 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge Base Construction for Knowledge-Augmented Text-to-SQL
May 28, 2025Text-to-SQL aims to translate natural language queries into SQL statements, which is practical as it enables anyone to easily retrieve the desired information from databases. Recently, many existing approaches tackle this problem with Large Language Models (LLMs), leveraging their strong capability in understanding user queries and generating corresponding SQL code. Yet, the parametric knowledge in LLMs might be limited to covering all the diverse and domain-specific queries that require grounding in various database schemas, which makes generated SQLs less accurate oftentimes. To tackle this, we propose constructing the knowledge base for text-to-SQL, a foundational source of knowledge, from which we retrieve and generate the necessary knowledge for given queries. In particular, unlike existing approaches that either manually annotate knowledge or generate only a few pieces of knowledge for each query, our knowledge base is comprehensive, which is constructed based on a combination of all the available questions and their associated database schemas along with their relevant knowledge, and can be reused for unseen databases from different datasets and domains. We validate our approach on multiple text-to-SQL datasets, considering both the overlapping and non-overlapping database scenarios, where it outperforms relevant baselines substantially.
WikiCausal: Corpus and Evaluation Framework for Causal Knowledge Graph Construction
Aug 31, 2024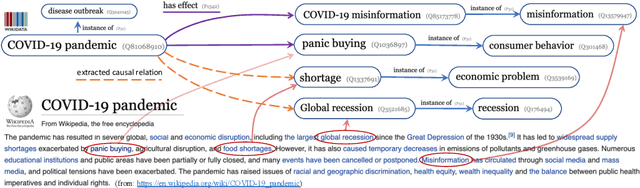


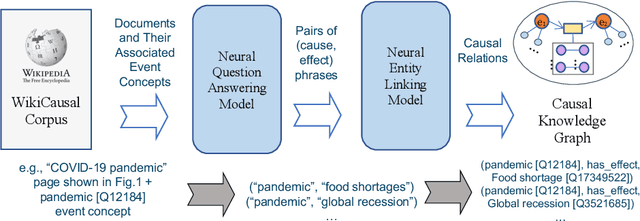
Recently, there has been an increasing interest in the construction of general-domain and domain-specific causal knowledge graphs. Such knowledge graphs enable reasoning for causal analysis and event prediction, and so have a range of applications across different domains. While great progress has been made toward automated construction of causal knowledge graphs, the evaluation of such solutions has either focused on low-level tasks (e.g., cause-effect phrase extraction) or on ad hoc evaluation data and small manual evaluations. In this paper, we present a corpus, task, and evaluation framework for causal knowledge graph construction. Our corpus consists of Wikipedia articles for a collection of event-related concepts in Wikidata. The task is to extract causal relations between event concepts from the corpus. The evaluation is performed in part using existing causal relations in Wikidata to measure recall, and in part using Large Language Models to avoid the need for manual or crowd-sourced evaluation. We evaluate a pipeline for causal knowledge graph construction that relies on neural models for question answering and concept linking, and show how the corpus and the evaluation framework allow us to effectively find the right model for each task. The corpus and the evaluation framework are publicly available.
TabSketchFM: Sketch-based Tabular Representation Learning for Data Discovery over Data Lakes
Jun 28, 2024



Enterprises have a growing need to identify relevant tables in data lakes; e.g. tables that are unionable, joinable, or subsets of each other. Tabular neural models can be helpful for such data discovery tasks. In this paper, we present TabSketchFM, a neural tabular model for data discovery over data lakes. First, we propose a novel pre-training sketch-based approach to enhance the effectiveness of data discovery techniques in neural tabular models. Second, to further finetune the pretrained model for several downstream tasks, we develop LakeBench, a collection of 8 benchmarks to help with different data discovery tasks such as finding tasks that are unionable, joinable, or subsets of each other. We then show on these finetuning tasks that TabSketchFM achieves state-of-the art performance compared to existing neural models. Third, we use these finetuned models to search for tables that are unionable, joinable, or can be subsets of each other. Our results demonstrate improvements in F1 scores for search compared to state-of-the-art techniques (even up to 70% improvement in a joinable search benchmark). Finally, we show significant transfer across datasets and tasks establishing that our model can generalize across different tasks over different data lakes
Distilling Event Sequence Knowledge From Large Language Models
Jan 14, 2024



Event sequence models have been found to be highly effective in the analysis and prediction of events. Building such models requires availability of abundant high-quality event sequence data. In certain applications, however, clean structured event sequences are not available, and automated sequence extraction results in data that is too noisy and incomplete. In this work, we explore the use of Large Language Models (LLMs) to generate event sequences that can effectively be used for probabilistic event model construction. This can be viewed as a mechanism of distilling event sequence knowledge from LLMs. Our approach relies on a Knowledge Graph (KG) of event concepts with partial causal relations to guide the generative language model for causal event sequence generation. We show that our approach can generate high-quality event sequences, filling a knowledge gap in the input KG. Furthermore, we explore how the generated sequences can be leveraged to discover useful and more complex structured knowledge from pattern mining and probabilistic event models. We release our sequence generation code and evaluation framework, as well as corpus of event sequence data.
An Evaluation Framework for Mapping News Headlines to Event Classes in a Knowledge Graph
Dec 04, 2023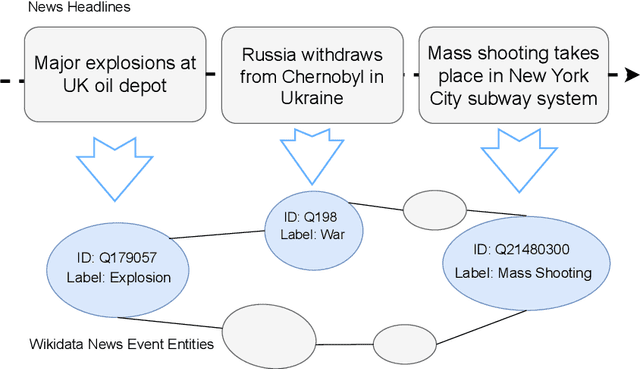

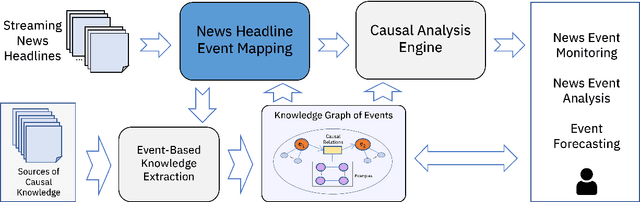

Mapping ongoing news headlines to event-related classes in a rich knowledge base can be an important component in a knowledge-based event analysis and forecasting solution. In this paper, we present a methodology for creating a benchmark dataset of news headlines mapped to event classes in Wikidata, and resources for the evaluation of methods that perform the mapping. We use the dataset to study two classes of unsupervised methods for this task: 1) adaptations of classic entity linking methods, and 2) methods that treat the problem as a zero-shot text classification problem. For the first approach, we evaluate off-the-shelf entity linking systems. For the second approach, we explore a) pre-trained natural language inference (NLI) models, and b) pre-trained large generative language models. We present the results of our evaluation, lessons learned, and directions for future work. The dataset and scripts for evaluation are made publicly available.
* Presented at CASE 2023 @ RANLP https://aclanthology.org/2023.case-1.6/
Event Prediction using Case-Based Reasoning over Knowledge Graphs
Sep 21, 2023



Applying link prediction (LP) methods over knowledge graphs (KG) for tasks such as causal event prediction presents an exciting opportunity. However, typical LP models are ill-suited for this task as they are incapable of performing inductive link prediction for new, unseen event entities and they require retraining as knowledge is added or changed in the underlying KG. We introduce a case-based reasoning model, EvCBR, to predict properties about new consequent events based on similar cause-effect events present in the KG. EvCBR uses statistical measures to identify similar events and performs path-based predictions, requiring no training step. To generalize our methods beyond the domain of event prediction, we frame our task as a 2-hop LP task, where the first hop is a causal relation connecting a cause event to a new effect event and the second hop is a property about the new event which we wish to predict. The effectiveness of our method is demonstrated using a novel dataset of newsworthy events with causal relations curated from Wikidata, where EvCBR outperforms baselines including translational-distance-based, GNN-based, and rule-based LP models.
Matching Table Metadata with Business Glossaries Using Large Language Models
Sep 08, 2023



Enterprises often own large collections of structured data in the form of large databases or an enterprise data lake. Such data collections come with limited metadata and strict access policies that could limit access to the data contents and, therefore, limit the application of classic retrieval and analysis solutions. As a result, there is a need for solutions that can effectively utilize the available metadata. In this paper, we study the problem of matching table metadata to a business glossary containing data labels and descriptions. The resulting matching enables the use of an available or curated business glossary for retrieval and analysis without or before requesting access to the data contents. One solution to this problem is to use manually-defined rules or similarity measures on column names and glossary descriptions (or their vector embeddings) to find the closest match. However, such approaches need to be tuned through manual labeling and cannot handle many business glossaries that contain a combination of simple as well as complex and long descriptions. In this work, we leverage the power of large language models (LLMs) to design generic matching methods that do not require manual tuning and can identify complex relations between column names and glossaries. We propose methods that utilize LLMs in two ways: a) by generating additional context for column names that can aid with matching b) by using LLMs to directly infer if there is a relation between column names and glossary descriptions. Our preliminary experimental results show the effectiveness of our proposed methods.
Improving Neural Ranking Models with Traditional IR Methods
Aug 29, 2023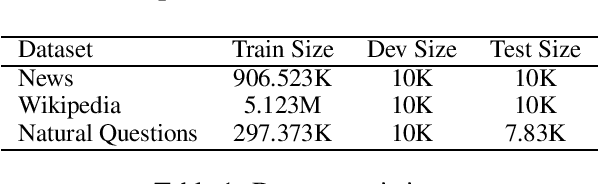
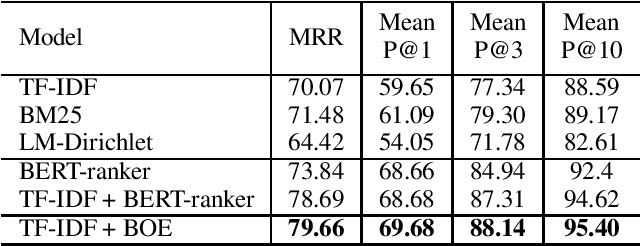


Neural ranking methods based on large transformer models have recently gained significant attention in the information retrieval community, and have been adopted by major commercial solutions. Nevertheless, they are computationally expensive to create, and require a great deal of labeled data for specialized corpora. In this paper, we explore a low resource alternative which is a bag-of-embedding model for document retrieval and find that it is competitive with large transformer models fine tuned on information retrieval tasks. Our results show that a simple combination of TF-IDF, a traditional keyword matching method, with a shallow embedding model provides a low cost path to compete well with the performance of complex neural ranking models on 3 datasets. Furthermore, adding TF-IDF measures improves the performance of large-scale fine tuned models on these tasks.
A Cross-Domain Evaluation of Approaches for Causal Knowledge Extraction
Aug 07, 2023



Causal knowledge extraction is the task of extracting relevant causes and effects from text by detecting the causal relation. Although this task is important for language understanding and knowledge discovery, recent works in this domain have largely focused on binary classification of a text segment as causal or non-causal. In this regard, we perform a thorough analysis of three sequence tagging models for causal knowledge extraction and compare it with a span based approach to causality extraction. Our experiments show that embeddings from pre-trained language models (e.g. BERT) provide a significant performance boost on this task compared to previous state-of-the-art models with complex architectures. We observe that span based models perform better than simple sequence tagging models based on BERT across all 4 data sets from diverse domains with different types of cause-effect phrases.
LakeBench: Benchmarks for Data Discovery over Data Lakes
Jul 09, 2023



Within enterprises, there is a growing need to intelligently navigate data lakes, specifically focusing on data discovery. Of particular importance to enterprises is the ability to find related tables in data repositories. These tables can be unionable, joinable, or subsets of each other. There is a dearth of benchmarks for these tasks in the public domain, with related work targeting private datasets. In LakeBench, we develop multiple benchmarks for these tasks by using the tables that are drawn from a diverse set of data sources such as government data from CKAN, Socrata, and the European Central Bank. We compare the performance of 4 publicly available tabular foundational models on these tasks. None of the existing models had been trained on the data discovery tasks that we developed for this benchmark; not surprisingly, their performance shows significant room for improvement. The results suggest that the establishment of such benchmarks may be useful to the community to build tabular models usable for data discovery in data lakes.