 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe infrastructure powering IBM's Gen AI model development
Jul 07, 2024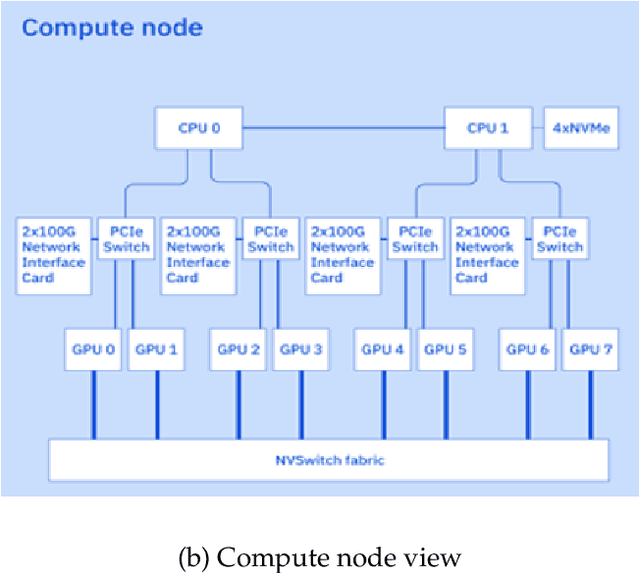
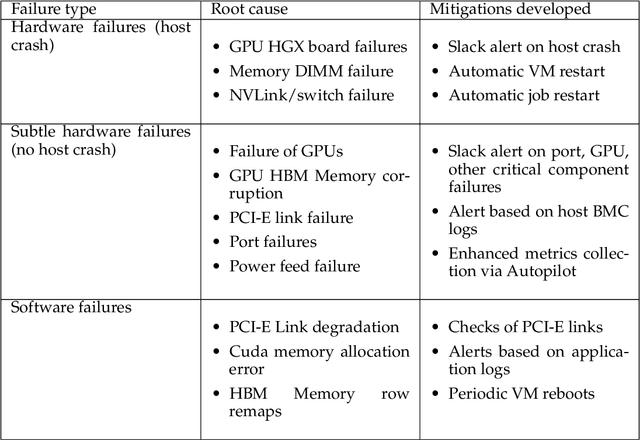
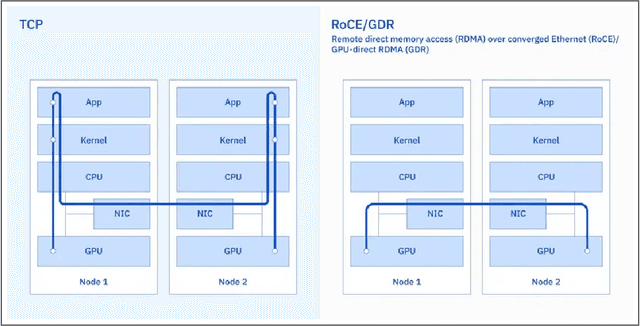
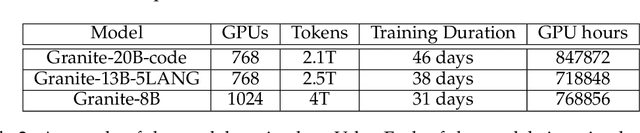
AI Infrastructure plays a key role in the speed and cost-competitiveness of developing and deploying advanced AI models. The current demand for powerful AI infrastructure for model training is driven by the emergence of generative AI and foundational models, where on occasion thousands of GPUs must cooperate on a single training job for the model to be trained in a reasonable time. Delivering efficient and high-performing AI training requires an end-to-end solution that combines hardware, software and holistic telemetry to cater for multiple types of AI workloads. In this report, we describe IBM's hybrid cloud infrastructure that powers our generative AI model development. This infrastructure includes (1) Vela: an AI-optimized supercomputing capability directly integrated into the IBM Cloud, delivering scalable, dynamic, multi-tenant and geographically distributed infrastructure for large-scale model training and other AI workflow steps and (2) Blue Vela: a large-scale, purpose-built, on-premises hosting environment that is optimized to support our largest and most ambitious AI model training tasks. Vela provides IBM with the dual benefit of high performance for internal use along with the flexibility to adapt to an evolving commercial landscape. Blue Vela provides us with the benefits of rapid development of our largest and most ambitious models, as well as future-proofing against the evolving model landscape in the industry. Taken together, they provide IBM with the ability to rapidly innovate in the development of both AI models and commercial offerings.
Knowledge Graph Induction enabling Recommending and Trend Analysis: A Corporate Research Community Use Case
Jul 18, 2022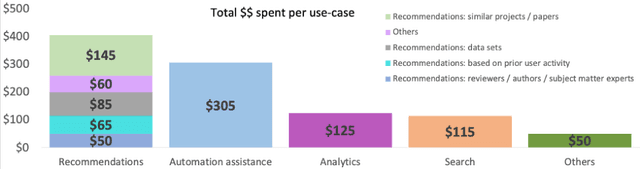

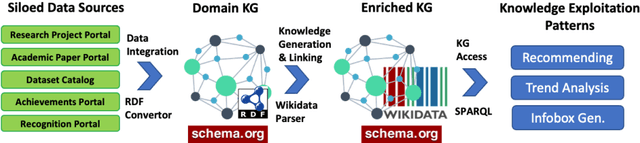
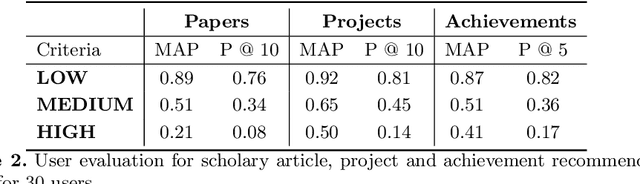
A research division plays an important role of driving innovation in an organization. Drawing insights, following trends, keeping abreast of new research, and formulating strategies are increasingly becoming more challenging for both researchers and executives as the amount of information grows in both velocity and volume. In this paper we present a use case of how a corporate research community, IBM Research, utilizes Semantic Web technologies to induce a unified Knowledge Graph from both structured and textual data obtained by integrating various applications used by the community related to research projects, academic papers, datasets, achievements and recognition. In order to make the Knowledge Graph more accessible to application developers, we identified a set of common patterns for exploiting the induced knowledge and exposed them as APIs. Those patterns were born out of user research which identified the most valuable use cases or user pain points to be alleviated. We outline two distinct scenarios: recommendation and analytics for business use. We will discuss these scenarios in detail and provide an empirical evaluation on entity recommendation specifically. The methodology used and the lessons learned from this work can be applied to other organizations facing similar challenges.