 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePopulating Web Scale Knowledge Graphs using Distantly Supervised Relation Extraction and Validation
Sep 11, 2019
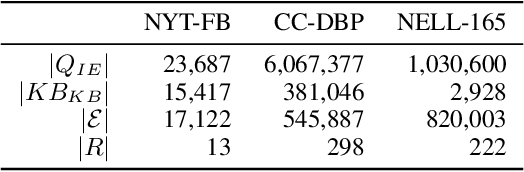


In this paper, we propose a fully automated system to extend knowledge graphs using external information from web-scale corpora. The designed system leverages a deep learning based technology for relation extraction that can be trained by a distantly supervised approach. In addition to that, the system uses a deep learning approach for knowledge base completion by utilizing the global structure information of the induced KG to further refine the confidence of the newly discovered relations. The designed system does not require any effort for adaptation to new languages and domains as it does not use any hand-labeled data, NLP analytics and inference rules. Our experiments, performed on a popular academic benchmark demonstrate that the suggested system boosts the performance of relation extraction by a wide margin, reporting error reductions of 50%, resulting in relative improvement of up to 100%. Also, a web-scale experiment conducted to extend DBPedia with knowledge from Common Crawl shows that our system is not only scalable but also does not require any adaptation cost, while yielding substantial accuracy gain.
P2L: Predicting Transfer Learning for Images and Semantic Relations
Aug 20, 2019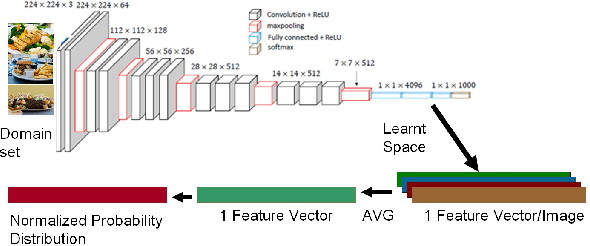

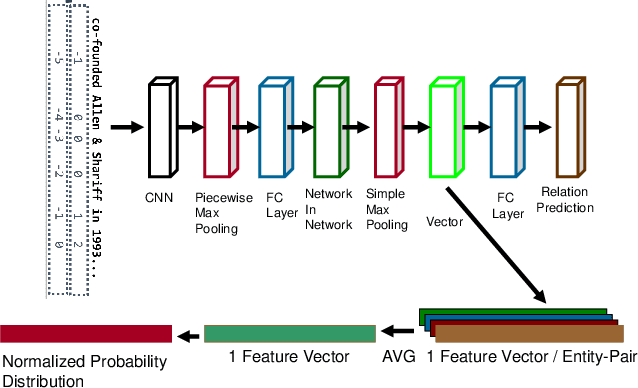
Transfer learning enhances learning across tasks, by leveraging previously learned representations -- if they are properly chosen. We describe an efficient method to accurately estimate the appropriateness of a previously trained model for use in a new learning task. We use this measure, which we call "Predict To Learn" ("P2L"), in the two very different domains of images and semantic relations, where it predicts, from a set of "source" models, the one model most likely to produce effective transfer for training a given "target" model. We validate our approach thoroughly, by assembling a collection of candidate source models, then fine-tuning each candidate to perform each of a collection of target tasks, and finally measuring how well transfer has been enhanced. Across 95 tasks within multiple domains (images classification and semantic relations), the P2L approach was able to select the best transfer learning model on average, while the heuristic of choosing model trained with the largest data set selected the best model in only 55 cases. These results suggest that P2L captures important information in common between source and target tasks, and that this shared informational structure contributes to successful transfer learning more than simple data size.
Language Independent Acquisition of Abbreviations
Sep 23, 2017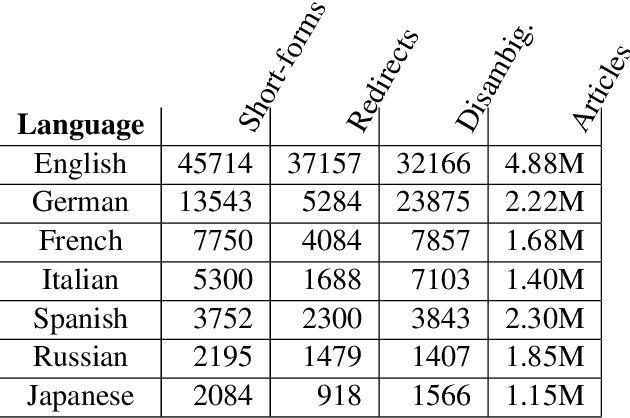
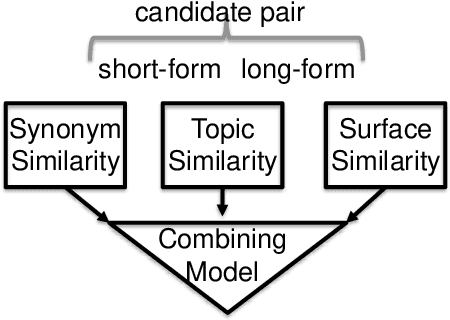
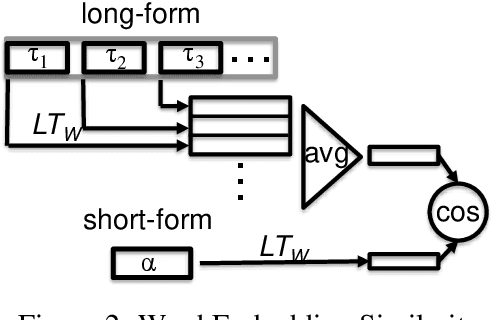
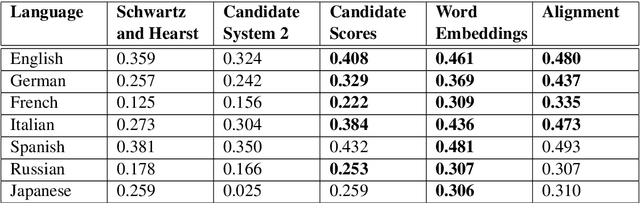
This paper addresses automatic extraction of abbreviations (encompassing acronyms and initialisms) and corresponding long-form expansions from plain unstructured text. We create and are going to release a multilingual resource for abbreviations and their corresponding expansions, built automatically by exploiting Wikipedia redirect and disambiguation pages, that can be used as a benchmark for evaluation. We address a shortcoming of previous work where only the redirect pages were used, and so every abbreviation had only a single expansion, even though multiple different expansions are possible for many of the abbreviations. We also develop a principled machine learning based approach to scoring expansion candidates using different techniques such as indicators of near synonymy, topical relatedness, and surface similarity. We show improved performance over seven languages, including two with a non-Latin alphabet, relative to strong baselines.
Applying Deep Learning to Answer Selection: A Study and An Open Task
Oct 02, 2015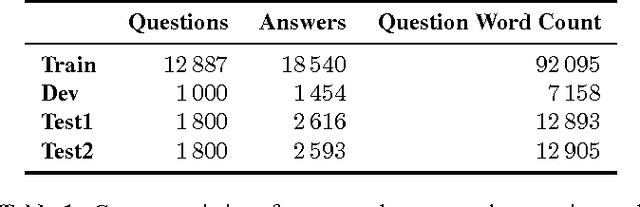
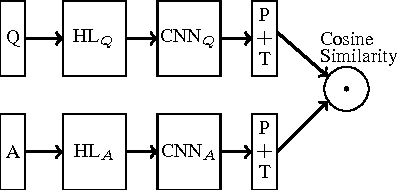
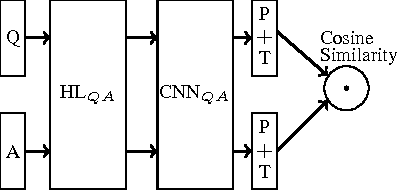
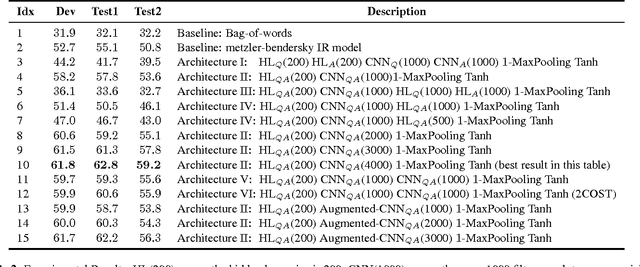
We apply a general deep learning framework to address the non-factoid question answering task. Our approach does not rely on any linguistic tools and can be applied to different languages or domains. Various architectures are presented and compared. We create and release a QA corpus and setup a new QA task in the insurance domain. Experimental results demonstrate superior performance compared to the baseline methods and various technologies give further improvements. For this highly challenging task, the top-1 accuracy can reach up to 65.3% on a test set, which indicates a great potential for practical use.