 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSmartEval: A Benchmark for Evaluating LLM-Generated Smart Contracts from Natural Language Specifications
May 10, 2026We introduce SmartEval, a benchmark for systematically evaluating the quality of Solidity smart contracts generated by large language models (LLMs) from natural language specifications. SmartEval provides a corpus of 9,000 generated contracts paired with expert-written ground-truth implementations drawn from the FSMSCG dataset, a five-dimensional evaluation rubric covering functional completeness, variable fidelity, state-machine correctness, business-logic fidelity, and code quality, and a reproducible generation-and-evaluation pipeline. To validate the benchmark's reliability, we conduct three independent empirical studies: a five-condition ablation study (N=300 per condition) isolating the contribution of each pipeline component, a human expert evaluation by three Columbia University PhD researchers confirming automated scores align with expert judgment to within 0.34 points, and external security analysis via the Slither static analyzer confirming 79.4% agreement between the LLM auditor and a non-LLM rule-based tool. Systematic analysis of 9,000 generated contracts reveals characteristic failure modes (logic omissions at 35.3%, state transition errors at 23.4%, and complexity-driven degradation) and quantifies a +8.29 composite-score advantage of generated contracts over ground-truth implementations, attributable to LLMs' literal specification-following behavior. SmartEval establishes a reproducible, validated foundation for empirical research on LLM smart contract synthesis quality, with all data, evaluation code, and generated contracts publicly released.
An end-to-end agentic pipeline for smart contract translation and quality evaluation
Feb 14, 2026We present an end-to-end framework for systematic evaluation of LLM-generated smart contracts from natural-language specifications. The system parses contractual text into structured schemas, generates Solidity code, and performs automated quality assessment through compilation and security checks. Using CrewAI-style agent teams with iterative refinement, the pipeline produces structured artifacts with full provenance metadata. Quality is measured across five dimensions, including functional completeness, variable fidelity, state-machine correctness, business-logic fidelity, and code quality aggregated into composite scores. The framework supports paired evaluation against ground-truth implementations, quantifying alignment and identifying systematic error modes such as logic omissions and state transition inconsistencies. This provides a reproducible benchmark for empirical research on smart contract synthesis quality and supports extensions to formal verification and compliance checking.
Knowledge Base Construction for Knowledge-Augmented Text-to-SQL
May 28, 2025Text-to-SQL aims to translate natural language queries into SQL statements, which is practical as it enables anyone to easily retrieve the desired information from databases. Recently, many existing approaches tackle this problem with Large Language Models (LLMs), leveraging their strong capability in understanding user queries and generating corresponding SQL code. Yet, the parametric knowledge in LLMs might be limited to covering all the diverse and domain-specific queries that require grounding in various database schemas, which makes generated SQLs less accurate oftentimes. To tackle this, we propose constructing the knowledge base for text-to-SQL, a foundational source of knowledge, from which we retrieve and generate the necessary knowledge for given queries. In particular, unlike existing approaches that either manually annotate knowledge or generate only a few pieces of knowledge for each query, our knowledge base is comprehensive, which is constructed based on a combination of all the available questions and their associated database schemas along with their relevant knowledge, and can be reused for unseen databases from different datasets and domains. We validate our approach on multiple text-to-SQL datasets, considering both the overlapping and non-overlapping database scenarios, where it outperforms relevant baselines substantially.
Retrieval-Based Transformer for Table Augmentation
Jun 20, 2023Data preparation, also called data wrangling, is considered one of the most expensive and time-consuming steps when performing analytics or building machine learning models. Preparing data typically involves collecting and merging data from complex heterogeneous, and often large-scale data sources, such as data lakes. In this paper, we introduce a novel approach toward automatic data wrangling in an attempt to alleviate the effort of end-users, e.g. data analysts, in structuring dynamic views from data lakes in the form of tabular data. We aim to address table augmentation tasks, including row/column population and data imputation. Given a corpus of tables, we propose a retrieval augmented self-trained transformer model. Our self-learning strategy consists in randomly ablating tables from the corpus and training the retrieval-based model to reconstruct the original values or headers given the partial tables as input. We adopt this strategy to first train the dense neural retrieval model encoding table-parts to vectors, and then the end-to-end model trained to perform table augmentation tasks. We test on EntiTables, the standard benchmark for table augmentation, as well as introduce a new benchmark to advance further research: WebTables. Our model consistently and substantially outperforms both supervised statistical methods and the current state-of-the-art transformer-based models.
KnowGL: Knowledge Generation and Linking from Text
Oct 25, 2022
We propose KnowGL, a tool that allows converting text into structured relational data represented as a set of ABox assertions compliant with the TBox of a given Knowledge Graph (KG), such as Wikidata. We address this problem as a sequence generation task by leveraging pre-trained sequence-to-sequence language models, e.g. BART. Given a sentence, we fine-tune such models to detect pairs of entity mentions and jointly generate a set of facts consisting of the full set of semantic annotations for a KG, such as entity labels, entity types, and their relationships. To showcase the capabilities of our tool, we build a web application consisting of a set of UI widgets that help users to navigate through the semantic data extracted from a given input text. We make the KnowGL model available at https://huggingface.co/ibm/knowgl-large.
Knowledge Graph Induction enabling Recommending and Trend Analysis: A Corporate Research Community Use Case
Jul 18, 2022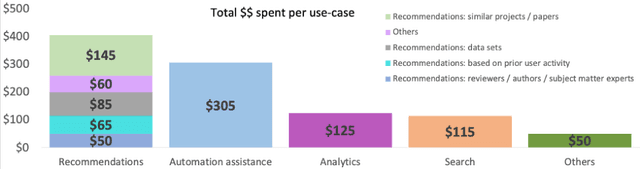

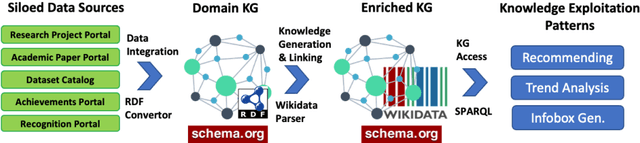
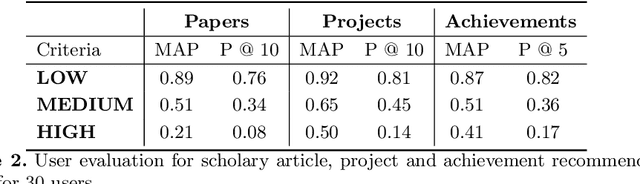
A research division plays an important role of driving innovation in an organization. Drawing insights, following trends, keeping abreast of new research, and formulating strategies are increasingly becoming more challenging for both researchers and executives as the amount of information grows in both velocity and volume. In this paper we present a use case of how a corporate research community, IBM Research, utilizes Semantic Web technologies to induce a unified Knowledge Graph from both structured and textual data obtained by integrating various applications used by the community related to research projects, academic papers, datasets, achievements and recognition. In order to make the Knowledge Graph more accessible to application developers, we identified a set of common patterns for exploiting the induced knowledge and exposed them as APIs. Those patterns were born out of user research which identified the most valuable use cases or user pain points to be alleviated. We outline two distinct scenarios: recommendation and analytics for business use. We will discuss these scenarios in detail and provide an empirical evaluation on entity recommendation specifically. The methodology used and the lessons learned from this work can be applied to other organizations facing similar challenges.
Re2G: Retrieve, Rerank, Generate
Jul 13, 2022
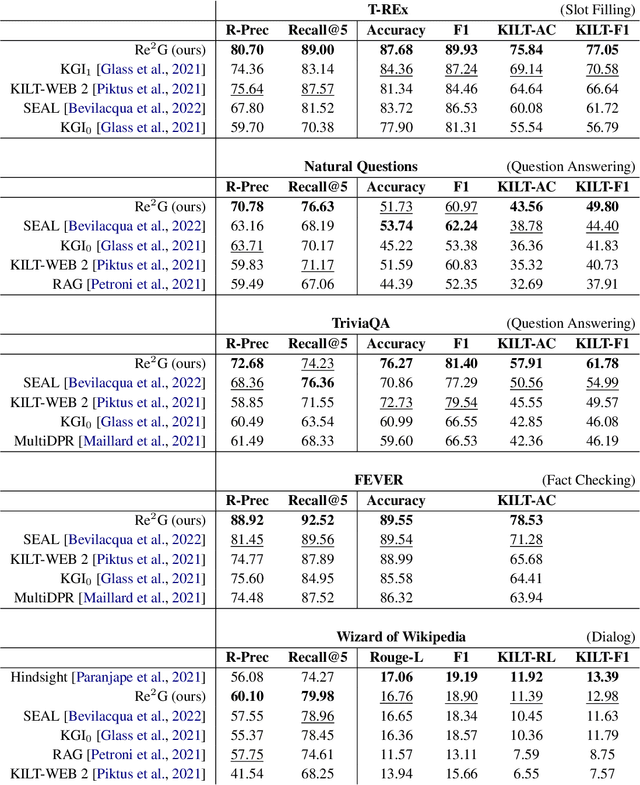
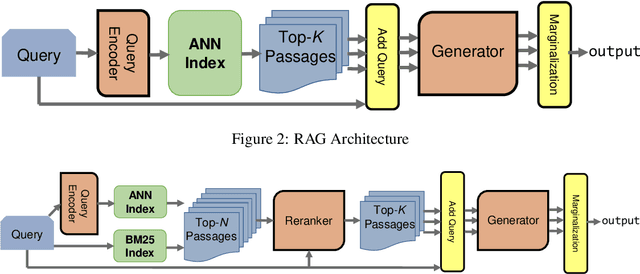
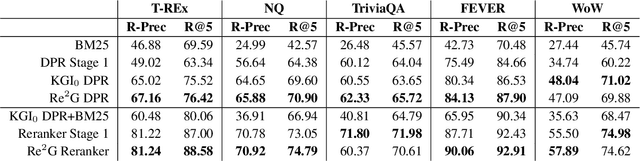
As demonstrated by GPT-3 and T5, transformers grow in capability as parameter spaces become larger and larger. However, for tasks that require a large amount of knowledge, non-parametric memory allows models to grow dramatically with a sub-linear increase in computational cost and GPU memory requirements. Recent models such as RAG and REALM have introduced retrieval into conditional generation. These models incorporate neural initial retrieval from a corpus of passages. We build on this line of research, proposing Re2G, which combines both neural initial retrieval and reranking into a BART-based sequence-to-sequence generation. Our reranking approach also permits merging retrieval results from sources with incomparable scores, enabling an ensemble of BM25 and neural initial retrieval. To train our system end-to-end, we introduce a novel variation of knowledge distillation to train the initial retrieval, reranker, and generation using only ground truth on the target sequence output. We find large gains in four diverse tasks: zero-shot slot filling, question answering, fact-checking, and dialog, with relative gains of 9% to 34% over the previous state-of-the-art on the KILT leaderboard. We make our code available as open source at https://github.com/IBM/kgi-slot-filling/tree/re2g.
KGI: An Integrated Framework for Knowledge Intensive Language Tasks
Apr 08, 2022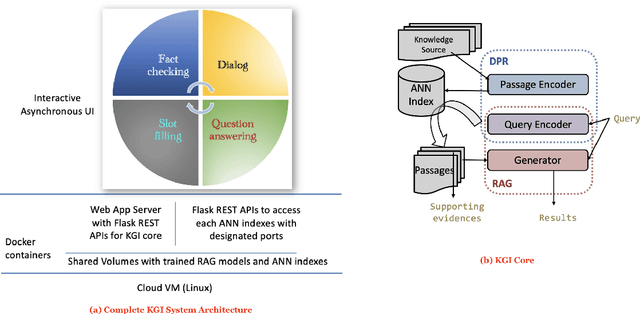
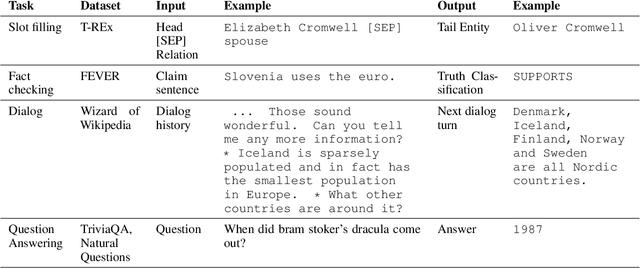
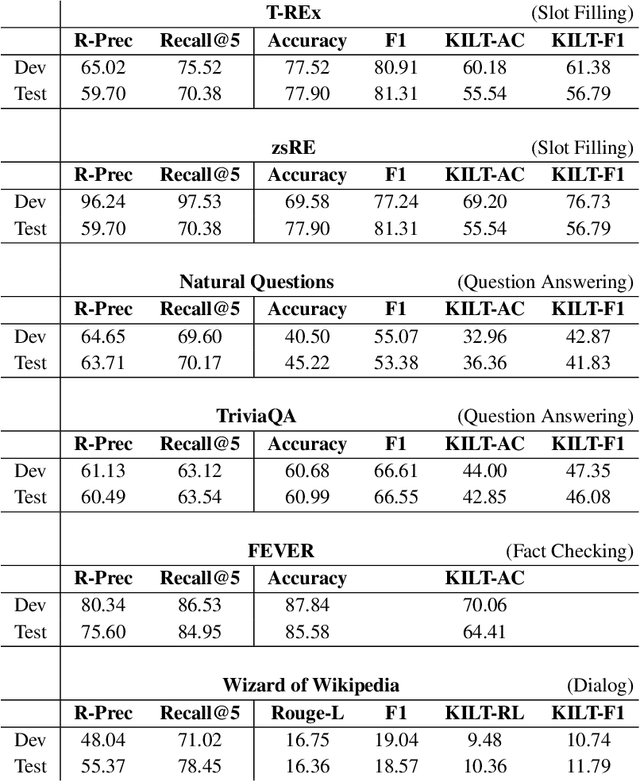
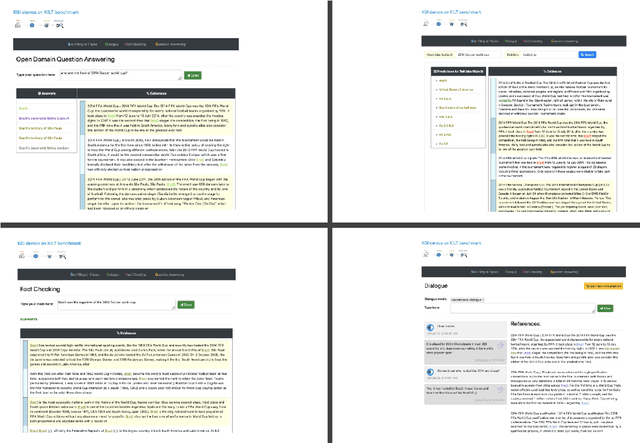
In a recent work, we presented a novel state-of-the-art approach to zero-shot slot filling that extends dense passage retrieval with hard negatives and robust training procedures for retrieval augmented generation models. In this paper, we propose a system based on an enhanced version of this approach where we train task specific models for other knowledge intensive language tasks, such as open domain question answering (QA), dialogue and fact checking. Our system achieves results comparable to the best models in the KILT leaderboards. Moreover, given a user query, we show how the output from these different models can be combined to cross-examine each other. Particularly, we show how accuracy in dialogue can be improved using the QA model. A short video demonstrating the system is available here - \url{https://ibm.box.com/v/kgi-interactive-demo} .
End-to-End Table Question Answering via Retrieval-Augmented Generation
Mar 30, 2022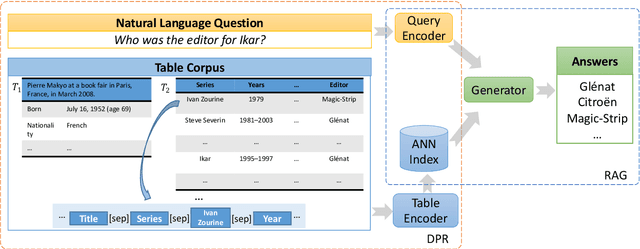
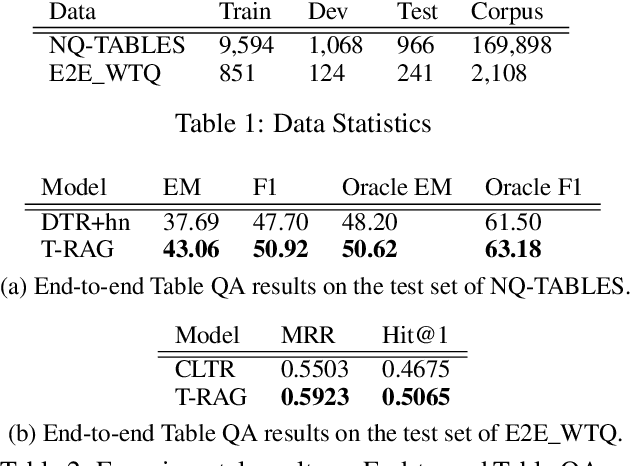
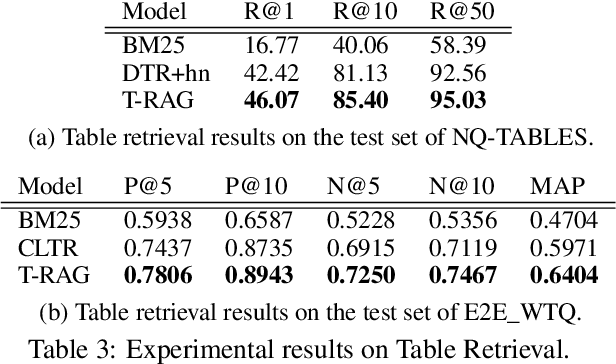
Most existing end-to-end Table Question Answering (Table QA) models consist of a two-stage framework with a retriever to select relevant table candidates from a corpus and a reader to locate the correct answers from table candidates. Even though the accuracy of the reader models is significantly improved with the recent transformer-based approaches, the overall performance of such frameworks still suffers from the poor accuracy of using traditional information retrieval techniques as retrievers. To alleviate this problem, we introduce T-RAG, an end-to-end Table QA model, where a non-parametric dense vector index is fine-tuned jointly with BART, a parametric sequence-to-sequence model to generate answer tokens. Given any natural language question, T-RAG utilizes a unified pipeline to automatically search through a table corpus to directly locate the correct answer from the table cells. We apply T-RAG to recent open-domain Table QA benchmarks and demonstrate that the fine-tuned T-RAG model is able to achieve state-of-the-art performance in both the end-to-end Table QA and the table retrieval tasks.
A Generative Model for Relation Extraction and Classification
Feb 26, 2022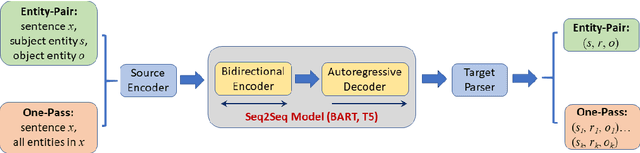
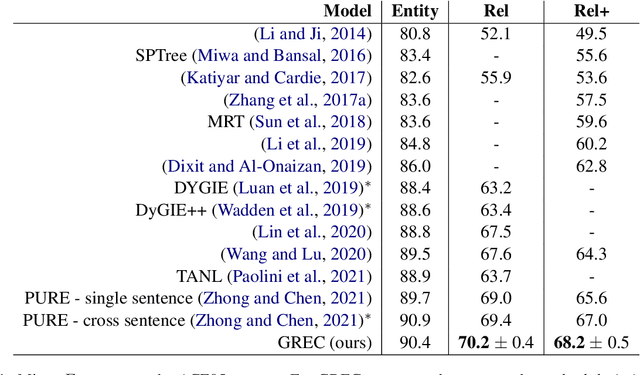
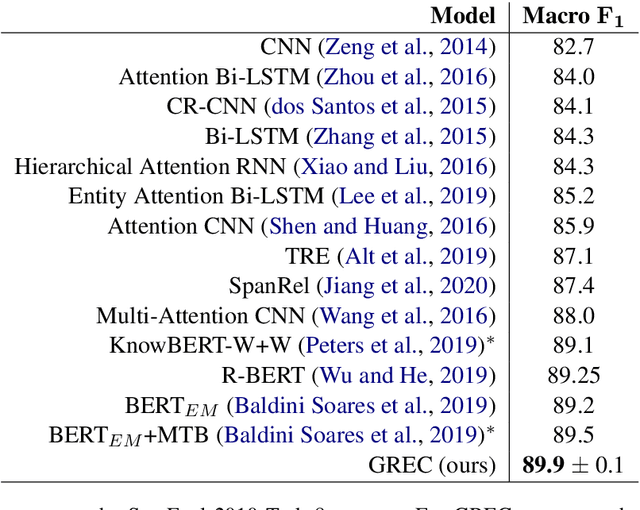
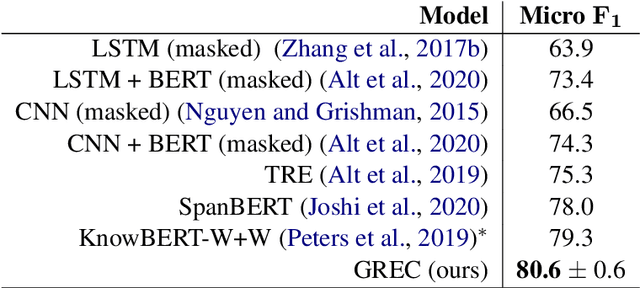
Relation extraction (RE) is an important information extraction task which provides essential information to many NLP applications such as knowledge base population and question answering. In this paper, we present a novel generative model for relation extraction and classification (which we call GREC), where RE is modeled as a sequence-to-sequence generation task. We explore various encoding representations for the source and target sequences, and design effective schemes that enable GREC to achieve state-of-the-art performance on three benchmark RE datasets. In addition, we introduce negative sampling and decoding scaling techniques which provide a flexible tool to tune the precision and recall performance of the model. Our approach can be extended to extract all relation triples from a sentence in one pass. Although the one-pass approach incurs certain performance loss, it is much more computationally efficient.