 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Instance Training for Question Answering Across Table and Linked Text
Dec 14, 2021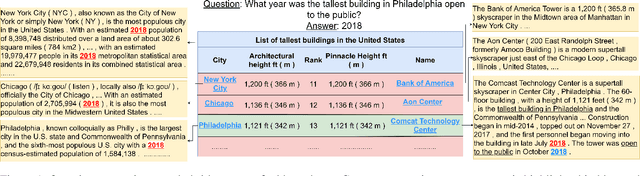
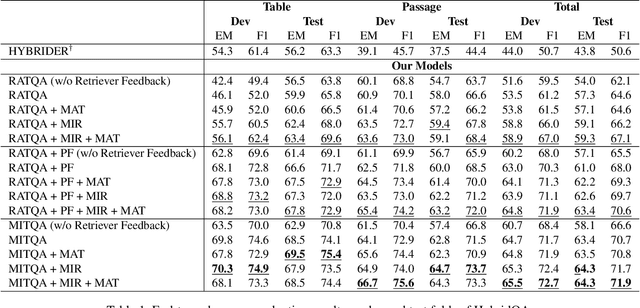
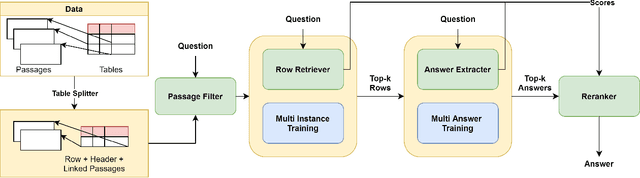

Answering natural language questions using information from tables (TableQA) is of considerable recent interest. In many applications, tables occur not in isolation, but embedded in, or linked to unstructured text. Often, a question is best answered by matching its parts to either table cell contents or unstructured text spans, and extracting answers from either source. This leads to a new space of TextTableQA problems that was introduced by the HybridQA dataset. Existing adaptations of table representation to transformer-based reading comprehension (RC) architectures fail to tackle the diverse modalities of the two representations through a single system. Training such systems is further challenged by the need for distant supervision. To reduce cognitive burden, training instances usually include just the question and answer, the latter matching multiple table rows and text passages. This leads to a noisy multi-instance training regime involving not only rows of the table, but also spans of linked text. We respond to these challenges by proposing MITQA, a new TextTableQA system that explicitly models the different but closely-related probability spaces of table row selection and text span selection. Our experiments indicate the superiority of our approach compared to recent baselines. The proposed method is currently at the top of the HybridQA leaderboard with a held out test set, achieving 21 % absolute improvement on both EM and F1 scores over previous published results.
Let the CAT out of the bag: Contrastive Attributed explanations for Text
Sep 16, 2021
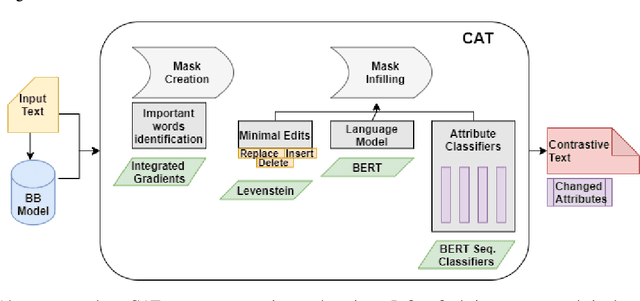
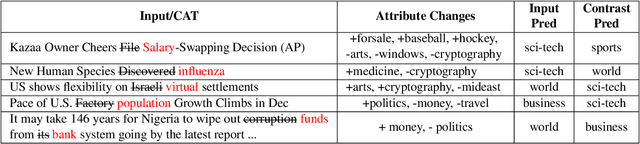
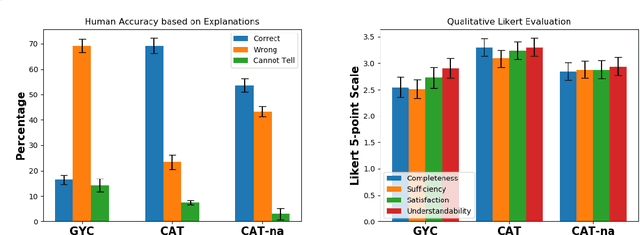
Contrastive explanations for understanding the behavior of black box models has gained a lot of attention recently as they provide potential for recourse. In this paper, we propose a method Contrastive Attributed explanations for Text (CAT) which provides contrastive explanations for natural language text data with a novel twist as we build and exploit attribute classifiers leading to more semantically meaningful explanations. To ensure that our contrastive generated text has the fewest possible edits with respect to the original text, while also being fluent and close to a human generated contrastive, we resort to a minimal perturbation approach regularized using a BERT language model and attribute classifiers trained on available attributes. We show through qualitative examples and a user study that our method not only conveys more insight because of these attributes, but also leads to better quality (contrastive) text. Moreover, quantitatively we show that our method is more efficient than other state-of-the-art methods with it also scoring higher on benchmark metrics such as flip rate, (normalized) Levenstein distance, fluency and content preservation.
Representation based meta-learning for few-shot spoken intent recognition
Jun 29, 2021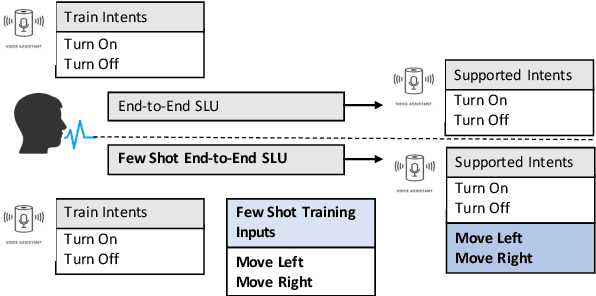
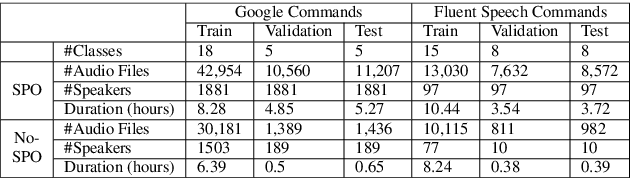
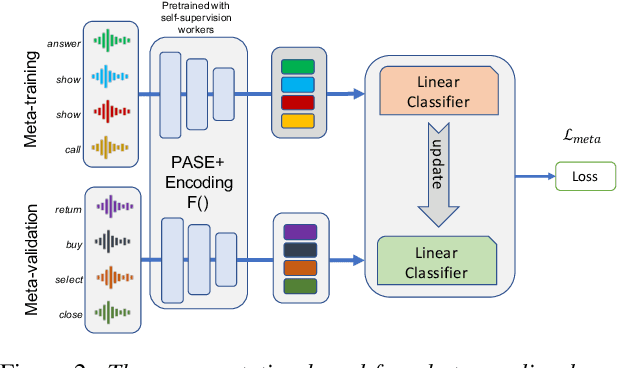
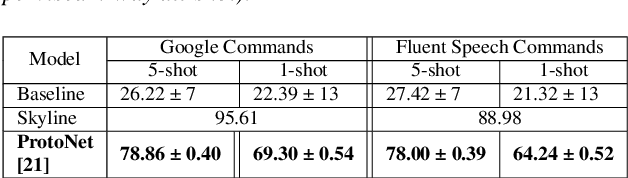
Spoken intent detection has become a popular approach to interface with various smart devices with ease. However, such systems are limited to the preset list of intents-terms or commands, which restricts the quick customization of personal devices to new intents. This paper presents a few-shot spoken intent classification approach with task-agnostic representations via meta-learning paradigm. Specifically, we leverage the popular representation-based meta-learning learning to build a task-agnostic representation of utterances, that then use a linear classifier for prediction. We evaluate three such approaches on our novel experimental protocol developed on two popular spoken intent classification datasets: Google Commands and the Fluent Speech Commands dataset. For a 5-shot (1-shot) classification of novel classes, the proposed framework provides an average classification accuracy of 88.6% (76.3%) on the Google Commands dataset, and 78.5% (64.2%) on the Fluent Speech Commands dataset. The performance is comparable to traditionally supervised classification models with abundant training samples.
AIT-QA: Question Answering Dataset over Complex Tables in the Airline Industry
Jun 24, 2021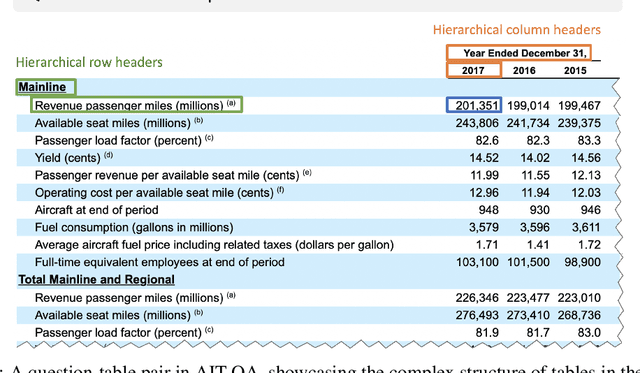

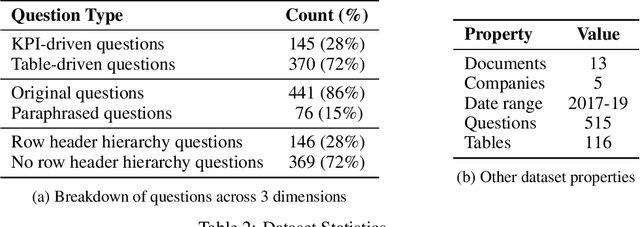

Recent advances in transformers have enabled Table Question Answering (Table QA) systems to achieve high accuracy and SOTA results on open domain datasets like WikiTableQuestions and WikiSQL. Such transformers are frequently pre-trained on open-domain content such as Wikipedia, where they effectively encode questions and corresponding tables from Wikipedia as seen in Table QA dataset. However, web tables in Wikipedia are notably flat in their layout, with the first row as the sole column header. The layout lends to a relational view of tables where each row is a tuple. Whereas, tables in domain-specific business or scientific documents often have a much more complex layout, including hierarchical row and column headers, in addition to having specialized vocabulary terms from that domain. To address this problem, we introduce the domain-specific Table QA dataset AIT-QA (Airline Industry Table QA). The dataset consists of 515 questions authored by human annotators on 116 tables extracted from public U.S. SEC filings (publicly available at: https://www.sec.gov/edgar.shtml) of major airline companies for the fiscal years 2017-2019. We also provide annotations pertaining to the nature of questions, marking those that require hierarchical headers, domain-specific terminology, and paraphrased forms. Our zero-shot baseline evaluation of three transformer-based SOTA Table QA methods - TaPAS (end-to-end), TaBERT (semantic parsing-based), and RCI (row-column encoding-based) - clearly exposes the limitation of these methods in this practical setting, with the best accuracy at just 51.8\% (RCI). We also present pragmatic table preprocessing steps used to pivot and project these complex tables into a layout suitable for the SOTA Table QA models.
Capturing Row and Column Semantics in Transformer Based Question Answering over Tables
Apr 26, 2021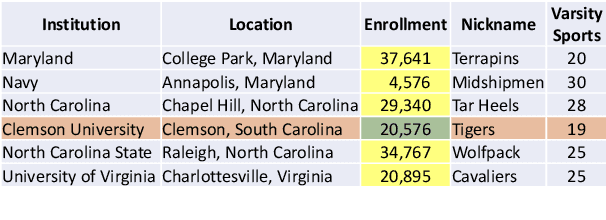
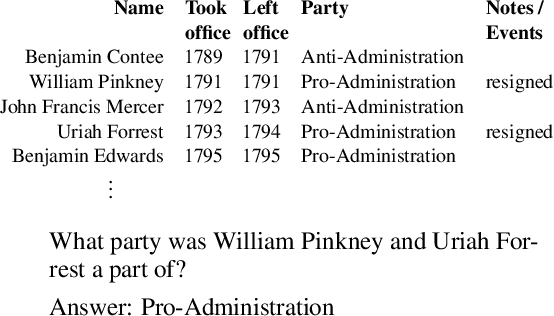
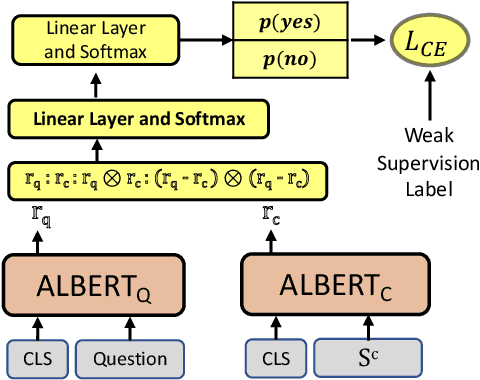
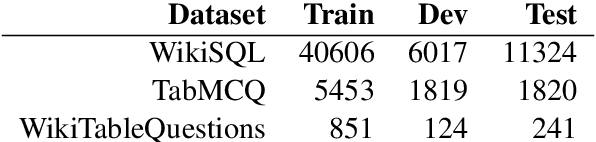
Transformer based architectures are recently used for the task of answering questions over tables. In order to improve the accuracy on this task, specialized pre-training techniques have been developed and applied on millions of open-domain web tables. In this paper, we propose two novel approaches demonstrating that one can achieve superior performance on table QA task without even using any of these specialized pre-training techniques. The first model, called RCI interaction, leverages a transformer based architecture that independently classifies rows and columns to identify relevant cells. While this model yields extremely high accuracy at finding cell values on recent benchmarks, a second model we propose, called RCI representation, provides a significant efficiency advantage for online QA systems over tables by materializing embeddings for existing tables. Experiments on recent benchmarks prove that the proposed methods can effectively locate cell values on tables (up to ~98% Hit@1 accuracy on WikiSQL lookup questions). Also, the interaction model outperforms the state-of-the-art transformer based approaches, pre-trained on very large table corpora (TAPAS and TaBERT), achieving ~3.4% and ~18.86% additional precision improvement on the standard WikiSQL benchmark.