 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRole of Language Relatedness in Multilingual Fine-tuning of Language Models: A Case Study in Indo-Aryan Languages
Sep 22, 2021
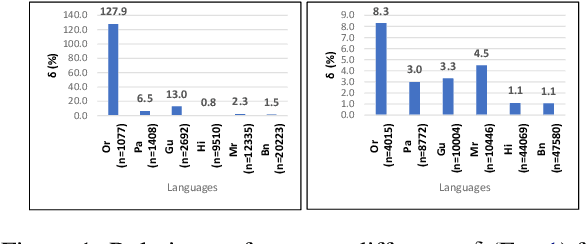

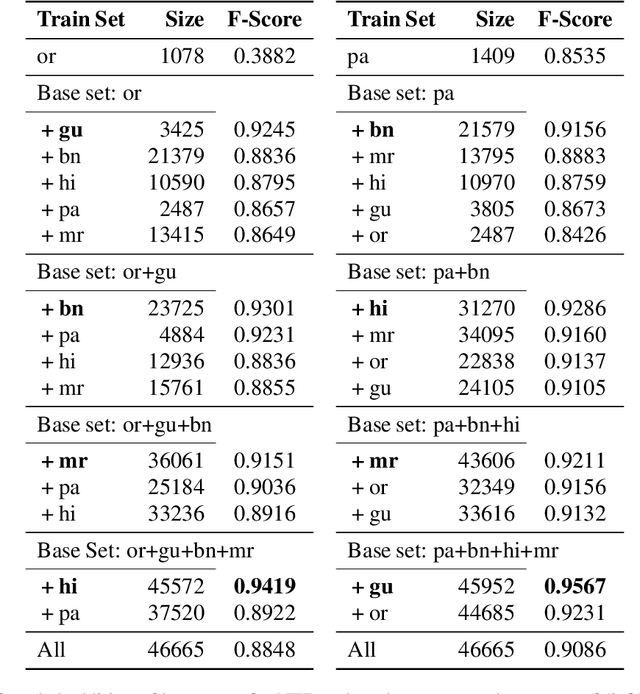
We explore the impact of leveraging the relatedness of languages that belong to the same family in NLP models using multilingual fine-tuning. We hypothesize and validate that multilingual fine-tuning of pre-trained language models can yield better performance on downstream NLP applications, compared to models fine-tuned on individual languages. A first of its kind detailed study is presented to track performance change as languages are added to a base language in a graded and greedy (in the sense of best boost of performance) manner; which reveals that careful selection of subset of related languages can significantly improve performance than utilizing all related languages. The Indo-Aryan (IA) language family is chosen for the study, the exact languages being Bengali, Gujarati, Hindi, Marathi, Oriya, Punjabi and Urdu. The script barrier is crossed by simple rule-based transliteration of the text of all languages to Devanagari. Experiments are performed on mBERT, IndicBERT, MuRIL and two RoBERTa-based LMs, the last two being pre-trained by us. Low resource languages, such as Oriya and Punjabi, are found to be the largest beneficiaries of multilingual fine-tuning. Textual Entailment, Entity Classification, Section Title Prediction, tasks of IndicGLUE and POS tagging form our test bed. Compared to monolingual fine tuning we get relative performance improvement of up to 150% in the downstream tasks. The surprise take-away is that for any language there is a particular combination of other languages which yields the best performance, and any additional language is in fact detrimental.
Topic Transferable Table Question Answering
Sep 15, 2021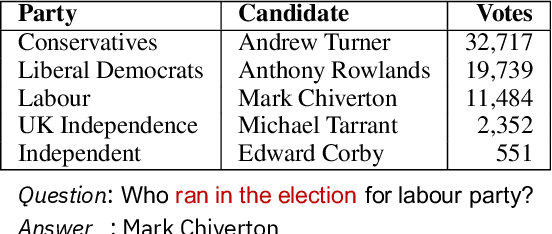
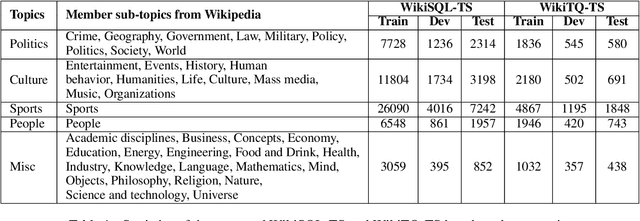
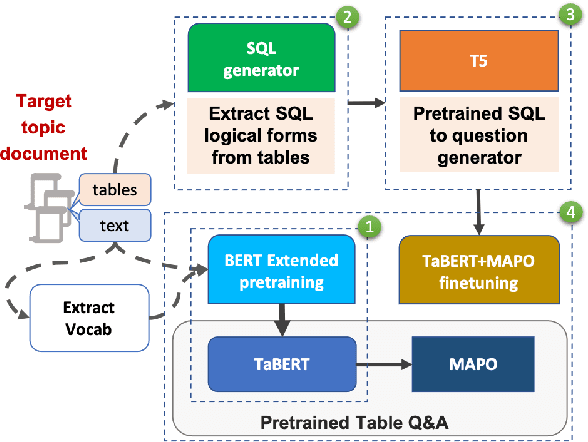
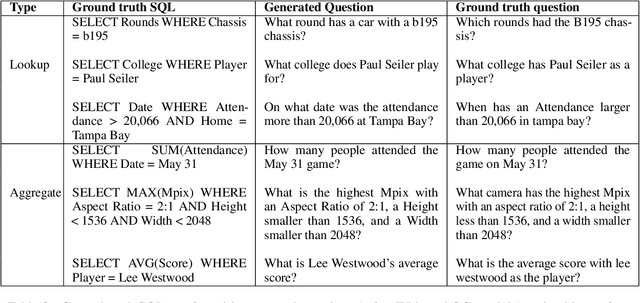
Weakly-supervised table question-answering(TableQA) models have achieved state-of-art performance by using pre-trained BERT transformer to jointly encoding a question and a table to produce structured query for the question. However, in practical settings TableQA systems are deployed over table corpora having topic and word distributions quite distinct from BERT's pretraining corpus. In this work we simulate the practical topic shift scenario by designing novel challenge benchmarks WikiSQL-TS and WikiTQ-TS, consisting of train-dev-test splits in five distinct topic groups, based on the popular WikiSQL and WikiTableQuestions datasets. We empirically show that, despite pre-training on large open-domain text, performance of models degrades significantly when they are evaluated on unseen topics. In response, we propose T3QA (Topic Transferable Table Question Answering) a pragmatic adaptation framework for TableQA comprising of: (1) topic-specific vocabulary injection into BERT, (2) a novel text-to-text transformer generator (such as T5, GPT2) based natural language question generation pipeline focused on generating topic specific training data, and (3) a logical form reranker. We show that T3QA provides a reasonably good baseline for our topic shift benchmarks. We believe our topic split benchmarks will lead to robust TableQA solutions that are better suited for practical deployment.
Representation based meta-learning for few-shot spoken intent recognition
Jun 29, 2021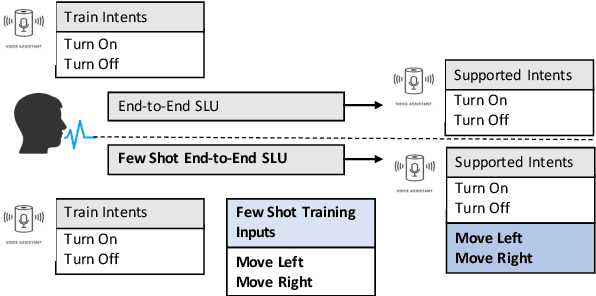
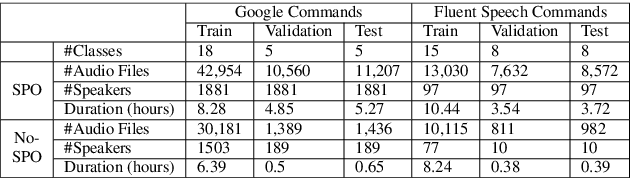
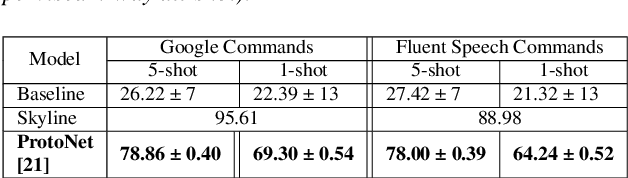
Spoken intent detection has become a popular approach to interface with various smart devices with ease. However, such systems are limited to the preset list of intents-terms or commands, which restricts the quick customization of personal devices to new intents. This paper presents a few-shot spoken intent classification approach with task-agnostic representations via meta-learning paradigm. Specifically, we leverage the popular representation-based meta-learning learning to build a task-agnostic representation of utterances, that then use a linear classifier for prediction. We evaluate three such approaches on our novel experimental protocol developed on two popular spoken intent classification datasets: Google Commands and the Fluent Speech Commands dataset. For a 5-shot (1-shot) classification of novel classes, the proposed framework provides an average classification accuracy of 88.6% (76.3%) on the Google Commands dataset, and 78.5% (64.2%) on the Fluent Speech Commands dataset. The performance is comparable to traditionally supervised classification models with abundant training samples.
AIT-QA: Question Answering Dataset over Complex Tables in the Airline Industry
Jun 24, 2021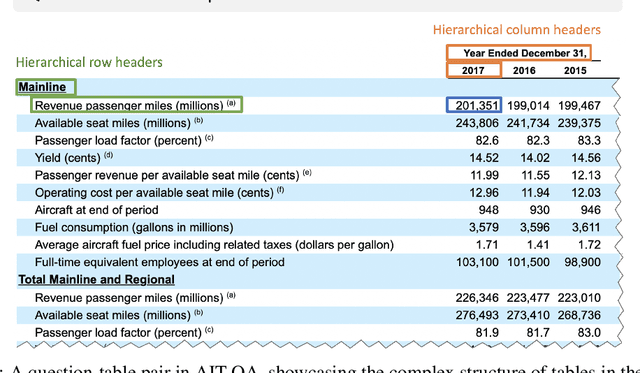

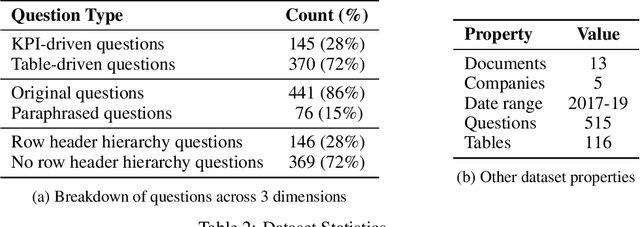

Recent advances in transformers have enabled Table Question Answering (Table QA) systems to achieve high accuracy and SOTA results on open domain datasets like WikiTableQuestions and WikiSQL. Such transformers are frequently pre-trained on open-domain content such as Wikipedia, where they effectively encode questions and corresponding tables from Wikipedia as seen in Table QA dataset. However, web tables in Wikipedia are notably flat in their layout, with the first row as the sole column header. The layout lends to a relational view of tables where each row is a tuple. Whereas, tables in domain-specific business or scientific documents often have a much more complex layout, including hierarchical row and column headers, in addition to having specialized vocabulary terms from that domain. To address this problem, we introduce the domain-specific Table QA dataset AIT-QA (Airline Industry Table QA). The dataset consists of 515 questions authored by human annotators on 116 tables extracted from public U.S. SEC filings (publicly available at: https://www.sec.gov/edgar.shtml) of major airline companies for the fiscal years 2017-2019. We also provide annotations pertaining to the nature of questions, marking those that require hierarchical headers, domain-specific terminology, and paraphrased forms. Our zero-shot baseline evaluation of three transformer-based SOTA Table QA methods - TaPAS (end-to-end), TaBERT (semantic parsing-based), and RCI (row-column encoding-based) - clearly exposes the limitation of these methods in this practical setting, with the best accuracy at just 51.8\% (RCI). We also present pragmatic table preprocessing steps used to pivot and project these complex tables into a layout suitable for the SOTA Table QA models.
Multilingual and code-switching ASR challenges for low resource Indian languages
Apr 01, 2021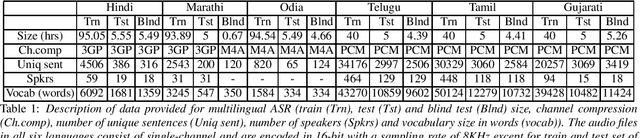
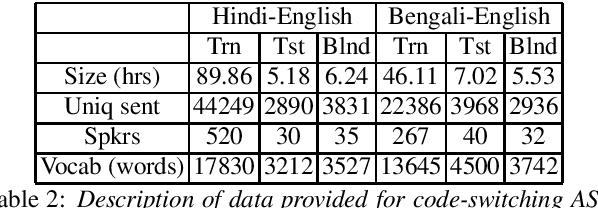
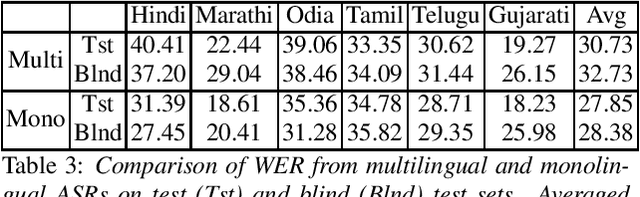
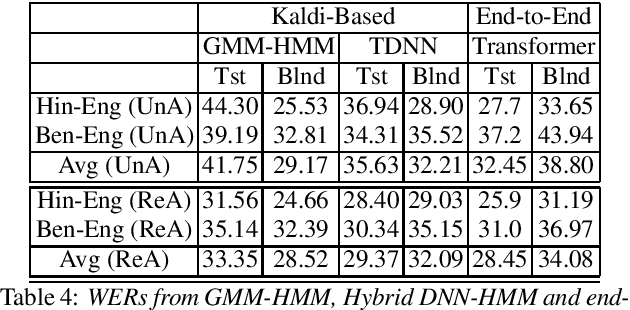
Recently, there is increasing interest in multilingual automatic speech recognition (ASR) where a speech recognition system caters to multiple low resource languages by taking advantage of low amounts of labeled corpora in multiple languages. With multilingualism becoming common in today's world, there has been increasing interest in code-switching ASR as well. In code-switching, multiple languages are freely interchanged within a single sentence or between sentences. The success of low-resource multilingual and code-switching ASR often depends on the variety of languages in terms of their acoustics, linguistic characteristics as well as the amount of data available and how these are carefully considered in building the ASR system. In this challenge, we would like to focus on building multilingual and code-switching ASR systems through two different subtasks related to a total of seven Indian languages, namely Hindi, Marathi, Odia, Tamil, Telugu, Gujarati and Bengali. For this purpose, we provide a total of ~600 hours of transcribed speech data, comprising train and test sets, in these languages including two code-switched language pairs, Hindi-English and Bengali-English. We also provide a baseline recipe for both the tasks with a WER of 30.73% and 32.45% on the test sets of multilingual and code-switching subtasks, respectively.
Template Controllable keywords-to-text Generation
Nov 07, 2020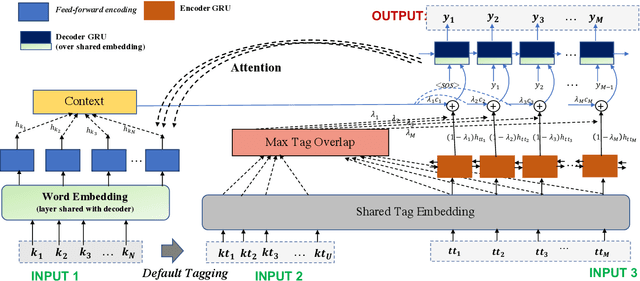
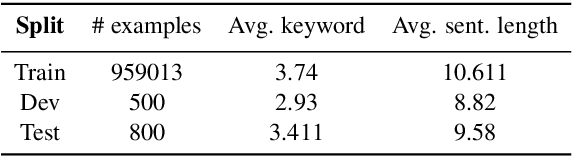
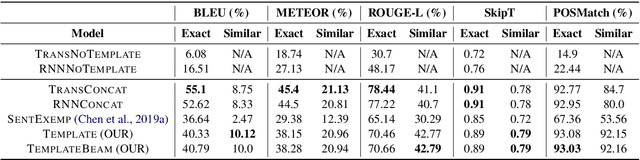
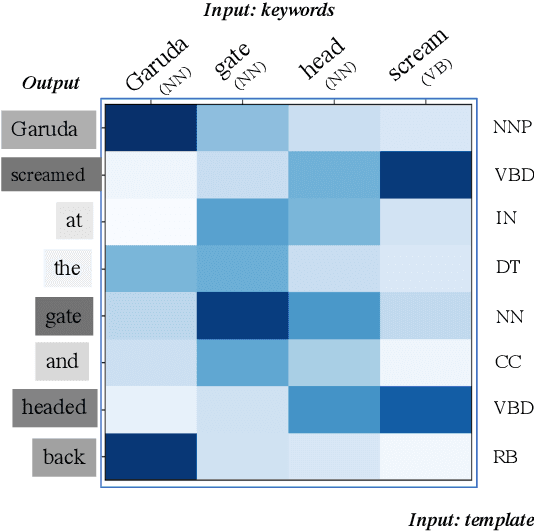
This paper proposes a novel neural model for the understudied task of generating text from keywords. The model takes as input a set of un-ordered keywords, and part-of-speech (POS) based template instructions. This makes it ideal for surface realization in any NLG setup. The framework is based on the encode-attend-decode paradigm, where keywords and templates are encoded first, and the decoder judiciously attends over the contexts derived from the encoded keywords and templates to generate the sentences. Training exploits weak supervision, as the model trains on a large amount of labeled data with keywords and POS based templates prepared through completely automatic means. Qualitative and quantitative performance analyses on publicly available test-data in various domains reveal our system's superiority over baselines, built using state-of-the-art neural machine translation and controllable transfer techniques. Our approach is indifferent to the order of input keywords.
Addressing target shift in zero-shot learning using grouped adversarial learning
Mar 02, 2020
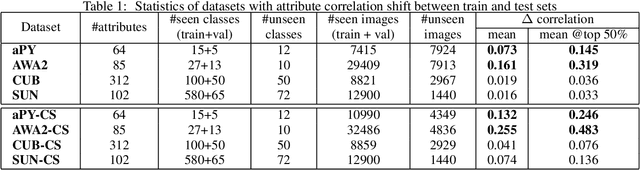
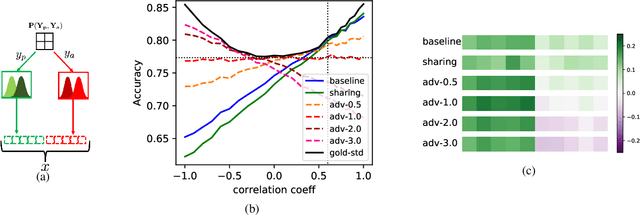
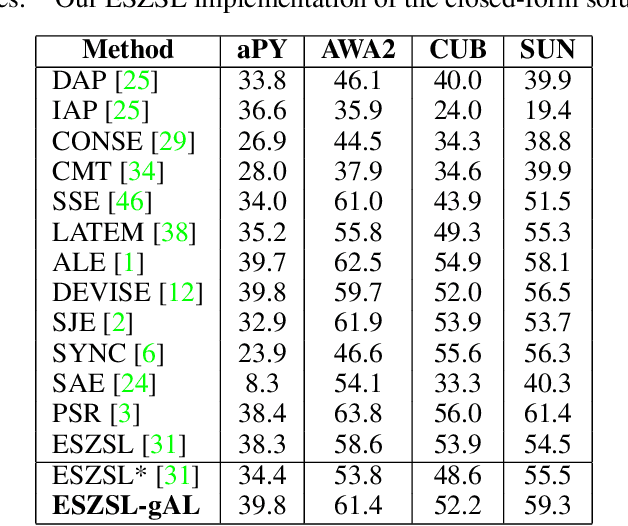
In this paper, we present a new paradigm to zero-shot learning (ZSL) that is trained by utilizing additional information (such as attribute-class mapping) for specific set of unseen classes. We conjecture that such additional information about unseen classes is more readily available than unsupervised image sets. Further, on close examination of the underlying attribute predictors of popular ZSL algorithms, we find that they often leverage attribute correlations to make predictions. While attribute correlations that remain intact in the unseen classes (test) benefit the prediction of difficult attributes, change in correlations can have an adverse effect on ZSL performance. For example, detecting an attribute 'brown' may be the same as detecting 'fur' over an animals' image dataset captured in the tropics. However, such a model might fail on unseen images of Arctic animals. To address this effect, termed target-shift in ZSL, we utilize our proposed framework to design grouped adversarial learning. We introduce grouping of attributes to enable the model to continue to benefit from useful correlations, while restricting cross-group correlations that may be harmful for generalization. Our analysis shows that it is possible to not only constrain the model from leveraging unwanted correlations, but also adjust them to specific test setting using only the additional information (the already available attribute-class mapping). We show empirical results for zero-shot predictions on standard benchmark datasets, namely, aPY, AwA2, SUN and CUB datasets. We further introduce to the research community, a new experimental train-test split that maximizes target-shift to further study its effects.
Unified Semantic Parsing with Weak Supervision
Jun 12, 2019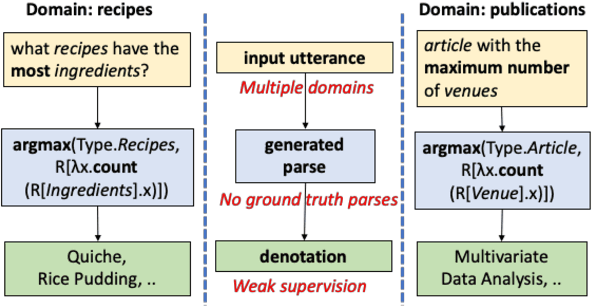
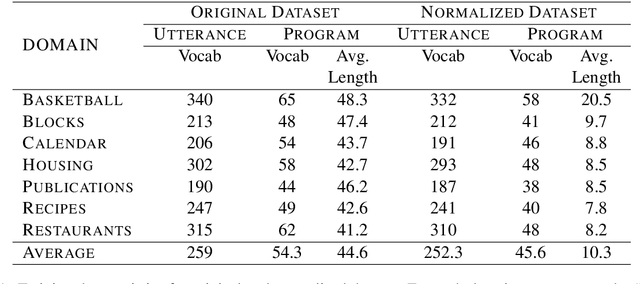

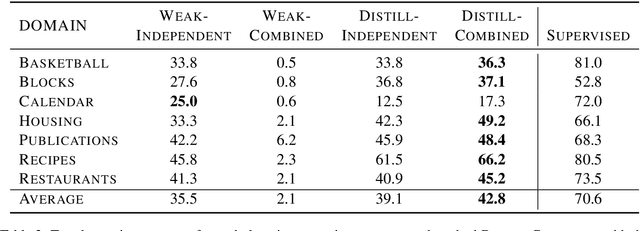
Semantic parsing over multiple knowledge bases enables a parser to exploit structural similarities of programs across the multiple domains. However, the fundamental challenge lies in obtaining high-quality annotations of (utterance, program) pairs across various domains needed for training such models. To overcome this, we propose a novel framework to build a unified multi-domain enabled semantic parser trained only with weak supervision (denotations). Weakly supervised training is particularly arduous as the program search space grows exponentially in a multi-domain setting. To solve this, we incorporate a multi-policy distillation mechanism in which we first train domain-specific semantic parsers (teachers) using weak supervision in the absence of the ground truth programs, followed by training a single unified parser (student) from the domain specific policies obtained from these teachers. The resultant semantic parser is not only compact but also generalizes better, and generates more accurate programs. It further does not require the user to provide a domain label while querying. On the standard Overnight dataset (containing multiple domains), we demonstrate that the proposed model improves performance by 20% in terms of denotation accuracy in comparison to baseline techniques.
On Controllable Sparse Alternatives to Softmax
Oct 30, 2018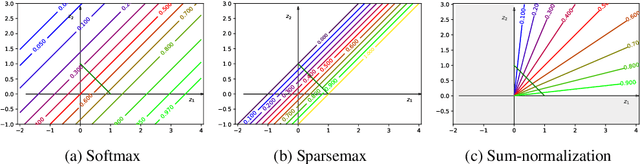
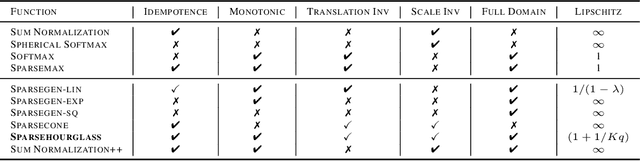
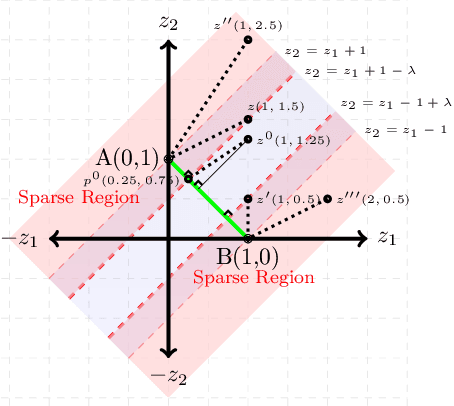
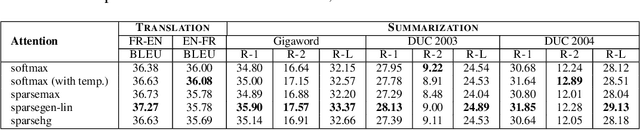
Converting an n-dimensional vector to a probability distribution over n objects is a commonly used component in many machine learning tasks like multiclass classification, multilabel classification, attention mechanisms etc. For this, several probability mapping functions have been proposed and employed in literature such as softmax, sum-normalization, spherical softmax, and sparsemax, but there is very little understanding in terms how they relate with each other. Further, none of the above formulations offer an explicit control over the degree of sparsity. To address this, we develop a unified framework that encompasses all these formulations as special cases. This framework ensures simple closed-form solutions and existence of sub-gradients suitable for learning via backpropagation. Within this framework, we propose two novel sparse formulations, sparsegen-lin and sparsehourglass, that seek to provide a control over the degree of desired sparsity. We further develop novel convex loss functions that help induce the behavior of aforementioned formulations in the multilabel classification setting, showing improved performance. We also demonstrate empirically that the proposed formulations, when used to compute attention weights, achieve better or comparable performance on standard seq2seq tasks like neural machine translation and abstractive summarization.
Unsupervised Neural Text Simplification
Oct 18, 2018
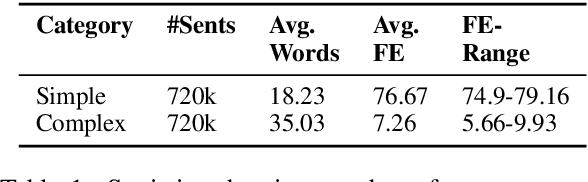
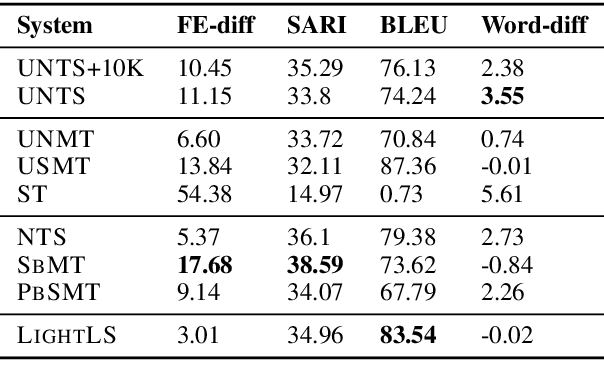
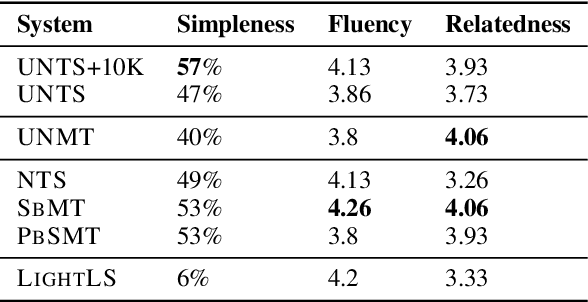
The paper presents a first attempt towards unsupervised neural text simplification that relies only on unlabeled text corpora. The core framework is comprised of a shared encoder and a pair of attentional-decoders that gains knowledge of both text simplification and complexification through discriminator-based-losses, back-translation and denoising. The framework is trained using unlabeled text collected from en-Wikipedia dump. Our analysis (both quantitative and qualitative involving human evaluators) on a public test data shows the efficacy of our model to perform simplification at both lexical and syntactic levels, competitive to existing supervised methods. We open source our implementation for academic use.