 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeC2P-GCN: Cell-to-Patch Graph Convolutional Network for Colorectal Cancer Grading
Mar 08, 2024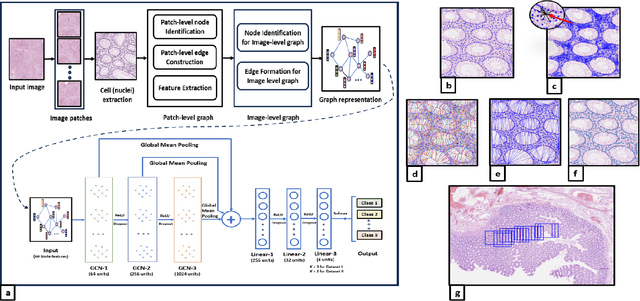
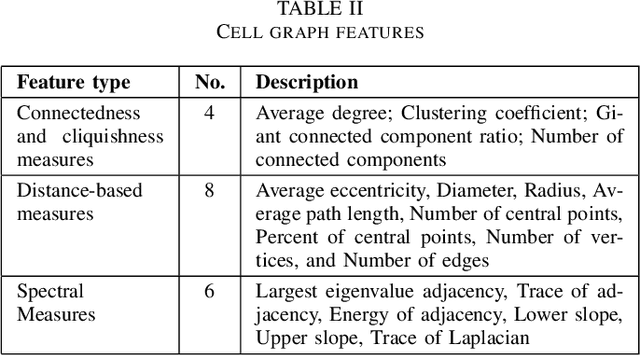

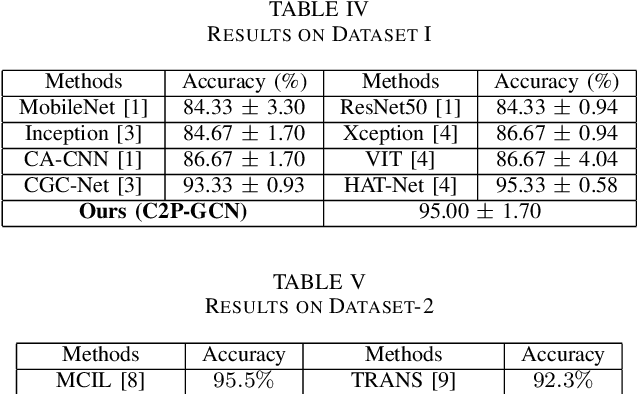
Graph-based learning approaches, due to their ability to encode tissue/organ structure information, are increasingly favored for grading colorectal cancer histology images. Recent graph-based techniques involve dividing whole slide images (WSIs) into smaller or medium-sized patches, and then building graphs on each patch for direct use in training. This method, however, fails to capture the tissue structure information present in an entire WSI and relies on training from a significantly large dataset of image patches. In this paper, we propose a novel cell-to-patch graph convolutional network (C2P-GCN), which is a two-stage graph formation-based approach. In the first stage, it forms a patch-level graph based on the cell organization on each patch of a WSI. In the second stage, it forms an image-level graph based on a similarity measure between patches of a WSI considering each patch as a node of a graph. This graph representation is then fed into a multi-layer GCN-based classification network. Our approach, through its dual-phase graph construction, effectively gathers local structural details from individual patches and establishes a meaningful connection among all patches across a WSI. As C2P-GCN integrates the structural data of an entire WSI into a single graph, it allows our model to work with significantly fewer training data compared to the latest models for colorectal cancer. Experimental validation of C2P-GCN on two distinct colorectal cancer datasets demonstrates the effectiveness of our method.
Improving Neural Ranking Models with Traditional IR Methods
Aug 29, 2023
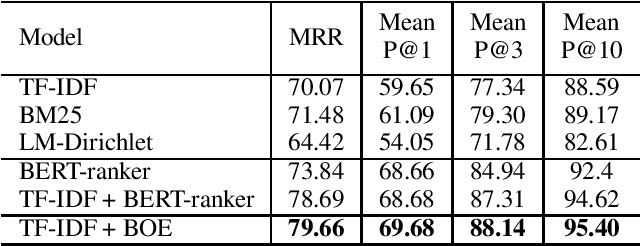


Neural ranking methods based on large transformer models have recently gained significant attention in the information retrieval community, and have been adopted by major commercial solutions. Nevertheless, they are computationally expensive to create, and require a great deal of labeled data for specialized corpora. In this paper, we explore a low resource alternative which is a bag-of-embedding model for document retrieval and find that it is competitive with large transformer models fine tuned on information retrieval tasks. Our results show that a simple combination of TF-IDF, a traditional keyword matching method, with a shallow embedding model provides a low cost path to compete well with the performance of complex neural ranking models on 3 datasets. Furthermore, adding TF-IDF measures improves the performance of large-scale fine tuned models on these tasks.
A Cross-Domain Evaluation of Approaches for Causal Knowledge Extraction
Aug 07, 2023



Causal knowledge extraction is the task of extracting relevant causes and effects from text by detecting the causal relation. Although this task is important for language understanding and knowledge discovery, recent works in this domain have largely focused on binary classification of a text segment as causal or non-causal. In this regard, we perform a thorough analysis of three sequence tagging models for causal knowledge extraction and compare it with a span based approach to causality extraction. Our experiments show that embeddings from pre-trained language models (e.g. BERT) provide a significant performance boost on this task compared to previous state-of-the-art models with complex architectures. We observe that span based models perform better than simple sequence tagging models based on BERT across all 4 data sets from diverse domains with different types of cause-effect phrases.
Word Sense Induction with Knowledge Distillation from BERT
Apr 20, 2023Pre-trained contextual language models are ubiquitously employed for language understanding tasks, but are unsuitable for resource-constrained systems. Noncontextual word embeddings are an efficient alternative in these settings. Such methods typically use one vector to encode multiple different meanings of a word, and incur errors due to polysemy. This paper proposes a two-stage method to distill multiple word senses from a pre-trained language model (BERT) by using attention over the senses of a word in a context and transferring this sense information to fit multi-sense embeddings in a skip-gram-like framework. We demonstrate an effective approach to training the sense disambiguation mechanism in our model with a distribution over word senses extracted from the output layer embeddings of BERT. Experiments on the contextual word similarity and sense induction tasks show that this method is superior to or competitive with state-of-the-art multi-sense embeddings on multiple benchmark data sets, and experiments with an embedding-based topic model (ETM) demonstrates the benefits of using this multi-sense embedding in a downstream application.
Anti-Malware Sandbox Games
Feb 28, 2022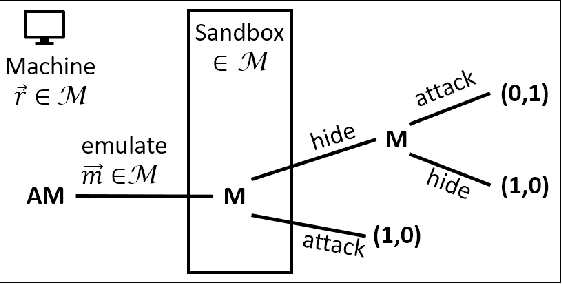


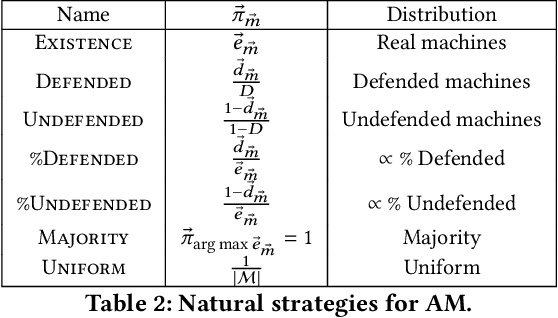
We develop a game theoretic model of malware protection using the state-of-the-art sandbox method, to characterize and compute optimal defense strategies for anti-malware. We model the strategic interaction between developers of malware (M) and anti-malware (AM) as a two player game, where AM commits to a strategy of generating sandbox environments, and M responds by choosing to either attack or hide malicious activity based on the environment it senses. We characterize the condition for AM to protect all its machines, and identify conditions under which an optimal AM strategy can be computed efficiently. For other cases, we provide a quadratically constrained quadratic program (QCQP)-based optimization framework to compute the optimal AM strategy. In addition, we identify a natural and easy to compute strategy for AM, which as we show empirically, achieves AM utility that is close to the optimal AM utility, in equilibrium.
The Adoption of Image-Driven Machine Learning for Microstructure Characterization and Materials Design: A Perspective
May 20, 2021
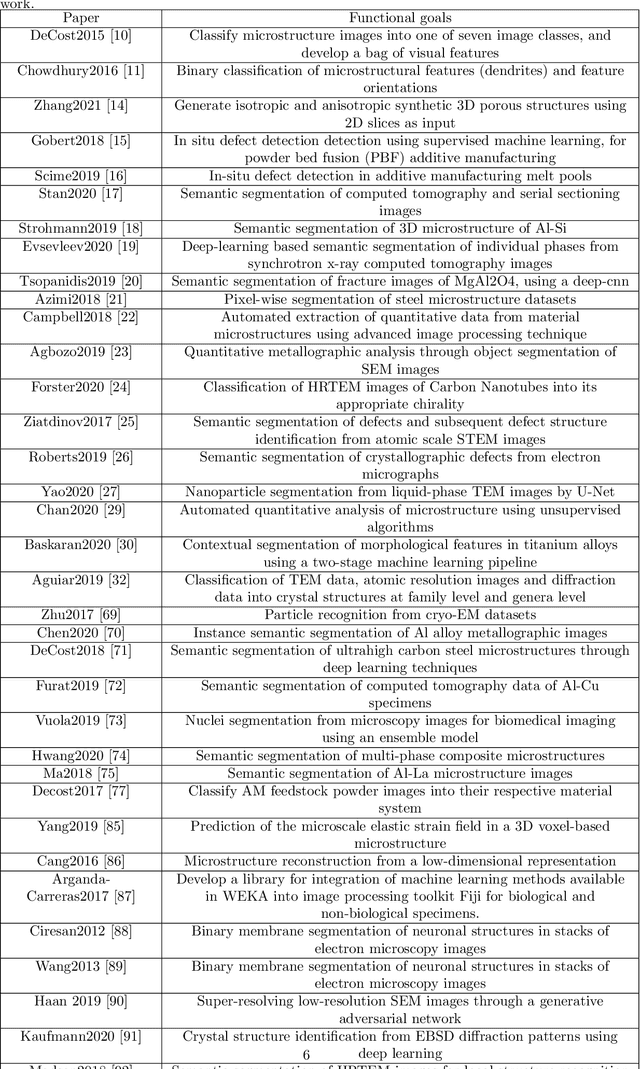
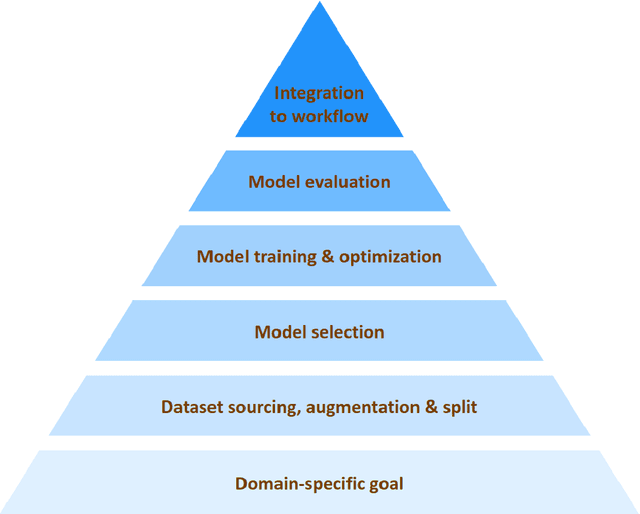
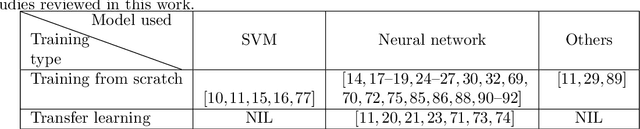
The recent surge in the adoption of machine learning techniques for materials design, discovery, and characterization has resulted in an increased interest and application of Image Driven Machine Learning (IDML) approaches. In this work, we review the application of IDML to the field of materials characterization. A hierarchy of six action steps is defined which compartmentalizes a problem statement into well-defined modules. The studies reviewed in this work are analyzed through the decisions adopted by them at each of these steps. Such a review permits a granular assessment of the field, for example the impact of IDML on materials characterization at the nanoscale, the number of images in a typical dataset required to train a semantic segmentation model on electron microscopy images, the prevalence of transfer learning in the domain, etc. Finally, we discuss the importance of interpretability and explainability, and provide an overview of two emerging techniques in the field: semantic segmentation and generative adversarial networks.
Quantifying error contributions of computational steps, algorithms and hyperparameter choices in image classification pipelines
Feb 25, 2019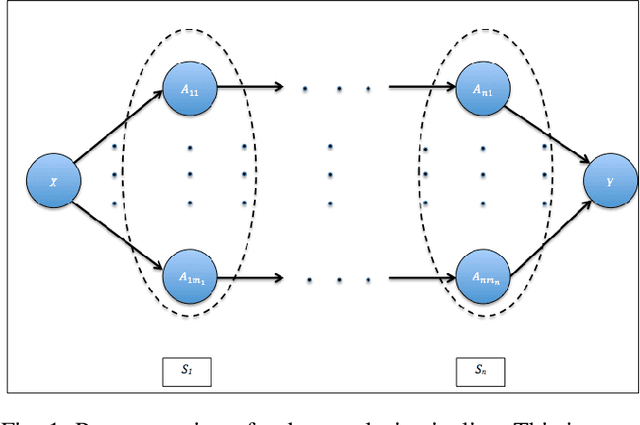
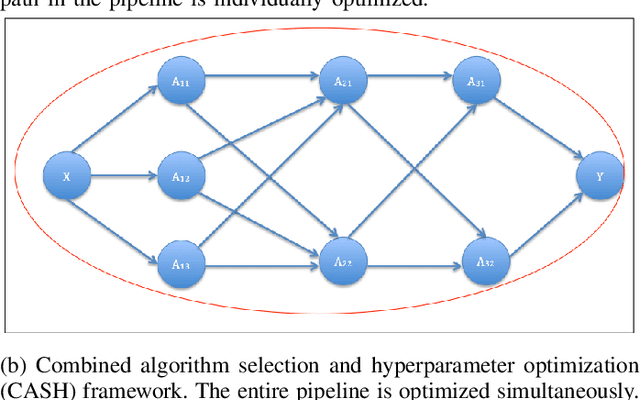
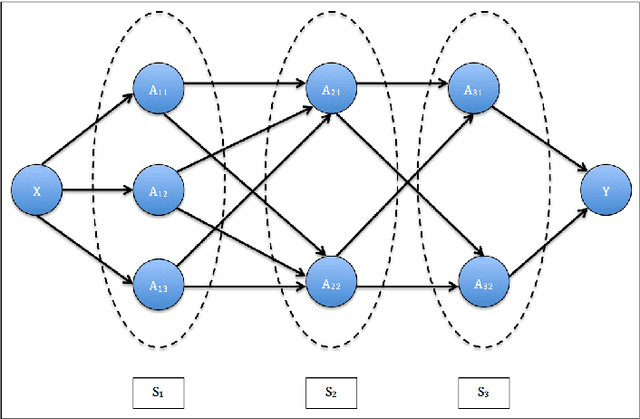
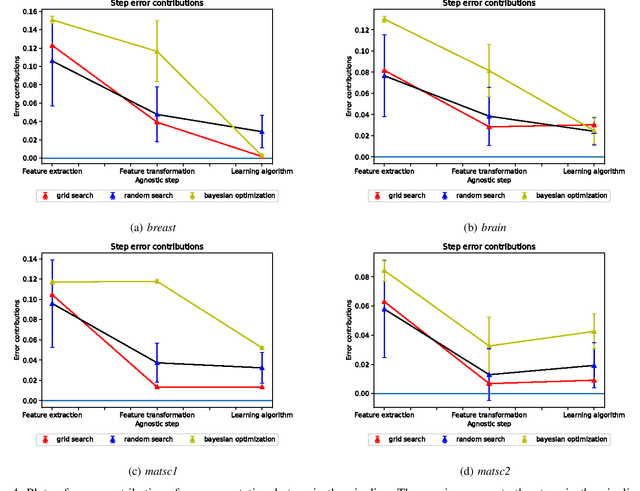
Data science relies on pipelines that are organized in the form of interdependent computational steps. Each step consists of various candidate algorithms that maybe used for performing a particular function. Each algorithm consists of several hyperparameters. Algorithms and hyperparameters must be optimized as a whole to produce the best performance. Typical machine learning pipelines typically consist of complex algorithms in each of the steps. Not only is the selection process combinatorial, but it is also important to interpret and understand the pipelines. We propose a method to quantify the importance of different layers in the pipeline, by computing an error contribution relative to an agnostic choice of algorithms in that layer. We demonstrate our methodology on image classification pipelines. The agnostic methodology quantifies the error contributions from the computational steps, algorithms and hyperparameters in the image classification pipeline. We show that algorithm selection and hyper-parameter optimization methods can be used to quantify the error contribution and that random search is able to quantify the contribution more accurately than Bayesian optimization. This methodology can be used by domain experts to understand machine learning and data analysis pipelines in terms of their individual components, which can help in prioritizing different components of the pipeline.
Quantifying contribution and propagation of error from computational steps, algorithms and hyperparameter choices in image classification pipelines
Feb 21, 2019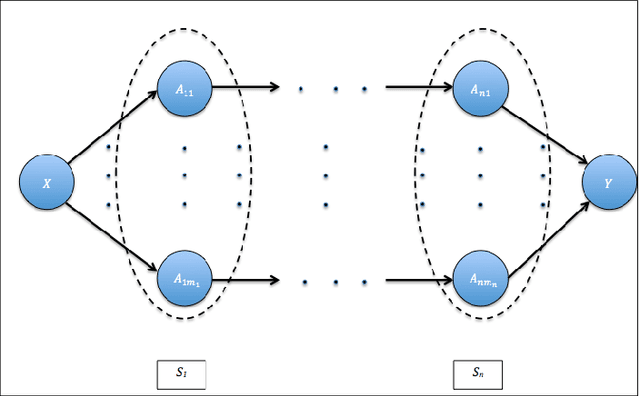

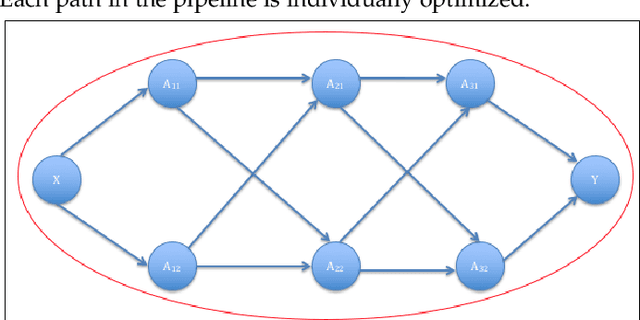
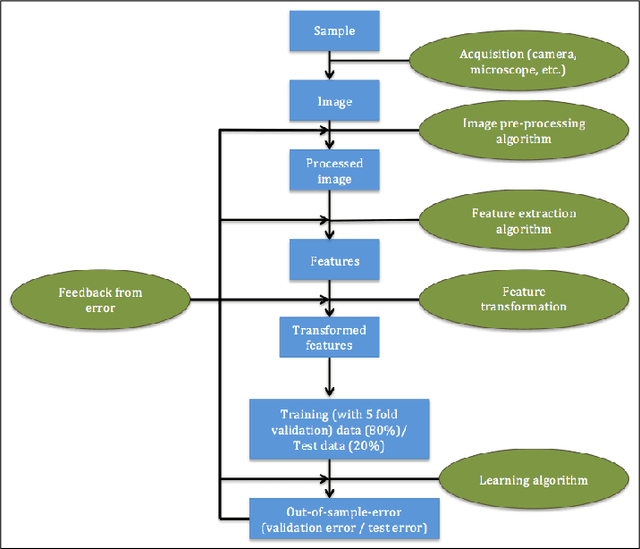
Data science relies on pipelines that are organized in the form of interdependent computational steps. Each step consists of various candidate algorithms that maybe used for performing a particular function. Each algorithm consists of several hyperparameters. Algorithms and hyperparameters must be optimized as a whole to produce the best performance. Typical machine learning pipelines consist of complex algorithms in each of the steps. Not only is the selection process combinatorial, but it is also important to interpret and understand the pipelines. We propose a method to quantify the importance of different components in the pipeline, by computing an error contribution relative to an agnostic choice of computational steps, algorithms and hyperparameters. We also propose a methodology to quantify the propagation of error from individual components of the pipeline with the help of a naive set of benchmark algorithms not involved in the pipeline. We demonstrate our methodology on image classification pipelines. The agnostic and naive methodologies quantify the error contribution and propagation respectively from the computational steps, algorithms and hyperparameters in the image classification pipeline. We show that algorithm selection and hyperparameter optimization methods like grid search, random search and Bayesian optimization can be used to quantify the error contribution and propagation, and that random search is able to quantify them more accurately than Bayesian optimization. This methodology can be used by domain experts to understand machine learning and data analysis pipelines in terms of their individual components, which can help in prioritizing different components of the pipeline.