 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge Graph Induction enabling Recommending and Trend Analysis: A Corporate Research Community Use Case
Jul 18, 2022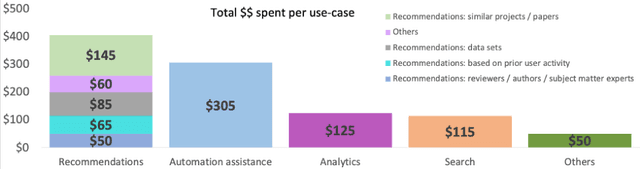

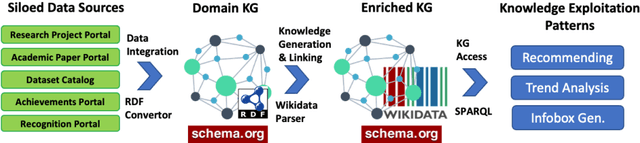
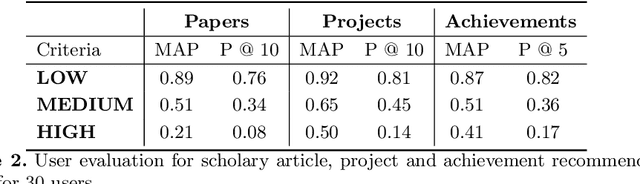
A research division plays an important role of driving innovation in an organization. Drawing insights, following trends, keeping abreast of new research, and formulating strategies are increasingly becoming more challenging for both researchers and executives as the amount of information grows in both velocity and volume. In this paper we present a use case of how a corporate research community, IBM Research, utilizes Semantic Web technologies to induce a unified Knowledge Graph from both structured and textual data obtained by integrating various applications used by the community related to research projects, academic papers, datasets, achievements and recognition. In order to make the Knowledge Graph more accessible to application developers, we identified a set of common patterns for exploiting the induced knowledge and exposed them as APIs. Those patterns were born out of user research which identified the most valuable use cases or user pain points to be alleviated. We outline two distinct scenarios: recommendation and analytics for business use. We will discuss these scenarios in detail and provide an empirical evaluation on entity recommendation specifically. The methodology used and the lessons learned from this work can be applied to other organizations facing similar challenges.
Re2G: Retrieve, Rerank, Generate
Jul 13, 2022
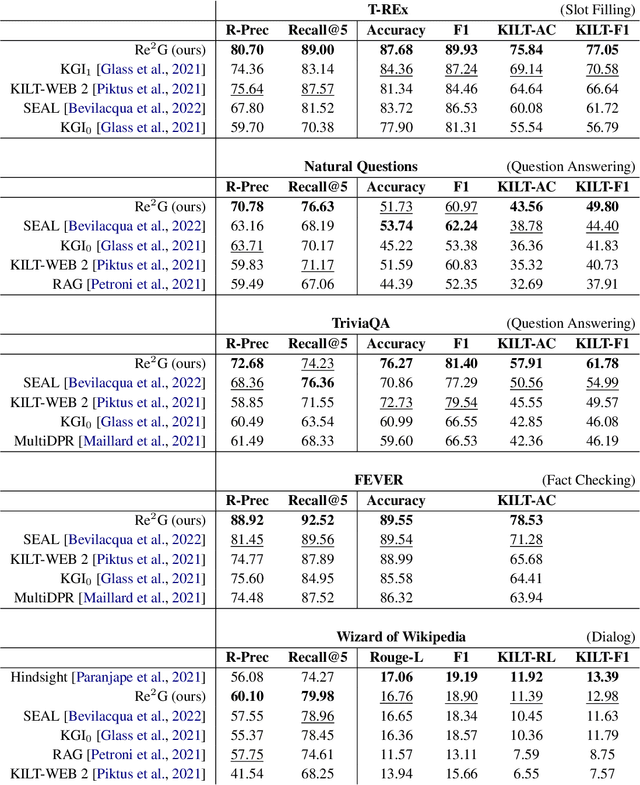
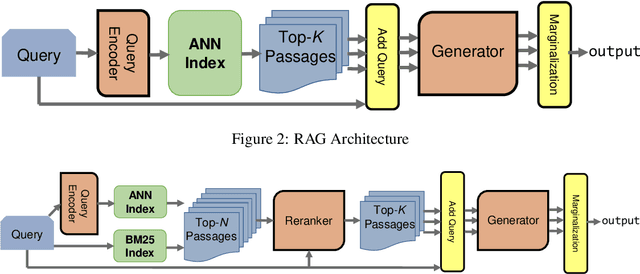
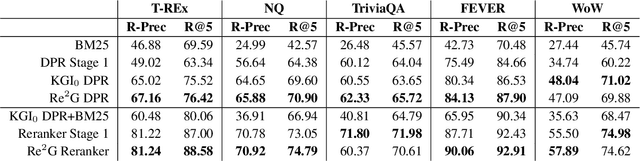
As demonstrated by GPT-3 and T5, transformers grow in capability as parameter spaces become larger and larger. However, for tasks that require a large amount of knowledge, non-parametric memory allows models to grow dramatically with a sub-linear increase in computational cost and GPU memory requirements. Recent models such as RAG and REALM have introduced retrieval into conditional generation. These models incorporate neural initial retrieval from a corpus of passages. We build on this line of research, proposing Re2G, which combines both neural initial retrieval and reranking into a BART-based sequence-to-sequence generation. Our reranking approach also permits merging retrieval results from sources with incomparable scores, enabling an ensemble of BM25 and neural initial retrieval. To train our system end-to-end, we introduce a novel variation of knowledge distillation to train the initial retrieval, reranker, and generation using only ground truth on the target sequence output. We find large gains in four diverse tasks: zero-shot slot filling, question answering, fact-checking, and dialog, with relative gains of 9% to 34% over the previous state-of-the-art on the KILT leaderboard. We make our code available as open source at https://github.com/IBM/kgi-slot-filling/tree/re2g.
KGI: An Integrated Framework for Knowledge Intensive Language Tasks
Apr 08, 2022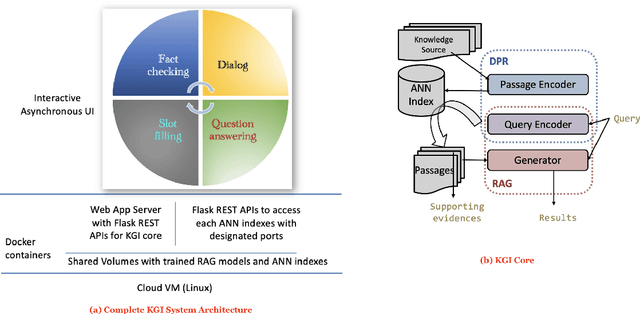
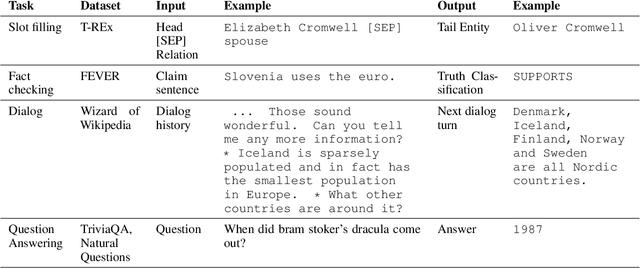
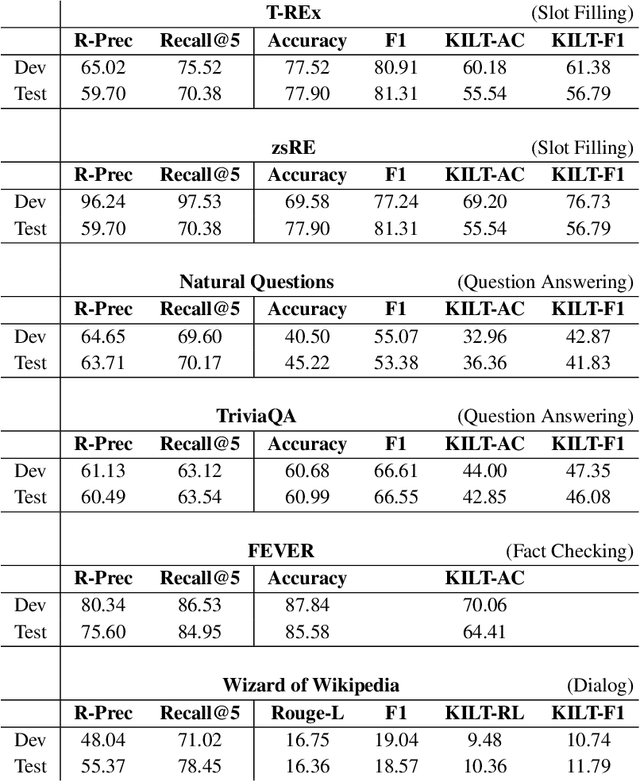
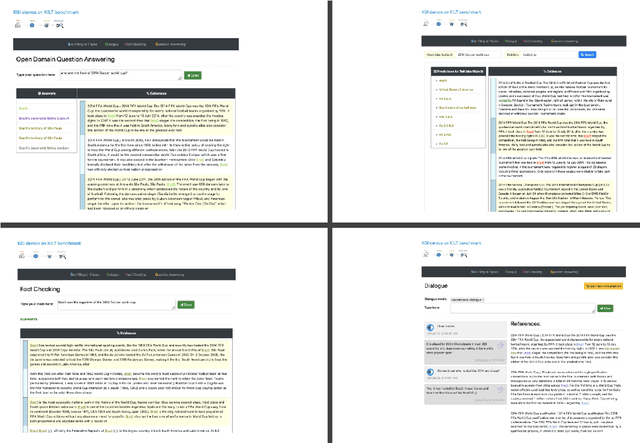
In a recent work, we presented a novel state-of-the-art approach to zero-shot slot filling that extends dense passage retrieval with hard negatives and robust training procedures for retrieval augmented generation models. In this paper, we propose a system based on an enhanced version of this approach where we train task specific models for other knowledge intensive language tasks, such as open domain question answering (QA), dialogue and fact checking. Our system achieves results comparable to the best models in the KILT leaderboards. Moreover, given a user query, we show how the output from these different models can be combined to cross-examine each other. Particularly, we show how accuracy in dialogue can be improved using the QA model. A short video demonstrating the system is available here - \url{https://ibm.box.com/v/kgi-interactive-demo} .
Applying a Generic Sequence-to-Sequence Model for Simple and Effective Keyphrase Generation
Jan 14, 2022
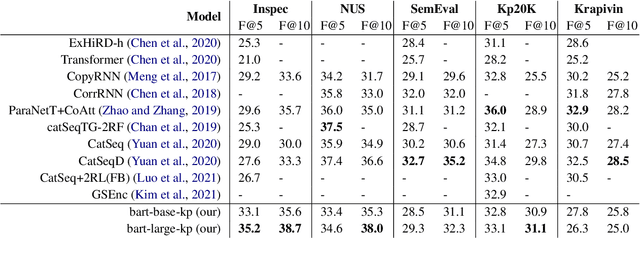
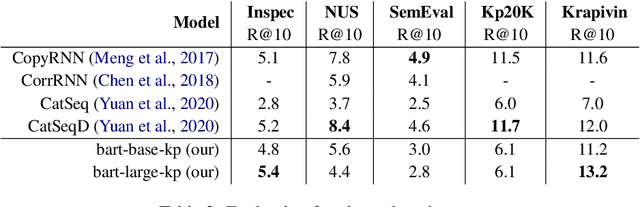
In recent years, a number of keyphrase generation (KPG) approaches were proposed consisting of complex model architectures, dedicated training paradigms and decoding strategies. In this work, we opt for simplicity and show how a commonly used seq2seq language model, BART, can be easily adapted to generate keyphrases from the text in a single batch computation using a simple training procedure. Empirical results on five benchmarks show that our approach is as good as the existing state-of-the-art KPG systems, but using a much simpler and easy to deploy framework.
Robust Retrieval Augmented Generation for Zero-shot Slot Filling
Aug 31, 2021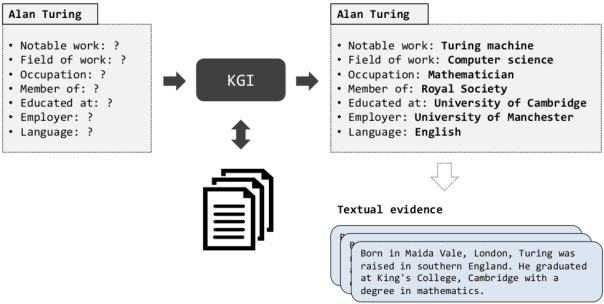
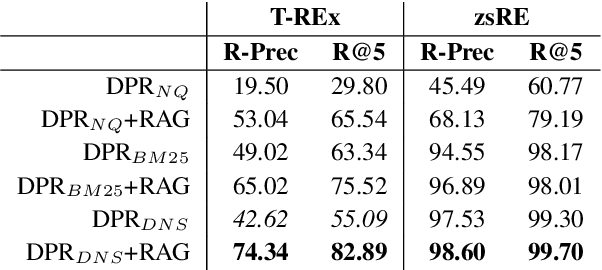
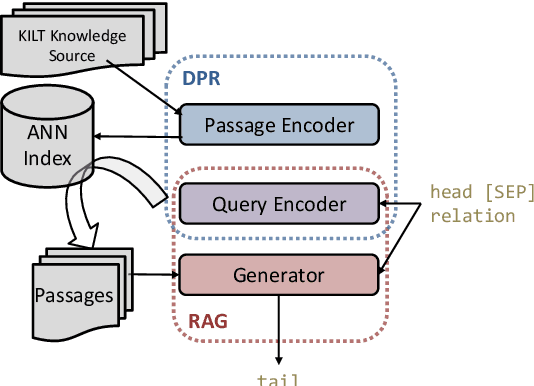
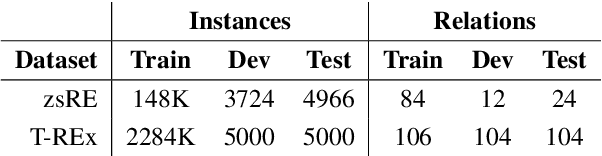
Automatically inducing high quality knowledge graphs from a given collection of documents still remains a challenging problem in AI. One way to make headway for this problem is through advancements in a related task known as slot filling. In this task, given an entity query in form of [Entity, Slot, ?], a system is asked to fill the slot by generating or extracting the missing value exploiting evidence extracted from relevant passage(s) in the given document collection. The recent works in the field try to solve this task in an end-to-end fashion using retrieval-based language models. In this paper, we present a novel approach to zero-shot slot filling that extends dense passage retrieval with hard negatives and robust training procedures for retrieval augmented generation models. Our model reports large improvements on both T-REx and zsRE slot filling datasets, improving both passage retrieval and slot value generation, and ranking at the top-1 position in the KILT leaderboard. Moreover, we demonstrate the robustness of our system showing its domain adaptation capability on a new variant of the TACRED dataset for slot filling, through a combination of zero/few-shot learning. We release the source code and pre-trained models.
Template Controllable keywords-to-text Generation
Nov 07, 2020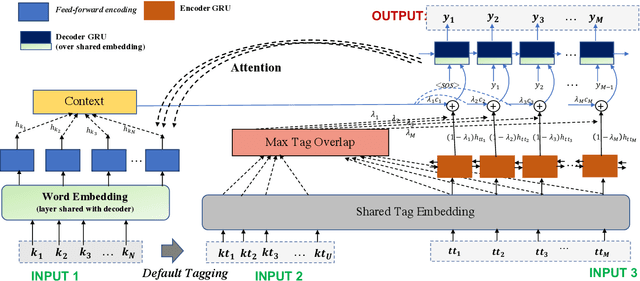
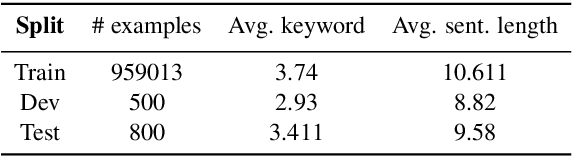
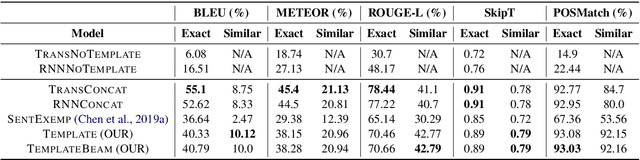
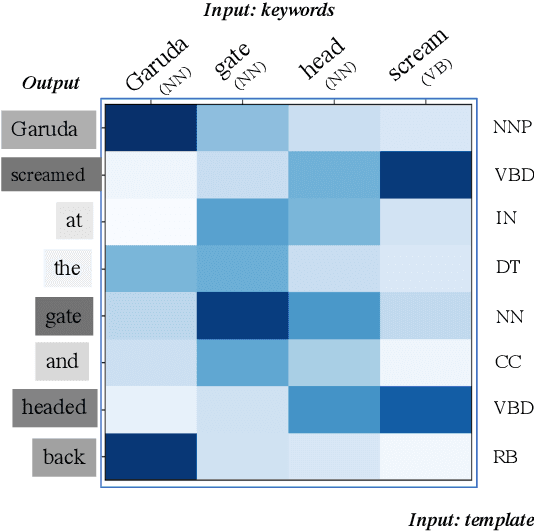
This paper proposes a novel neural model for the understudied task of generating text from keywords. The model takes as input a set of un-ordered keywords, and part-of-speech (POS) based template instructions. This makes it ideal for surface realization in any NLG setup. The framework is based on the encode-attend-decode paradigm, where keywords and templates are encoded first, and the decoder judiciously attends over the contexts derived from the encoded keywords and templates to generate the sentences. Training exploits weak supervision, as the model trains on a large amount of labeled data with keywords and POS based templates prepared through completely automatic means. Qualitative and quantitative performance analyses on publicly available test-data in various domains reveal our system's superiority over baselines, built using state-of-the-art neural machine translation and controllable transfer techniques. Our approach is indifferent to the order of input keywords.
Inducing Hypernym Relationships Based On Order Theory
Sep 23, 2019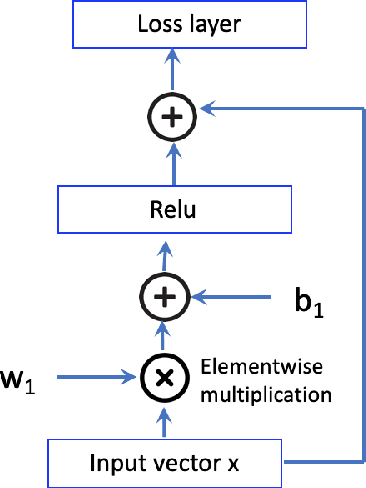
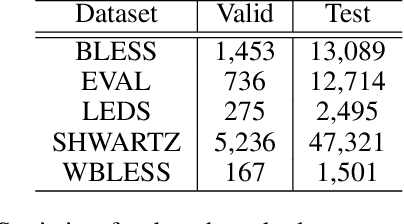
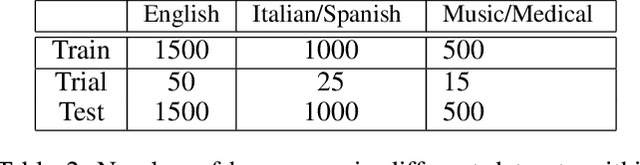
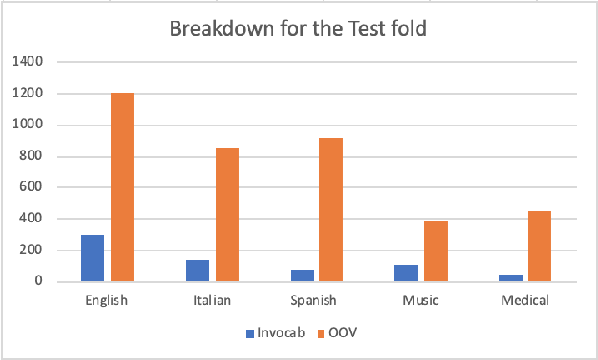
This paper introduces Strict Partial Order Networks (SPON), a novel neural network architecture designed to enforce asymmetry and transitive properties as soft constraints. We apply it to induce hypernymy relations by training with is-a pairs. We also present an augmented variant of SPON that can generalize type information learned for in-vocabulary terms to previously unseen ones. An extensive evaluation over eleven benchmarks across different tasks shows that SPON consistently either outperforms or attains the state of the art on all but one of these benchmarks.
An Efficient Approach for Super and Nested Term Indexing and Retrieval
May 23, 2019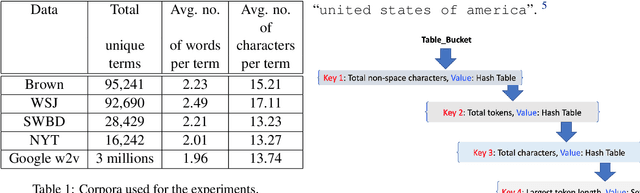
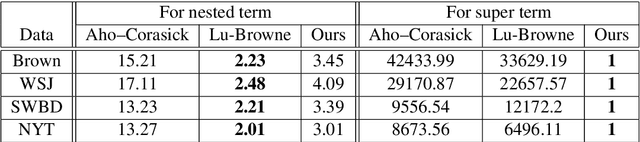
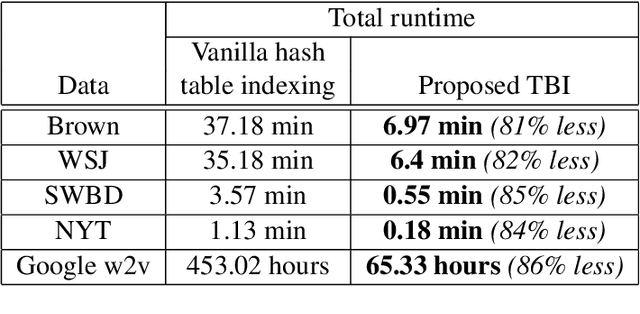
This paper describes a new approach, called Terminological Bucket Indexing (TBI), for efficient indexing and retrieval of both nested and super terms using a single method. We propose a hybrid data structure for facilitating faster indexing building. An evaluation of our approach with respect to widely used existing approaches on several publicly available dataset is provided. Compared to Trie based approaches, TBI provides comparable performance on nested term retrieval and far superior performance on super term retrieval. Compared to traditional hash table, TBI needs 80\% less time for indexing.
A Study on Passage Re-ranking in Embedding based Unsupervised Semantic Search
May 28, 2018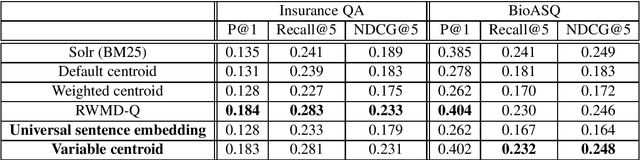
State of the art approaches for (embedding based) unsupervised semantic search exploits either compositional similarity (of a query and a passage) or pair-wise word (or term) similarity (from the query and the passage). By design, word based approaches do not incorporate similarity in the larger context (query/passage), while compositional similarity based approaches are usually unable to take advantage of the most important cues in the context. In this paper we propose a new compositional similarity based approach, called variable centroid vector (VCVB), that tries to address both of these limitations. We also presents results using a different type of compositional similarity based approach by exploiting universal sentence embedding. We provide empirical evaluation on two different benchmarks.
Language Independent Acquisition of Abbreviations
Sep 23, 2017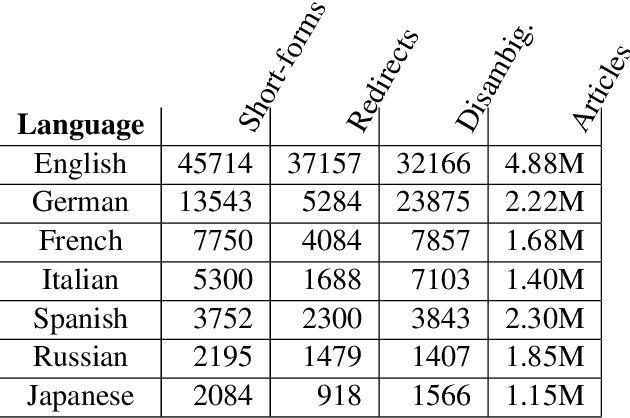
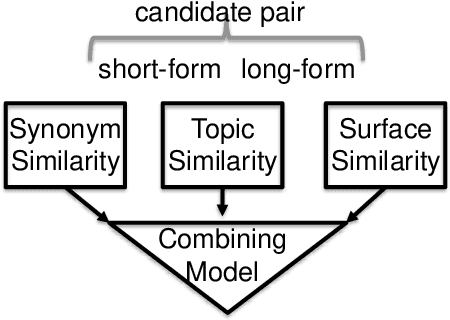
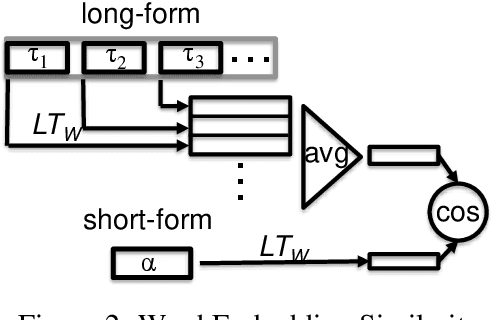
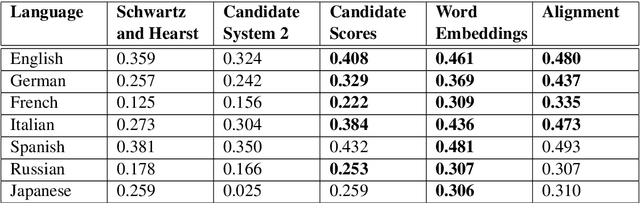
This paper addresses automatic extraction of abbreviations (encompassing acronyms and initialisms) and corresponding long-form expansions from plain unstructured text. We create and are going to release a multilingual resource for abbreviations and their corresponding expansions, built automatically by exploiting Wikipedia redirect and disambiguation pages, that can be used as a benchmark for evaluation. We address a shortcoming of previous work where only the redirect pages were used, and so every abbreviation had only a single expansion, even though multiple different expansions are possible for many of the abbreviations. We also develop a principled machine learning based approach to scoring expansion candidates using different techniques such as indicators of near synonymy, topical relatedness, and surface similarity. We show improved performance over seven languages, including two with a non-Latin alphabet, relative to strong baselines.