 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantifying contribution and propagation of error from computational steps, algorithms and hyperparameter choices in image classification pipelines
Paper and Code
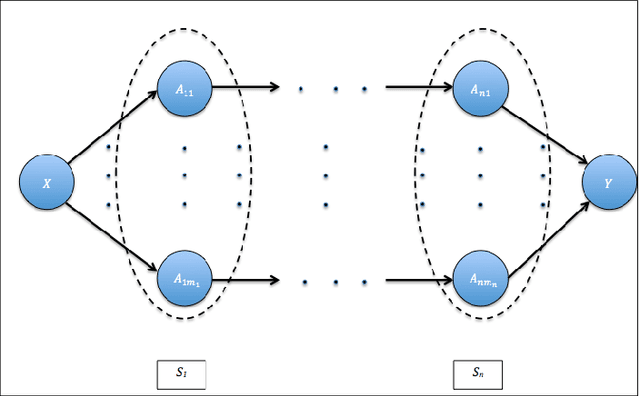

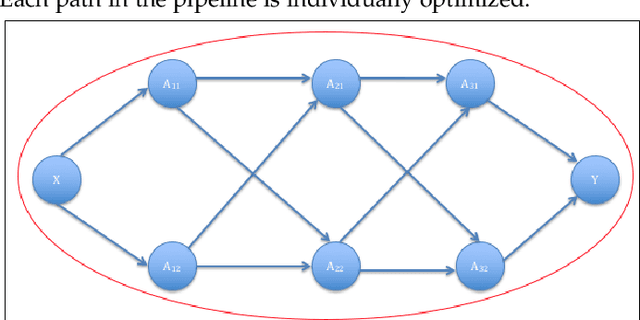
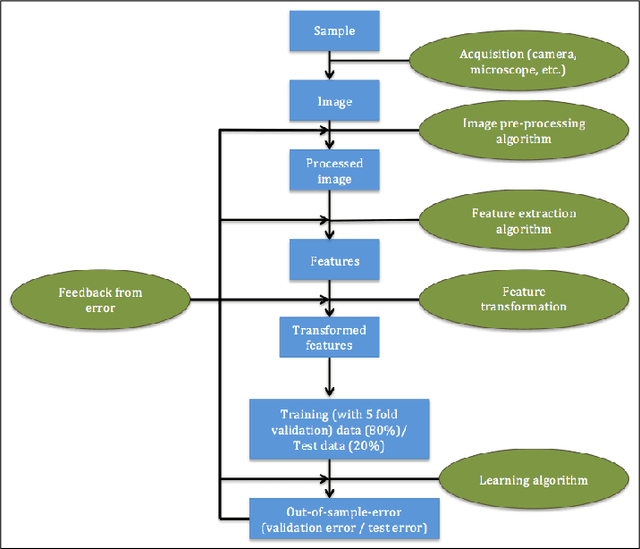
Data science relies on pipelines that are organized in the form of interdependent computational steps. Each step consists of various candidate algorithms that maybe used for performing a particular function. Each algorithm consists of several hyperparameters. Algorithms and hyperparameters must be optimized as a whole to produce the best performance. Typical machine learning pipelines consist of complex algorithms in each of the steps. Not only is the selection process combinatorial, but it is also important to interpret and understand the pipelines. We propose a method to quantify the importance of different components in the pipeline, by computing an error contribution relative to an agnostic choice of computational steps, algorithms and hyperparameters. We also propose a methodology to quantify the propagation of error from individual components of the pipeline with the help of a naive set of benchmark algorithms not involved in the pipeline. We demonstrate our methodology on image classification pipelines. The agnostic and naive methodologies quantify the error contribution and propagation respectively from the computational steps, algorithms and hyperparameters in the image classification pipeline. We show that algorithm selection and hyperparameter optimization methods like grid search, random search and Bayesian optimization can be used to quantify the error contribution and propagation, and that random search is able to quantify them more accurately than Bayesian optimization. This methodology can be used by domain experts to understand machine learning and data analysis pipelines in terms of their individual components, which can help in prioritizing different components of the pipeline.