 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Adversarial Reasoner: Enhancing LLM Reasoning with Adversarial Reinforcement Learning
Dec 18, 2025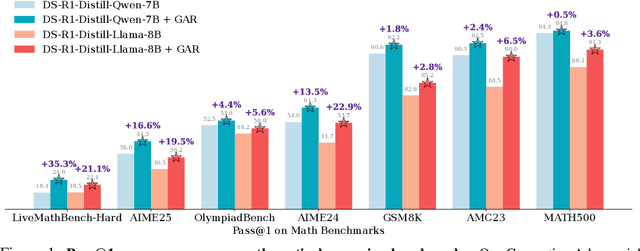

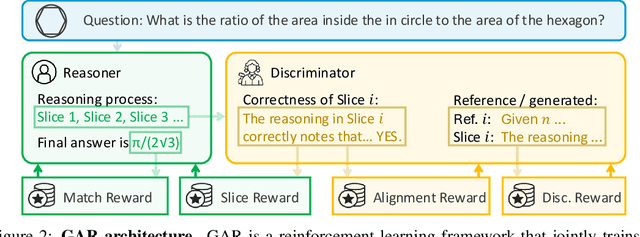

Large language models (LLMs) with explicit reasoning capabilities excel at mathematical reasoning yet still commit process errors, such as incorrect calculations, brittle logic, and superficially plausible but invalid steps. In this paper, we introduce Generative Adversarial Reasoner, an on-policy joint training framework designed to enhance reasoning by co-evolving an LLM reasoner and an LLM-based discriminator through adversarial reinforcement learning. A compute-efficient review schedule partitions each reasoning chain into logically complete slices of comparable length, and the discriminator evaluates each slice's soundness with concise, structured justifications. Learning couples complementary signals: the LLM reasoner is rewarded for logically consistent steps that yield correct answers, while the discriminator earns rewards for correctly detecting errors or distinguishing traces in the reasoning process. This produces dense, well-calibrated, on-policy step-level rewards that supplement sparse exact-match signals, improving credit assignment, increasing sample efficiency, and enhancing overall reasoning quality of LLMs. Across various mathematical benchmarks, the method delivers consistent gains over strong baselines with standard RL post-training. Specifically, on AIME24, we improve DeepSeek-R1-Distill-Qwen-7B from 54.0 to 61.3 (+7.3) and DeepSeek-R1-Distill-Llama-8B from 43.7 to 53.7 (+10.0). The modular discriminator also enables flexible reward shaping for objectives such as teacher distillation, preference alignment, and mathematical proof-based reasoning.
SpatialLLM: A Compound 3D-Informed Design towards Spatially-Intelligent Large Multimodal Models
May 01, 2025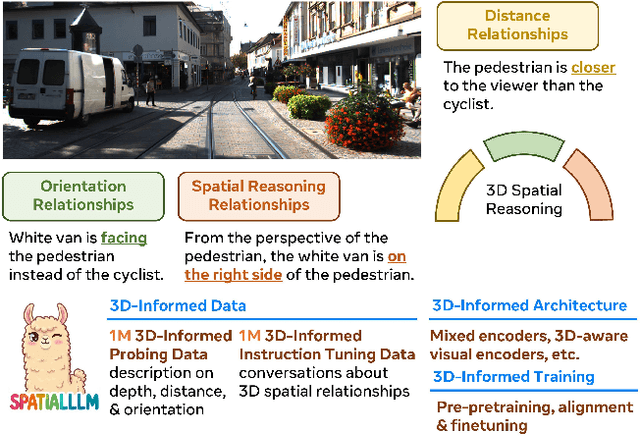
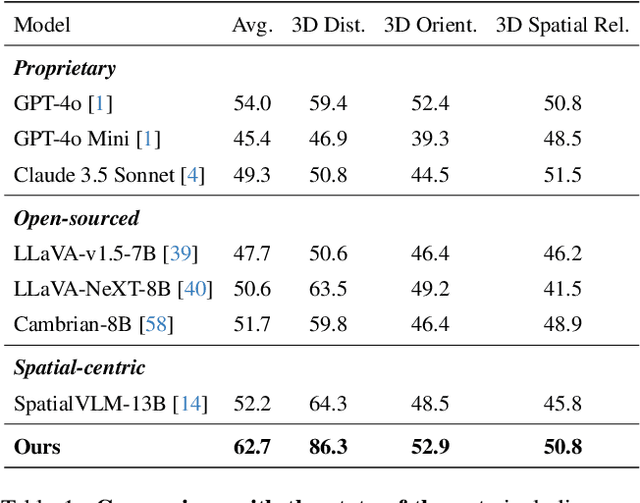
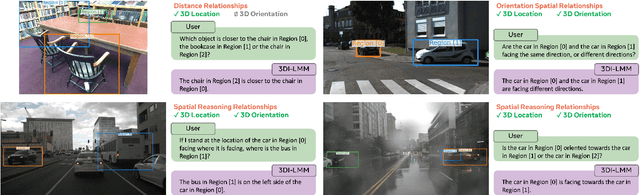
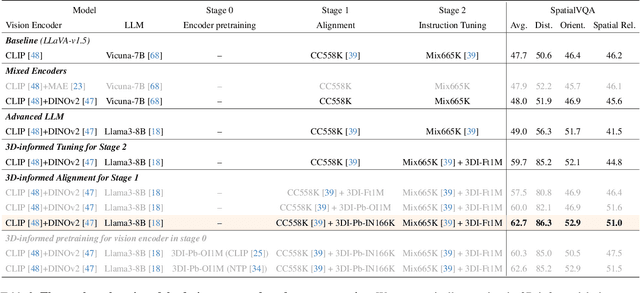
Humans naturally understand 3D spatial relationships, enabling complex reasoning like predicting collisions of vehicles from different directions. Current large multimodal models (LMMs), however, lack of this capability of 3D spatial reasoning. This limitation stems from the scarcity of 3D training data and the bias in current model designs toward 2D data. In this paper, we systematically study the impact of 3D-informed data, architecture, and training setups, introducing SpatialLLM, a large multi-modal model with advanced 3D spatial reasoning abilities. To address data limitations, we develop two types of 3D-informed training datasets: (1) 3D-informed probing data focused on object's 3D location and orientation, and (2) 3D-informed conversation data for complex spatial relationships. Notably, we are the first to curate VQA data that incorporate 3D orientation relationships on real images. Furthermore, we systematically integrate these two types of training data with the architectural and training designs of LMMs, providing a roadmap for optimal design aimed at achieving superior 3D reasoning capabilities. Our SpatialLLM advances machines toward highly capable 3D-informed reasoning, surpassing GPT-4o performance by 8.7%. Our systematic empirical design and the resulting findings offer valuable insights for future research in this direction.
SpatialReasoner: Towards Explicit and Generalizable 3D Spatial Reasoning
Apr 28, 2025



Recent studies in 3D spatial reasoning explore data-driven approaches and achieve enhanced spatial reasoning performance with reinforcement learning (RL). However, these methods typically perform spatial reasoning in an implicit manner, and it remains underexplored whether the acquired 3D knowledge generalizes to unseen question types at any stage of the training. In this work we introduce SpatialReasoner, a novel large vision-language model (LVLM) that address 3D spatial reasoning with explicit 3D representations shared between stages -- 3D perception, computation, and reasoning. Explicit 3D representations provide a coherent interface that supports advanced 3D spatial reasoning and enable us to study the factual errors made by LVLMs. Results show that our SpatialReasoner achieve improved performance on a variety of spatial reasoning benchmarks and generalizes better when evaluating on novel 3D spatial reasoning questions. Our study bridges the 3D parsing capabilities of prior visual foundation models with the powerful reasoning abilities of large language models, opening new directions for 3D spatial reasoning.
DINeMo: Learning Neural Mesh Models with no 3D Annotations
Mar 26, 2025



Category-level 3D/6D pose estimation is a crucial step towards comprehensive 3D scene understanding, which would enable a broad range of applications in robotics and embodied AI. Recent works explored neural mesh models that approach a range of 2D and 3D tasks from an analysis-by-synthesis perspective. Despite the largely enhanced robustness to partial occlusion and domain shifts, these methods depended heavily on 3D annotations for part-contrastive learning, which confines them to a narrow set of categories and hinders efficient scaling. In this work, we present DINeMo, a novel neural mesh model that is trained with no 3D annotations by leveraging pseudo-correspondence obtained from large visual foundation models. We adopt a bidirectional pseudo-correspondence generation method, which produce pseudo correspondence utilize both local appearance features and global context information. Experimental results on car datasets demonstrate that our DINeMo outperforms previous zero- and few-shot 3D pose estimation by a wide margin, narrowing the gap with fully-supervised methods by 67.3%. Our DINeMo also scales effectively and efficiently when incorporating more unlabeled images during training, which demonstrate the advantages over supervised learning methods that rely on 3D annotations. Our project page is available at https://analysis-by-synthesis.github.io/DINeMo/.
PulseCheck457: A Diagnostic Benchmark for 6D Spatial Reasoning of Large Multimodal Models
Feb 13, 2025Although large multimodal models (LMMs) have demonstrated remarkable capabilities in visual scene interpretation and reasoning, their capacity for complex and precise 3-dimensional spatial reasoning remains uncertain. Existing benchmarks focus predominantly on 2D spatial understanding and lack a framework to comprehensively evaluate 6D spatial reasoning across varying complexities. To address this limitation, we present PulseCheck457, a scalable and unbiased synthetic dataset designed with 4 key capability for spatial reasoning: multi-object recognition, 2D location, 3D location, and 3D orientation. We develop a cascading evaluation structure, constructing 7 question types across 5 difficulty levels that range from basic single object recognition to our new proposed complex 6D spatial reasoning tasks. We evaluated various large multimodal models (LMMs) on PulseCheck457, observing a general decline in performance as task complexity increases, particularly in 3D reasoning and 6D spatial tasks. To quantify these challenges, we introduce the Relative Performance Dropping Rate (RPDR), highlighting key weaknesses in 3D reasoning capabilities. Leveraging the unbiased attribute design of our dataset, we also uncover prediction biases across different attributes, with similar patterns observed in real-world image settings.
PulseCheck457: A Diagnostic Benchmark for Comprehensive Spatial Reasoning of Large Multimodal Models
Feb 12, 2025Although large multimodal models (LMMs) have demonstrated remarkable capabilities in visual scene interpretation and reasoning, their capacity for complex and precise 3-dimensional spatial reasoning remains uncertain. Existing benchmarks focus predominantly on 2D spatial understanding and lack a framework to comprehensively evaluate 6D spatial reasoning across varying complexities. To address this limitation, we present PulseCheck457, a scalable and unbiased synthetic dataset designed with 4 key capability for spatial reasoning: multi-object recognition, 2D location, 3D location, and 3D orientation. We develop a cascading evaluation structure, constructing 7 question types across 5 difficulty levels that range from basic single object recognition to our new proposed complex 6D spatial reasoning tasks. We evaluated various large multimodal models (LMMs) on PulseCheck457, observing a general decline in performance as task complexity increases, particularly in 3D reasoning and 6D spatial tasks. To quantify these challenges, we introduce the Relative Performance Dropping Rate (RPDR), highlighting key weaknesses in 3D reasoning capabilities. Leveraging the unbiased attribute design of our dataset, we also uncover prediction biases across different attributes, with similar patterns observed in real-world image settings.
3DSRBench: A Comprehensive 3D Spatial Reasoning Benchmark
Dec 10, 20243D spatial reasoning is the ability to analyze and interpret the positions, orientations, and spatial relationships of objects within the 3D space. This allows models to develop a comprehensive understanding of the 3D scene, enabling their applicability to a broader range of areas, such as autonomous navigation, robotics, and AR/VR. While large multi-modal models (LMMs) have achieved remarkable progress in a wide range of image and video understanding tasks, their capabilities to perform 3D spatial reasoning on diverse natural images are less studied. In this work we present the first comprehensive 3D spatial reasoning benchmark, 3DSRBench, with 2,772 manually annotated visual question-answer pairs across 12 question types. We conduct robust and thorough evaluation of 3D spatial reasoning capabilities by balancing the data distribution and adopting a novel FlipEval strategy. To further study the robustness of 3D spatial reasoning w.r.t. camera 3D viewpoints, our 3DSRBench includes two subsets with 3D spatial reasoning questions on paired images with common and uncommon viewpoints. We benchmark a wide range of open-sourced and proprietary LMMs, uncovering their limitations in various aspects of 3D awareness, such as height, orientation, location, and multi-object reasoning, as well as their degraded performance on images with uncommon camera viewpoints. Our 3DSRBench provide valuable findings and insights about the future development of LMMs with strong 3D reasoning capabilities. Our project page and dataset is available https://3dsrbench.github.io.
Rethinking Video-Text Understanding: Retrieval from Counterfactually Augmented Data
Jul 18, 2024Recent video-text foundation models have demonstrated strong performance on a wide variety of downstream video understanding tasks. Can these video-text models genuinely understand the contents of natural videos? Standard video-text evaluations could be misleading as many questions can be inferred merely from the objects and contexts in a single frame or biases inherent in the datasets. In this paper, we aim to better assess the capabilities of current video-text models and understand their limitations. We propose a novel evaluation task for video-text understanding, namely retrieval from counterfactually augmented data (RCAD), and a new Feint6K dataset. To succeed on our new evaluation task, models must derive a comprehensive understanding of the video from cross-frame reasoning. Analyses show that previous video-text foundation models can be easily fooled by counterfactually augmented data and are far behind human-level performance. In order to narrow the gap between video-text models and human performance on RCAD, we identify a key limitation of current contrastive approaches on video-text data and introduce LLM-teacher, a more effective approach to learn action semantics by leveraging knowledge obtained from a pretrained large language model. Experiments and analyses show that our approach successfully learn more discriminative action embeddings and improves results on Feint6K when applied to multiple video-text models. Our Feint6K dataset and project page is available at https://feint6k.github.io.
ImageNet3D: Towards General-Purpose Object-Level 3D Understanding
Jun 13, 2024
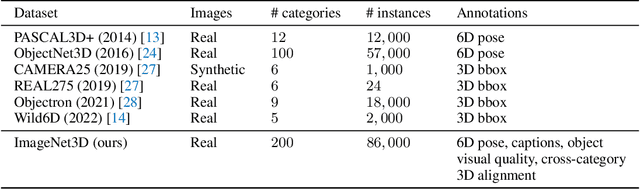

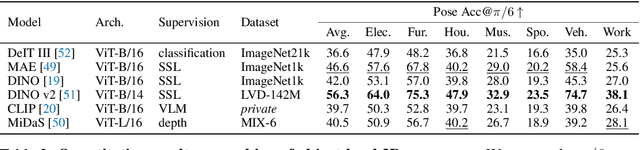
A vision model with general-purpose object-level 3D understanding should be capable of inferring both 2D (e.g., class name and bounding box) and 3D information (e.g., 3D location and 3D viewpoint) for arbitrary rigid objects in natural images. This is a challenging task, as it involves inferring 3D information from 2D signals and most importantly, generalizing to rigid objects from unseen categories. However, existing datasets with object-level 3D annotations are often limited by the number of categories or the quality of annotations. Models developed on these datasets become specialists for certain categories or domains, and fail to generalize. In this work, we present ImageNet3D, a large dataset for general-purpose object-level 3D understanding. ImageNet3D augments 200 categories from the ImageNet dataset with 2D bounding box, 3D pose, 3D location annotations, and image captions interleaved with 3D information. With the new annotations available in ImageNet3D, we could (i) analyze the object-level 3D awareness of visual foundation models, and (ii) study and develop general-purpose models that infer both 2D and 3D information for arbitrary rigid objects in natural images, and (iii) integrate unified 3D models with large language models for 3D-related reasoning.. We consider two new tasks, probing of object-level 3D awareness and open vocabulary pose estimation, besides standard classification and pose estimation. Experimental results on ImageNet3D demonstrate the potential of our dataset in building vision models with stronger general-purpose object-level 3D understanding.
Compositional 4D Dynamic Scenes Understanding with Physics Priors for Video Question Answering
Jun 02, 2024



For vision-language models (VLMs), understanding the dynamic properties of objects and their interactions within 3D scenes from video is crucial for effective reasoning. In this work, we introduce a video question answering dataset SuperCLEVR-Physics that focuses on the dynamics properties of objects. We concentrate on physical concepts -- velocity, acceleration, and collisions within 4D scenes, where the model needs to fully understand these dynamics properties and answer the questions built on top of them. From the evaluation of a variety of current VLMs, we find that these models struggle with understanding these dynamic properties due to the lack of explicit knowledge about the spatial structure in 3D and world dynamics in time variants. To demonstrate the importance of an explicit 4D dynamics representation of the scenes in understanding world dynamics, we further propose NS-4Dynamics, a Neural-Symbolic model for reasoning on 4D Dynamics properties under explicit scene representation from videos. Using scene rendering likelihood combining physical prior distribution, the 4D scene parser can estimate the dynamics properties of objects over time to and interpret the observation into 4D scene representation as world states. By further incorporating neural-symbolic reasoning, our approach enables advanced applications in future prediction, factual reasoning, and counterfactual reasoning. Our experiments show that our NS-4Dynamics suppresses previous VLMs in understanding the dynamics properties and answering questions about factual queries, future prediction, and counterfactual reasoning. Moreover, based on the explicit 4D scene representation, our model is effective in reconstructing the 4D scenes and re-simulate the future or counterfactual events.