
Apr 01, 2026Understanding emotions in natural language is inherently a multi-dimensional reasoning problem, where multiple affective signals interact through context, interpersonal relations, and situational cues. However, most existing emotion understanding benchmarks rely on short texts and predefined emotion labels, reducing this process to independent label prediction and ignoring the structured dependencies among emotions. To address this limitation, we introduce Emotional Scenarios (EmoScene), a theory-grounded benchmark of 4,731 context-rich scenarios annotated with an 8-dimensional emotion vector derived from Plutchik's basic emotions. We evaluate six instruction-tuned large language models in a zero-shot setting and observe modest performance, with the best model achieving a Macro F1 of 0.501, highlighting the difficulty of context-aware multi-label emotion prediction. Motivated by the observation that emotions rarely occur independently, we further propose an entanglement-aware Bayesian inference framework that incorporates emotion co-occurrence statistics to perform joint posterior inference over the emotion vector. This lightweight post-processing improves structural consistency of predictions and yields notable gains for weaker models (e.g., +0.051 Macro F1 for Qwen2.5-7B). EmoScene therefore provides a challenging benchmark for studying multi-dimensional emotion understanding and the limitations of current language models.
SENSE: Efficient EEG-to-Text via Privacy-Preserving Semantic Retrieval
Mar 17, 2026Decoding brain activity into natural language is a major challenge in AI with important applications in assistive communication, neurotechnology, and human-computer interaction. Most existing Brain-Computer Interface (BCI) approaches rely on memory-intensive fine-tuning of Large Language Models (LLMs) or encoder-decoder models on raw EEG signals, resulting in expensive training pipelines, limited accessibility, and potential exposure of sensitive neural data. We introduce SENSE (SEmantic Neural Sparse Extraction), a lightweight and privacy-preserving framework that translates non-invasive electroencephalography (EEG) into text without LLM fine-tuning. SENSE decouples decoding into two stages: on-device semantic retrieval and prompt-based language generation. EEG signals are locally mapped to a discrete textual space to extract a non-sensitive Bag-of-Words (BoW), which conditions an off-the-shelf LLM to synthesize fluent text in a zero-shot manner. The EEG-to-keyword module contains only ~6M parameters and runs fully on-device, ensuring raw neural signals remain local while only abstract semantic cues interact with language models. Evaluated on a 128-channel EEG dataset across six subjects, SENSE matches or surpasses the generative quality of fully fine-tuned baselines such as Thought2Text while substantially reducing computational overhead. By localizing neural decoding and sharing only derived textual cues, SENSE provides a scalable and privacy-aware retrieval-augmented architecture for next-generation BCIs.
LoR-LUT: Learning Compact 3D Lookup Tables via Low-Rank Residuals
Feb 26, 2026We present LoR-LUT, a unified low-rank formulation for compact and interpretable 3D lookup table (LUT) generation. Unlike conventional 3D-LUT-based techniques that rely on fusion of basis LUTs, which are usually dense tensors, our unified approach extends the current framework by jointly using residual corrections, which are in fact low-rank tensors, together with a set of basis LUTs. The approach described here improves the existing perceptual quality of an image, which is primarily due to the technique's novel use of residual corrections. At the same time, we achieve the same level of trilinear interpolation complexity, using a significantly smaller number of network, residual corrections, and LUT parameters. The experimental results obtained from LoR-LUT, which is trained on the MIT-Adobe FiveK dataset, reproduce expert-level retouching characteristics with high perceptual fidelity and a sub-megabyte model size. Furthermore, we introduce an interactive visualization tool, termed LoR-LUT Viewer, which transforms an input image into the LUT-adjusted output image, via a number of slidebars that control different parameters. The tool provides an effective way to enhance interpretability and user confidence in the visual results. Overall, our proposed formulation offers a compact, interpretable, and efficient direction for future LUT-based image enhancement and style transfer.
Understand the Implication: Learning to Think for Pragmatic Understanding
Jun 16, 2025Pragmatics, the ability to infer meaning beyond literal interpretation, is crucial for social cognition and communication. While LLMs have been benchmarked for their pragmatic understanding, improving their performance remains underexplored. Existing methods rely on annotated labels but overlook the reasoning process humans naturally use to interpret implicit meaning. To bridge this gap, we introduce a novel pragmatic dataset, ImpliedMeaningPreference, that includes explicit reasoning (thoughts) for both correct and incorrect interpretations. Through preference-tuning and supervised fine-tuning, we demonstrate that thought-based learning significantly enhances LLMs' pragmatic understanding, improving accuracy by 11.12% across model families. We further discuss a transfer-learning study where we evaluate the performance of thought-based training for the other tasks of pragmatics (presupposition, deixis) that are not seen during the training time and observe an improvement of 16.10% compared to label-trained models.
ReVision: A Dataset and Baseline VLM for Privacy-Preserving Task-Oriented Visual Instruction Rewriting
Feb 20, 2025



Efficient and privacy-preserving multimodal interaction is essential as AR, VR, and modern smartphones with powerful cameras become primary interfaces for human-computer communication. Existing powerful large vision-language models (VLMs) enabling multimodal interaction often rely on cloud-based processing, raising significant concerns about (1) visual privacy by transmitting sensitive vision data to servers, and (2) their limited real-time, on-device usability. This paper explores Visual Instruction Rewriting, a novel approach that transforms multimodal instructions into text-only commands, allowing seamless integration of lightweight on-device instruction rewriter VLMs (250M parameters) with existing conversational AI systems, enhancing vision data privacy. To achieve this, we present a dataset of over 39,000 examples across 14 domains and develop a compact VLM, pretrained on image captioning datasets and fine-tuned for instruction rewriting. Experimental results, evaluated through NLG metrics such as BLEU, METEOR, and ROUGE, along with semantic parsing analysis, demonstrate that even a quantized version of the model (<500MB storage footprint) can achieve effective instruction rewriting, thus enabling privacy-focused, multimodal AI applications.
A Survey on Bridging EEG Signals and Generative AI: From Image and Text to Beyond
Feb 18, 2025Integration of Brain-Computer Interfaces (BCIs) and Generative Artificial Intelligence (GenAI) has opened new frontiers in brain signal decoding, enabling assistive communication, neural representation learning, and multimodal integration. BCIs, particularly those leveraging Electroencephalography (EEG), provide a non-invasive means of translating neural activity into meaningful outputs. Recent advances in deep learning, including Generative Adversarial Networks (GANs) and Transformer-based Large Language Models (LLMs), have significantly improved EEG-based generation of images, text, and speech. This paper provides a literature review of the state-of-the-art in EEG-based multimodal generation, focusing on (i) EEG-to-image generation through GANs, Variational Autoencoders (VAEs), and Diffusion Models, and (ii) EEG-to-text generation leveraging Transformer based language models and contrastive learning methods. Additionally, we discuss the emerging domain of EEG-to-speech synthesis, an evolving multimodal frontier. We highlight key datasets, use cases, challenges, and EEG feature encoding methods that underpin generative approaches. By providing a structured overview of EEG-based generative AI, this survey aims to equip researchers and practitioners with insights to advance neural decoding, enhance assistive technologies, and expand the frontiers of brain-computer interaction.
ETF: An Entity Tracing Framework for Hallucination Detection in Code Summaries
Oct 22, 2024Recent advancements in large language models (LLMs) have significantly enhanced their ability to understand both natural language and code, driving their use in tasks like natural language-to-code (NL2Code) and code summarization. However, LLMs are prone to hallucination-outputs that stray from intended meanings. Detecting hallucinations in code summarization is especially difficult due to the complex interplay between programming and natural languages. We introduce a first-of-its-kind dataset with $\sim$10K samples, curated specifically for hallucination detection in code summarization. We further propose a novel Entity Tracing Framework (ETF) that a) utilizes static program analysis to identify code entities from the program and b) uses LLMs to map and verify these entities and their intents within generated code summaries. Our experimental analysis demonstrates the effectiveness of the framework, leading to a 0.73 F1 score. This approach provides an interpretable method for detecting hallucinations by grounding entities, allowing us to evaluate summary accuracy.
Thought2Text: Text Generation from EEG Signal using Large Language Models (LLMs)
Oct 10, 2024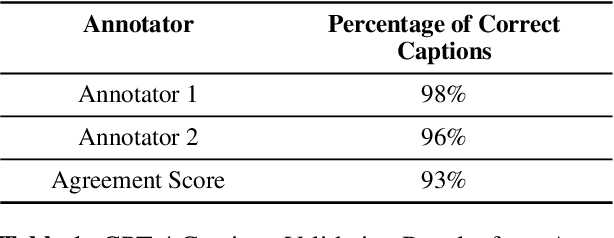
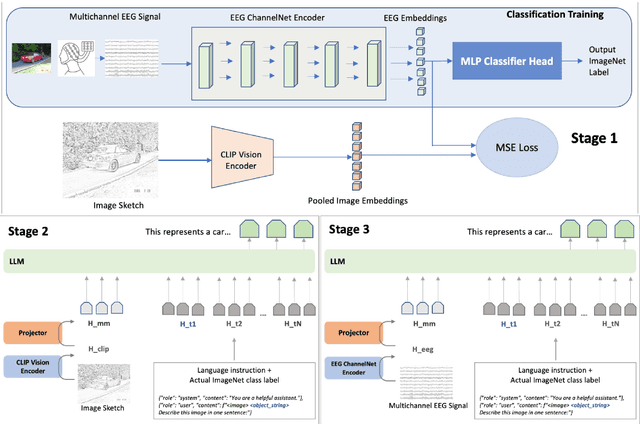
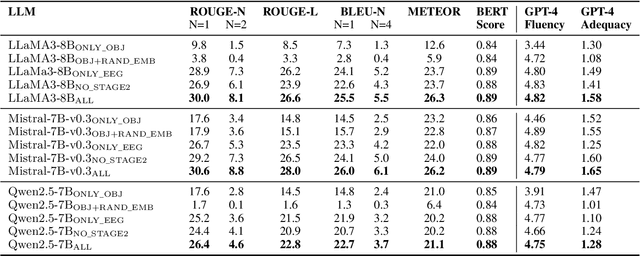
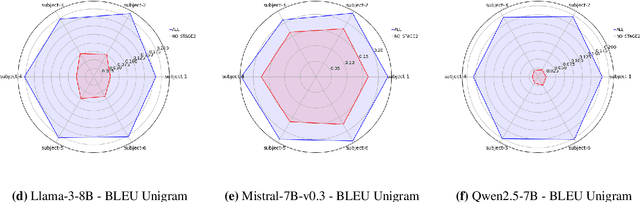
Decoding and expressing brain activity in a comprehensible form is a challenging frontier in AI. This paper presents Thought2Text, which uses instruction-tuned Large Language Models (LLMs) fine-tuned with EEG data to achieve this goal. The approach involves three stages: (1) training an EEG encoder for visual feature extraction, (2) fine-tuning LLMs on image and text data, enabling multimodal description generation, and (3) further fine-tuning on EEG embeddings to generate text directly from EEG during inference. Experiments on a public EEG dataset collected for six subjects with image stimuli demonstrate the efficacy of multimodal LLMs (LLaMa-v3, Mistral-v0.3, Qwen2.5), validated using traditional language generation evaluation metrics, GPT-4 based assessments, and evaluations by human expert. This approach marks a significant advancement towards portable, low-cost "thoughts-to-text" technology with potential applications in both neuroscience and natural language processing (NLP).
Bridging the Language Gap: Enhancing Multilingual Prompt-Based Code Generation in LLMs via Zero-Shot Cross-Lingual Transfer
Aug 19, 2024



The use of Large Language Models (LLMs) for program code generation has gained substantial attention, but their biases and limitations with non-English prompts challenge global inclusivity. This paper investigates the complexities of multilingual prompt-based code generation. Our evaluations of LLMs, including CodeLLaMa and CodeGemma, reveal significant disparities in code quality for non-English prompts; we also demonstrate the inadequacy of simple approaches like prompt translation, bootstrapped data augmentation, and fine-tuning. To address this, we propose a zero-shot cross-lingual approach using a neural projection technique, integrating a cross-lingual encoder like LASER artetxe2019massively to map multilingual embeddings from it into the LLM's token space. This method requires training only on English data and scales effectively to other languages. Results on a translated and quality-checked MBPP dataset show substantial improvements in code quality. This research promotes a more inclusive code generation landscape by empowering LLMs with multilingual capabilities to support the diverse linguistic spectrum in programming.