 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-End Table Question Answering via Retrieval-Augmented Generation
Mar 30, 2022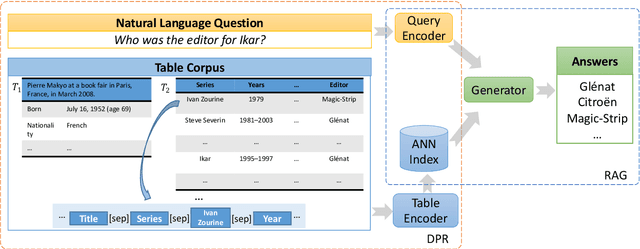
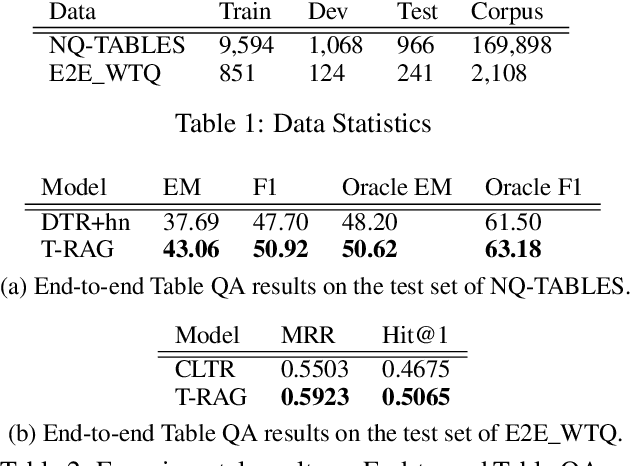
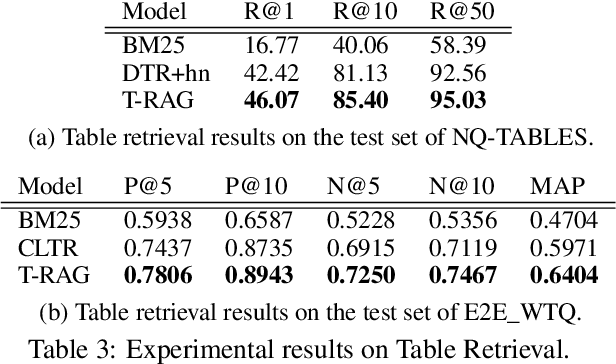
Most existing end-to-end Table Question Answering (Table QA) models consist of a two-stage framework with a retriever to select relevant table candidates from a corpus and a reader to locate the correct answers from table candidates. Even though the accuracy of the reader models is significantly improved with the recent transformer-based approaches, the overall performance of such frameworks still suffers from the poor accuracy of using traditional information retrieval techniques as retrievers. To alleviate this problem, we introduce T-RAG, an end-to-end Table QA model, where a non-parametric dense vector index is fine-tuned jointly with BART, a parametric sequence-to-sequence model to generate answer tokens. Given any natural language question, T-RAG utilizes a unified pipeline to automatically search through a table corpus to directly locate the correct answer from the table cells. We apply T-RAG to recent open-domain Table QA benchmarks and demonstrate that the fine-tuned T-RAG model is able to achieve state-of-the-art performance in both the end-to-end Table QA and the table retrieval tasks.
AIT-QA: Question Answering Dataset over Complex Tables in the Airline Industry
Jun 24, 2021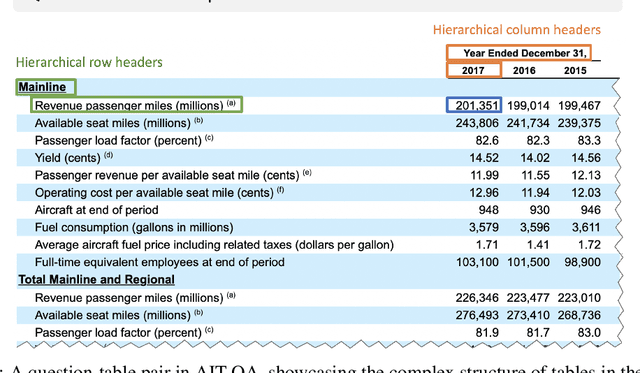

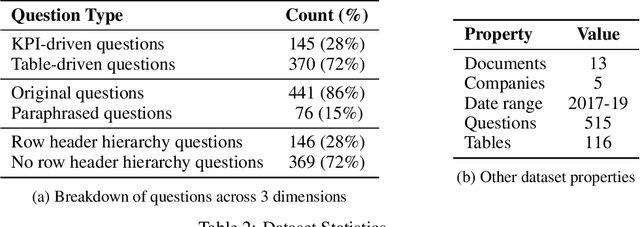

Recent advances in transformers have enabled Table Question Answering (Table QA) systems to achieve high accuracy and SOTA results on open domain datasets like WikiTableQuestions and WikiSQL. Such transformers are frequently pre-trained on open-domain content such as Wikipedia, where they effectively encode questions and corresponding tables from Wikipedia as seen in Table QA dataset. However, web tables in Wikipedia are notably flat in their layout, with the first row as the sole column header. The layout lends to a relational view of tables where each row is a tuple. Whereas, tables in domain-specific business or scientific documents often have a much more complex layout, including hierarchical row and column headers, in addition to having specialized vocabulary terms from that domain. To address this problem, we introduce the domain-specific Table QA dataset AIT-QA (Airline Industry Table QA). The dataset consists of 515 questions authored by human annotators on 116 tables extracted from public U.S. SEC filings (publicly available at: https://www.sec.gov/edgar.shtml) of major airline companies for the fiscal years 2017-2019. We also provide annotations pertaining to the nature of questions, marking those that require hierarchical headers, domain-specific terminology, and paraphrased forms. Our zero-shot baseline evaluation of three transformer-based SOTA Table QA methods - TaPAS (end-to-end), TaBERT (semantic parsing-based), and RCI (row-column encoding-based) - clearly exposes the limitation of these methods in this practical setting, with the best accuracy at just 51.8\% (RCI). We also present pragmatic table preprocessing steps used to pivot and project these complex tables into a layout suitable for the SOTA Table QA models.
CLTR: An End-to-End, Transformer-Based System for Cell Level Table Retrieval and Table Question Answering
Jun 09, 2021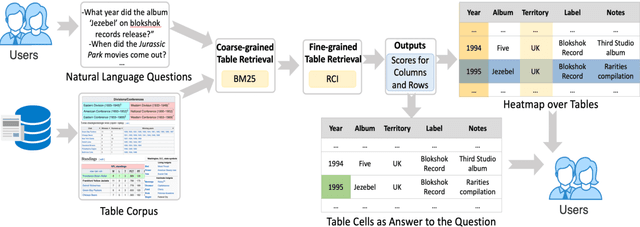
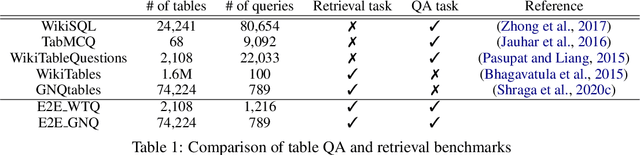
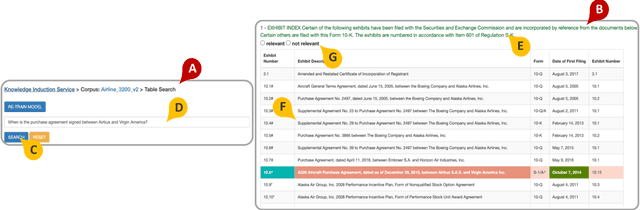

We present the first end-to-end, transformer-based table question answering (QA) system that takes natural language questions and massive table corpus as inputs to retrieve the most relevant tables and locate the correct table cells to answer the question. Our system, CLTR, extends the current state-of-the-art QA over tables model to build an end-to-end table QA architecture. This system has successfully tackled many real-world table QA problems with a simple, unified pipeline. Our proposed system can also generate a heatmap of candidate columns and rows over complex tables and allow users to quickly identify the correct cells to answer questions. In addition, we introduce two new open-domain benchmarks, E2E_WTQ and E2E_GNQ, consisting of 2,005 natural language questions over 76,242 tables. The benchmarks are designed to validate CLTR as well as accommodate future table retrieval and end-to-end table QA research and experiments. Our experiments demonstrate that our system is the current state-of-the-art model on the table retrieval task and produces promising results for end-to-end table QA.
Capturing Row and Column Semantics in Transformer Based Question Answering over Tables
Apr 26, 2021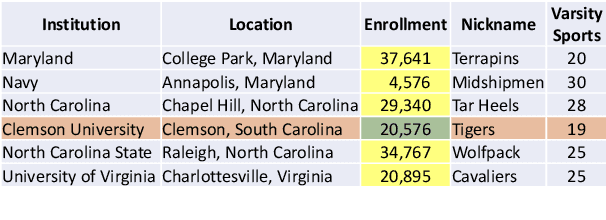
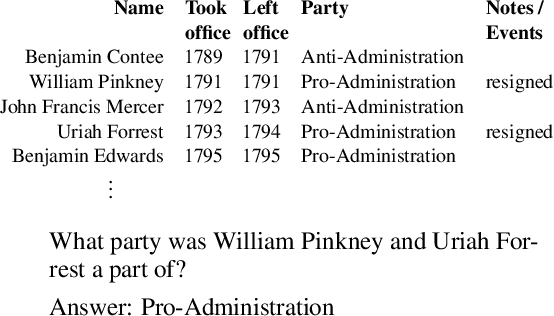
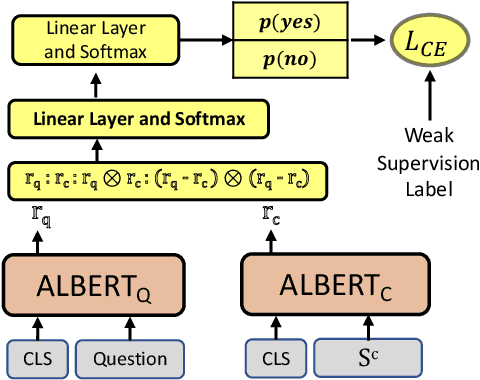
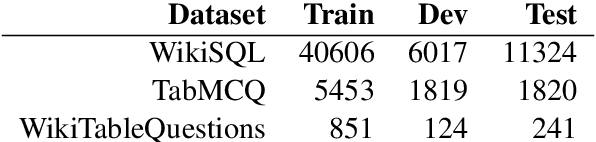
Transformer based architectures are recently used for the task of answering questions over tables. In order to improve the accuracy on this task, specialized pre-training techniques have been developed and applied on millions of open-domain web tables. In this paper, we propose two novel approaches demonstrating that one can achieve superior performance on table QA task without even using any of these specialized pre-training techniques. The first model, called RCI interaction, leverages a transformer based architecture that independently classifies rows and columns to identify relevant cells. While this model yields extremely high accuracy at finding cell values on recent benchmarks, a second model we propose, called RCI representation, provides a significant efficiency advantage for online QA systems over tables by materializing embeddings for existing tables. Experiments on recent benchmarks prove that the proposed methods can effectively locate cell values on tables (up to ~98% Hit@1 accuracy on WikiSQL lookup questions). Also, the interaction model outperforms the state-of-the-art transformer based approaches, pre-trained on very large table corpora (TAPAS and TaBERT), achieving ~3.4% and ~18.86% additional precision improvement on the standard WikiSQL benchmark.