 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisualLens: Personalization through Visual History
Nov 25, 2024

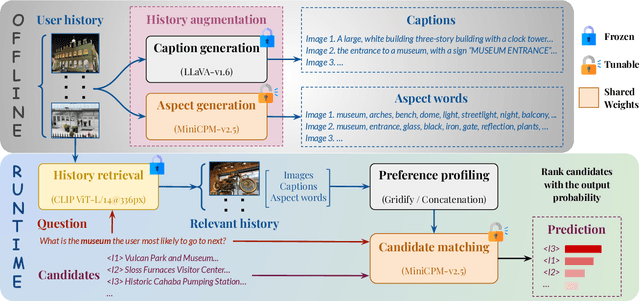
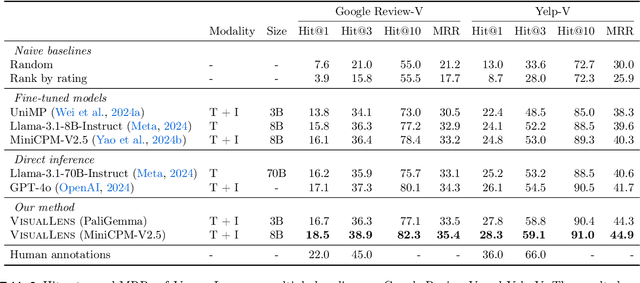
We hypothesize that a user's visual history with images reflecting their daily life, offers valuable insights into their interests and preferences, and can be leveraged for personalization. Among the many challenges to achieve this goal, the foremost is the diversity and noises in the visual history, containing images not necessarily related to a recommendation task, not necessarily reflecting the user's interest, or even not necessarily preference-relevant. Existing recommendation systems either rely on task-specific user interaction logs, such as online shopping history for shopping recommendations, or focus on text signals. We propose a novel approach, VisualLens, that extracts, filters, and refines image representations, and leverages these signals for personalization. We created two new benchmarks with task-agnostic visual histories, and show that our method improves over state-of-the-art recommendations by 5-10% on Hit@3, and improves over GPT-4o by 2-5%. Our approach paves the way for personalized recommendations in scenarios where traditional methods fail.
End-to-End Table Question Answering via Retrieval-Augmented Generation
Mar 30, 2022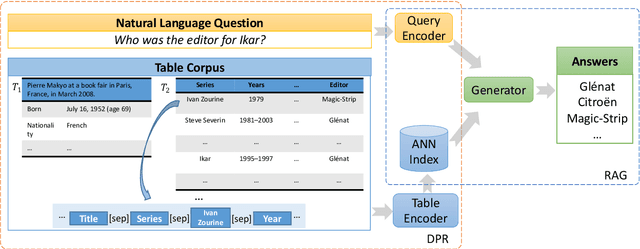
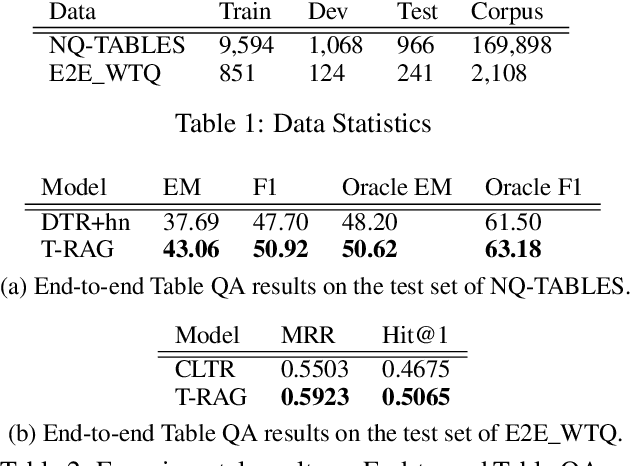
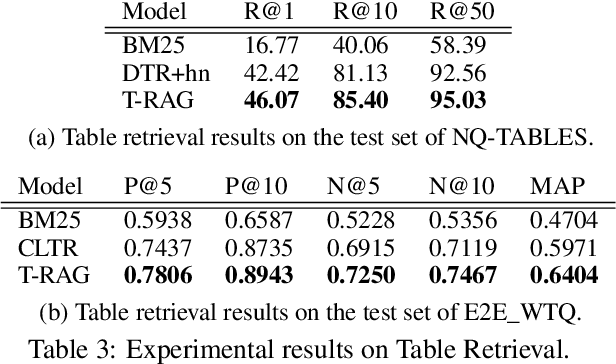
Most existing end-to-end Table Question Answering (Table QA) models consist of a two-stage framework with a retriever to select relevant table candidates from a corpus and a reader to locate the correct answers from table candidates. Even though the accuracy of the reader models is significantly improved with the recent transformer-based approaches, the overall performance of such frameworks still suffers from the poor accuracy of using traditional information retrieval techniques as retrievers. To alleviate this problem, we introduce T-RAG, an end-to-end Table QA model, where a non-parametric dense vector index is fine-tuned jointly with BART, a parametric sequence-to-sequence model to generate answer tokens. Given any natural language question, T-RAG utilizes a unified pipeline to automatically search through a table corpus to directly locate the correct answer from the table cells. We apply T-RAG to recent open-domain Table QA benchmarks and demonstrate that the fine-tuned T-RAG model is able to achieve state-of-the-art performance in both the end-to-end Table QA and the table retrieval tasks.
Topic Transferable Table Question Answering
Sep 15, 2021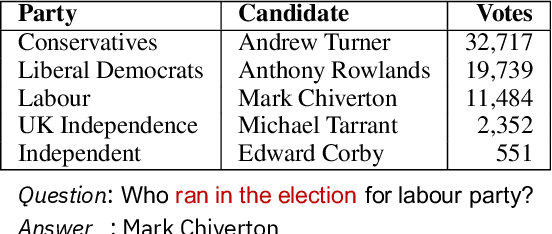
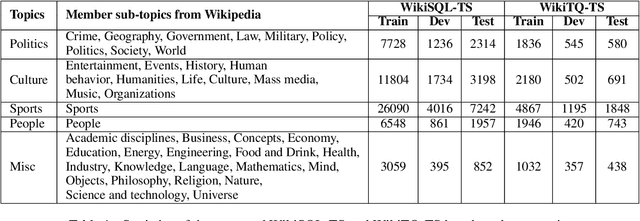
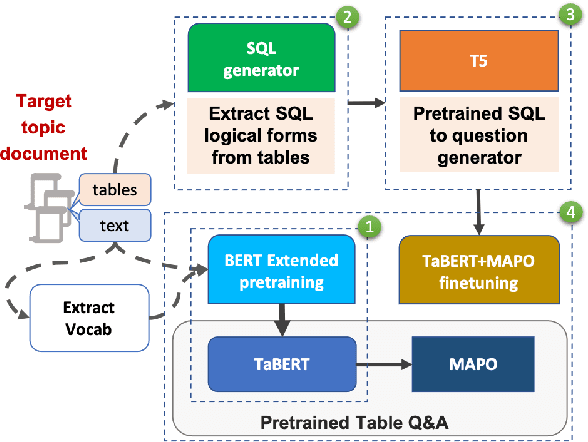
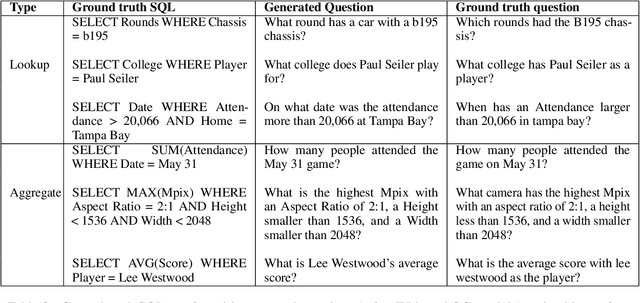
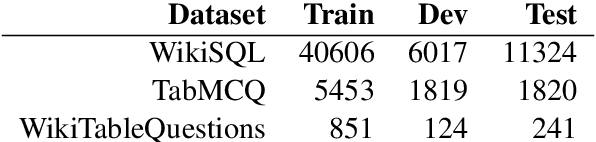
Weakly-supervised table question-answering(TableQA) models have achieved state-of-art performance by using pre-trained BERT transformer to jointly encoding a question and a table to produce structured query for the question. However, in practical settings TableQA systems are deployed over table corpora having topic and word distributions quite distinct from BERT's pretraining corpus. In this work we simulate the practical topic shift scenario by designing novel challenge benchmarks WikiSQL-TS and WikiTQ-TS, consisting of train-dev-test splits in five distinct topic groups, based on the popular WikiSQL and WikiTableQuestions datasets. We empirically show that, despite pre-training on large open-domain text, performance of models degrades significantly when they are evaluated on unseen topics. In response, we propose T3QA (Topic Transferable Table Question Answering) a pragmatic adaptation framework for TableQA comprising of: (1) topic-specific vocabulary injection into BERT, (2) a novel text-to-text transformer generator (such as T5, GPT2) based natural language question generation pipeline focused on generating topic specific training data, and (3) a logical form reranker. We show that T3QA provides a reasonably good baseline for our topic shift benchmarks. We believe our topic split benchmarks will lead to robust TableQA solutions that are better suited for practical deployment.
AIT-QA: Question Answering Dataset over Complex Tables in the Airline Industry
Jun 24, 2021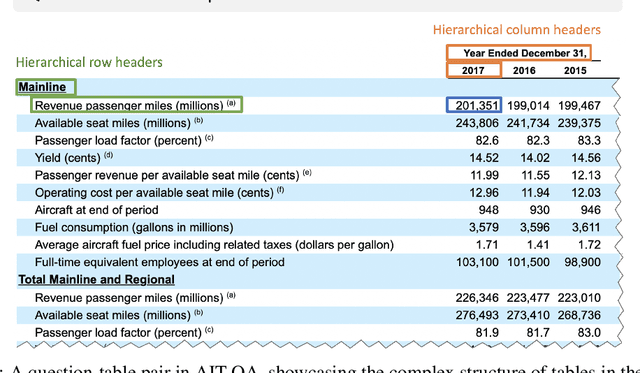

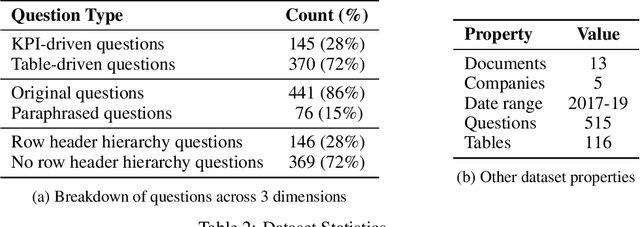

Recent advances in transformers have enabled Table Question Answering (Table QA) systems to achieve high accuracy and SOTA results on open domain datasets like WikiTableQuestions and WikiSQL. Such transformers are frequently pre-trained on open-domain content such as Wikipedia, where they effectively encode questions and corresponding tables from Wikipedia as seen in Table QA dataset. However, web tables in Wikipedia are notably flat in their layout, with the first row as the sole column header. The layout lends to a relational view of tables where each row is a tuple. Whereas, tables in domain-specific business or scientific documents often have a much more complex layout, including hierarchical row and column headers, in addition to having specialized vocabulary terms from that domain. To address this problem, we introduce the domain-specific Table QA dataset AIT-QA (Airline Industry Table QA). The dataset consists of 515 questions authored by human annotators on 116 tables extracted from public U.S. SEC filings (publicly available at: https://www.sec.gov/edgar.shtml) of major airline companies for the fiscal years 2017-2019. We also provide annotations pertaining to the nature of questions, marking those that require hierarchical headers, domain-specific terminology, and paraphrased forms. Our zero-shot baseline evaluation of three transformer-based SOTA Table QA methods - TaPAS (end-to-end), TaBERT (semantic parsing-based), and RCI (row-column encoding-based) - clearly exposes the limitation of these methods in this practical setting, with the best accuracy at just 51.8\% (RCI). We also present pragmatic table preprocessing steps used to pivot and project these complex tables into a layout suitable for the SOTA Table QA models.
CLTR: An End-to-End, Transformer-Based System for Cell Level Table Retrieval and Table Question Answering
Jun 09, 2021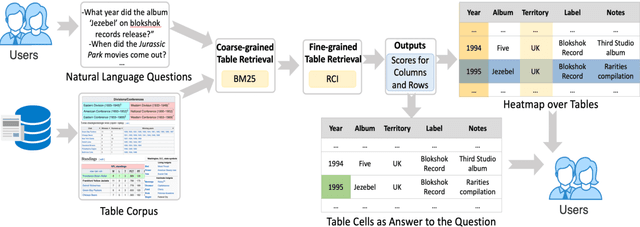
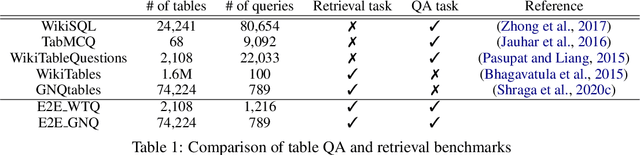
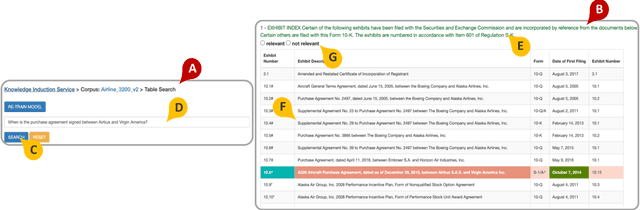

We present the first end-to-end, transformer-based table question answering (QA) system that takes natural language questions and massive table corpus as inputs to retrieve the most relevant tables and locate the correct table cells to answer the question. Our system, CLTR, extends the current state-of-the-art QA over tables model to build an end-to-end table QA architecture. This system has successfully tackled many real-world table QA problems with a simple, unified pipeline. Our proposed system can also generate a heatmap of candidate columns and rows over complex tables and allow users to quickly identify the correct cells to answer questions. In addition, we introduce two new open-domain benchmarks, E2E_WTQ and E2E_GNQ, consisting of 2,005 natural language questions over 76,242 tables. The benchmarks are designed to validate CLTR as well as accommodate future table retrieval and end-to-end table QA research and experiments. Our experiments demonstrate that our system is the current state-of-the-art model on the table retrieval task and produces promising results for end-to-end table QA.
Capturing Row and Column Semantics in Transformer Based Question Answering over Tables
Apr 26, 2021
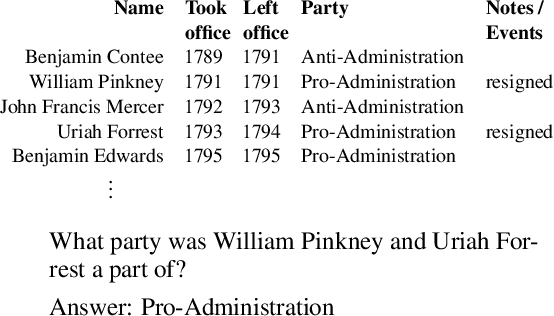
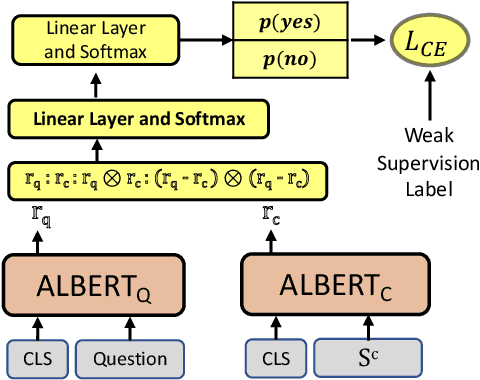
Transformer based architectures are recently used for the task of answering questions over tables. In order to improve the accuracy on this task, specialized pre-training techniques have been developed and applied on millions of open-domain web tables. In this paper, we propose two novel approaches demonstrating that one can achieve superior performance on table QA task without even using any of these specialized pre-training techniques. The first model, called RCI interaction, leverages a transformer based architecture that independently classifies rows and columns to identify relevant cells. While this model yields extremely high accuracy at finding cell values on recent benchmarks, a second model we propose, called RCI representation, provides a significant efficiency advantage for online QA systems over tables by materializing embeddings for existing tables. Experiments on recent benchmarks prove that the proposed methods can effectively locate cell values on tables (up to ~98% Hit@1 accuracy on WikiSQL lookup questions). Also, the interaction model outperforms the state-of-the-art transformer based approaches, pre-trained on very large table corpora (TAPAS and TaBERT), achieving ~3.4% and ~18.86% additional precision improvement on the standard WikiSQL benchmark.
Type Prediction Systems
Apr 02, 2021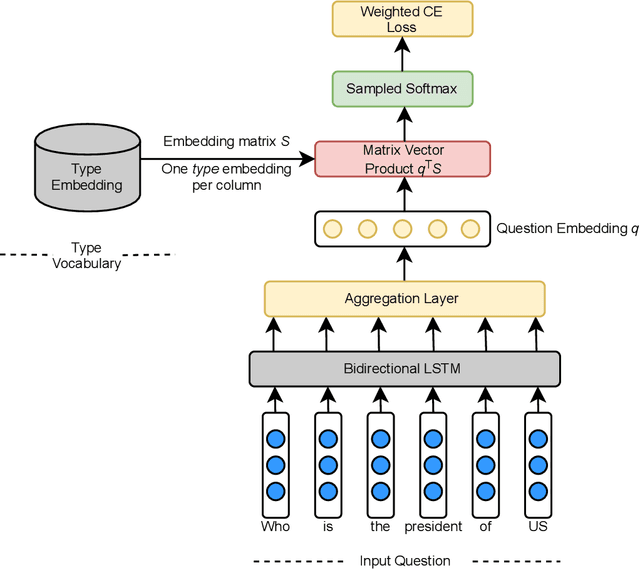
Inferring semantic types for entity mentions within text documents is an important asset for many downstream NLP tasks, such as Semantic Role Labelling, Entity Disambiguation, Knowledge Base Question Answering, etc. Prior works have mostly focused on supervised solutions that generally operate on relatively small-to-medium-sized type systems. In this work, we describe two systems aimed at predicting type information for the following two tasks, namely, a TypeSuggest module, an unsupervised system designed to predict types for a set of user-entered query terms, and an Answer Type prediction module, that provides a solution for the task of determining the correct type of the answer expected to a given query. Our systems generalize to arbitrary type systems of any sizes, thereby making it a highly appealing solution to extract type information at any granularity.
Schemaless Queries over Document Tables with Dependencies
Nov 21, 2019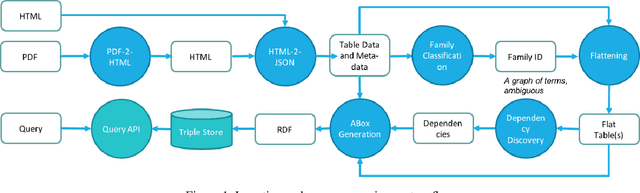
Unstructured enterprise data such as reports, manuals and guidelines often contain tables. The traditional way of integrating data from these tables is through a two-step process of table detection/extraction and mapping the table layouts to an appropriate schema. This can be an expensive process. In this paper we show that by using semantic technologies (RDF/SPARQL and database dependencies) paired with a simple but powerful way to transform tables with non-relational layouts, it is possible to offer query answering services over these tables with minimal manual work or domain-specific mappings. Our method enables users to exploit data in tables embedded in documents with little effort, not only for simple retrieval queries, but also for structured queries that require joining multiple interrelated tables.
Populating Web Scale Knowledge Graphs using Distantly Supervised Relation Extraction and Validation
Sep 11, 2019


In this paper, we propose a fully automated system to extend knowledge graphs using external information from web-scale corpora. The designed system leverages a deep learning based technology for relation extraction that can be trained by a distantly supervised approach. In addition to that, the system uses a deep learning approach for knowledge base completion by utilizing the global structure information of the induced KG to further refine the confidence of the newly discovered relations. The designed system does not require any effort for adaptation to new languages and domains as it does not use any hand-labeled data, NLP analytics and inference rules. Our experiments, performed on a popular academic benchmark demonstrate that the suggested system boosts the performance of relation extraction by a wide margin, reporting error reductions of 50%, resulting in relative improvement of up to 100%. Also, a web-scale experiment conducted to extend DBPedia with knowledge from Common Crawl shows that our system is not only scalable but also does not require any adaptation cost, while yielding substantial accuracy gain.
Uncheatable Machine Learning Inference
Aug 08, 2019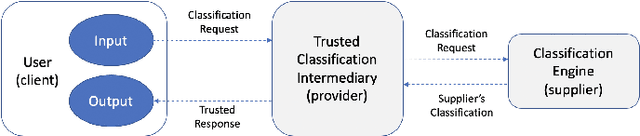
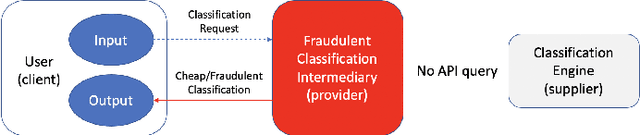
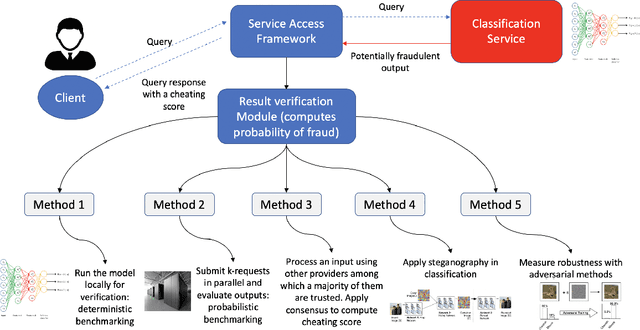
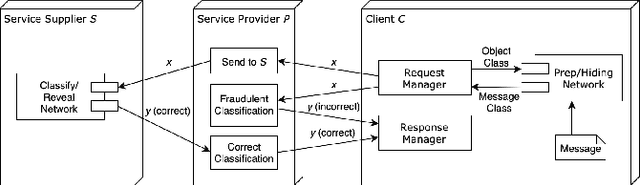
Classification-as-a-Service (CaaS) is widely deployed today in machine intelligence stacks for a vastly diverse set of applications including anything from medical prognosis to computer vision tasks to natural language processing to identity fraud detection. The computing power required for training complex models on large datasets to perform inference to solve these problems can be very resource-intensive. A CaaS provider may cheat a customer by fraudulently bypassing expensive training procedures in favor of weaker, less computationally-intensive algorithms which yield results of reduced quality. Given a classification service supplier $S$, intermediary CaaS provider $P$ claiming to use $S$ as a classification backend, and customer $C$, our work addresses the following questions: (i) how can $P$'s claim to be using $S$ be verified by $C$? (ii) how might $S$ make performance guarantees that may be verified by $C$? and (iii) how might one design a decentralized system that incentivizes service proofing and accountability? To this end, we propose a variety of methods for $C$ to evaluate the service claims made by $P$ using probabilistic performance metrics, instance seeding, and steganography. We also propose a method of measuring the robustness of a model using a blackbox adversarial procedure, which may then be used as a benchmark or comparison to a claim made by $S$. Finally, we propose the design of a smart contract-based decentralized system that incentivizes service accountability to serve as a trusted Quality of Service (QoS) auditor.