 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaximum Likelihood Reinforcement Learning
Feb 02, 2026Reinforcement learning is the method of choice to train models in sampling-based setups with binary outcome feedback, such as navigation, code generation, and mathematical problem solving. In such settings, models implicitly induce a likelihood over correct rollouts. However, we observe that reinforcement learning does not maximize this likelihood, and instead optimizes only a lower-order approximation. Inspired by this observation, we introduce Maximum Likelihood Reinforcement Learning (MaxRL), a sampling-based framework to approximate maximum likelihood using reinforcement learning techniques. MaxRL addresses the challenges of non-differentiable sampling by defining a compute-indexed family of sample-based objectives that interpolate between standard reinforcement learning and exact maximum likelihood as additional sampling compute is allocated. The resulting objectives admit a simple, unbiased policy-gradient estimator and converge to maximum likelihood optimization in the infinite-compute limit. Empirically, we show that MaxRL Pareto-dominates existing methods in all models and tasks we tested, achieving up to 20x test-time scaling efficiency gains compared to its GRPO-trained counterpart. We also observe MaxRL to scale better with additional data and compute. Our results suggest MaxRL is a promising framework for scaling RL training in correctness based settings.
Shrinking the Variance: Shrinkage Baselines for Reinforcement Learning with Verifiable Rewards
Nov 05, 2025Reinforcement Learning with Verifiable Rewards (RLVR) has emerged as a powerful paradigm for post-training large reasoning models (LRMs) using policy-gradient methods such as GRPO. To stabilize training, these methods typically center trajectory rewards by subtracting the empirical mean for each prompt. Statistically, this centering acts as a control variate (or baseline), reducing the variance of the policy-gradient estimator. Typically, the mean reward is estimated using per-prompt empirical averages for each prompt in a batch. Drawing inspiration from Stein's paradox, we propose using shrinkage estimators that combine per-prompt and across-prompt means to improve the overall per-prompt mean estimation accuracy -- particularly in the low-generation regime typical of RLVR. Theoretically, we construct a shrinkage-based baseline that provably yields lower-variance policy-gradient estimators across algorithms. Our proposed baseline serves as a drop-in replacement for existing per-prompt mean baselines, requiring no additional hyper-parameters or computation. Empirically, shrinkage baselines consistently outperform standard empirical-mean baselines, leading to lower-variance gradient updates and improved training stability.
YOLO-Count: Differentiable Object Counting for Text-to-Image Generation
Aug 01, 2025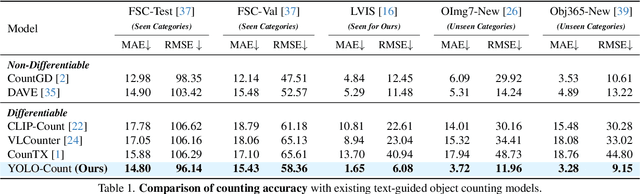
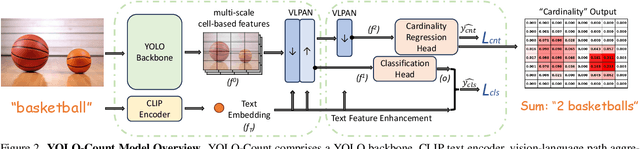
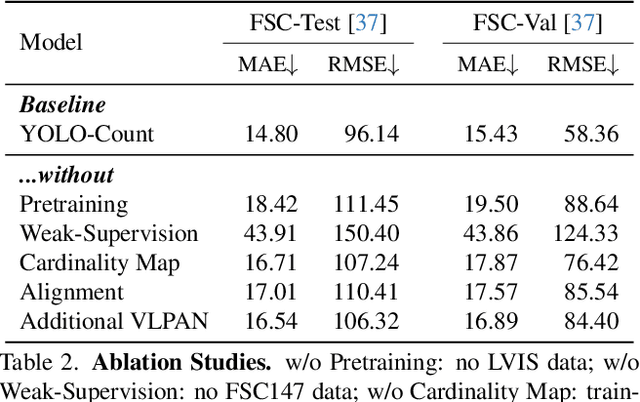
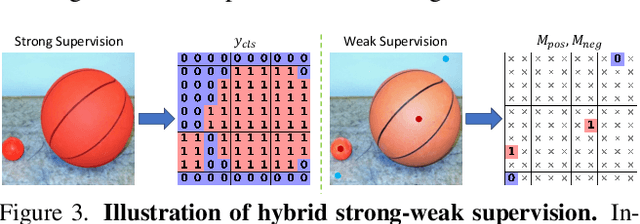
We propose YOLO-Count, a differentiable open-vocabulary object counting model that tackles both general counting challenges and enables precise quantity control for text-to-image (T2I) generation. A core contribution is the 'cardinality' map, a novel regression target that accounts for variations in object size and spatial distribution. Leveraging representation alignment and a hybrid strong-weak supervision scheme, YOLO-Count bridges the gap between open-vocabulary counting and T2I generation control. Its fully differentiable architecture facilitates gradient-based optimization, enabling accurate object count estimation and fine-grained guidance for generative models. Extensive experiments demonstrate that YOLO-Count achieves state-of-the-art counting accuracy while providing robust and effective quantity control for T2I systems.
Natural Language Induced Adversarial Images
Oct 11, 2024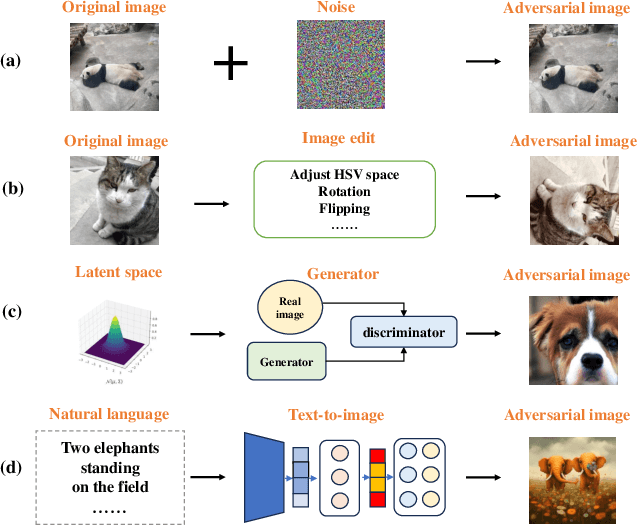

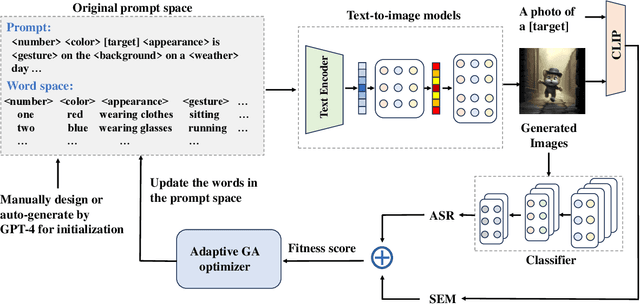

Research of adversarial attacks is important for AI security because it shows the vulnerability of deep learning models and helps to build more robust models. Adversarial attacks on images are most widely studied, which include noise-based attacks, image editing-based attacks, and latent space-based attacks. However, the adversarial examples crafted by these methods often lack sufficient semantic information, making it challenging for humans to understand the failure modes of deep learning models under natural conditions. To address this limitation, we propose a natural language induced adversarial image attack method. The core idea is to leverage a text-to-image model to generate adversarial images given input prompts, which are maliciously constructed to lead to misclassification for a target model. To adopt commercial text-to-image models for synthesizing more natural adversarial images, we propose an adaptive genetic algorithm (GA) for optimizing discrete adversarial prompts without requiring gradients and an adaptive word space reduction method for improving query efficiency. We further used CLIP to maintain the semantic consistency of the generated images. In our experiments, we found that some high-frequency semantic information such as "foggy", "humid", "stretching", etc. can easily cause classifier errors. This adversarial semantic information exists not only in generated images but also in photos captured in the real world. We also found that some adversarial semantic information can be transferred to unknown classification tasks. Furthermore, our attack method can transfer to different text-to-image models (e.g., Midjourney, DALL-E 3, etc.) and image classifiers. Our code is available at: https://github.com/zxp555/Natural-Language-Induced-Adversarial-Images.
ImageNet3D: Towards General-Purpose Object-Level 3D Understanding
Jun 13, 2024
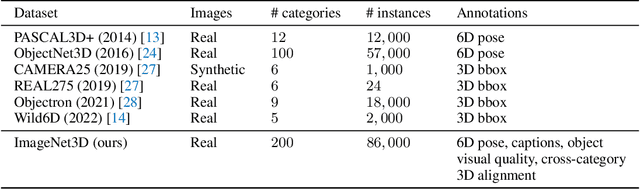

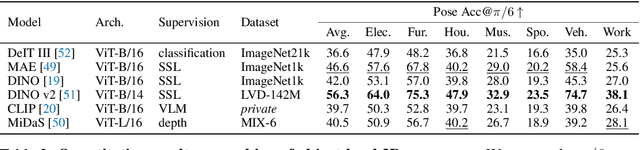
A vision model with general-purpose object-level 3D understanding should be capable of inferring both 2D (e.g., class name and bounding box) and 3D information (e.g., 3D location and 3D viewpoint) for arbitrary rigid objects in natural images. This is a challenging task, as it involves inferring 3D information from 2D signals and most importantly, generalizing to rigid objects from unseen categories. However, existing datasets with object-level 3D annotations are often limited by the number of categories or the quality of annotations. Models developed on these datasets become specialists for certain categories or domains, and fail to generalize. In this work, we present ImageNet3D, a large dataset for general-purpose object-level 3D understanding. ImageNet3D augments 200 categories from the ImageNet dataset with 2D bounding box, 3D pose, 3D location annotations, and image captions interleaved with 3D information. With the new annotations available in ImageNet3D, we could (i) analyze the object-level 3D awareness of visual foundation models, and (ii) study and develop general-purpose models that infer both 2D and 3D information for arbitrary rigid objects in natural images, and (iii) integrate unified 3D models with large language models for 3D-related reasoning.. We consider two new tasks, probing of object-level 3D awareness and open vocabulary pose estimation, besides standard classification and pose estimation. Experimental results on ImageNet3D demonstrate the potential of our dataset in building vision models with stronger general-purpose object-level 3D understanding.
VideoDreamer: Customized Multi-Subject Text-to-Video Generation with Disen-Mix Finetuning
Nov 02, 2023Customized text-to-video generation aims to generate text-guided videos with customized user-given subjects, which has gained increasing attention recently. However, existing works are primarily limited to generating videos for a single subject, leaving the more challenging problem of customized multi-subject text-to-video generation largely unexplored. In this paper, we fill this gap and propose a novel VideoDreamer framework. VideoDreamer can generate temporally consistent text-guided videos that faithfully preserve the visual features of the given multiple subjects. Specifically, VideoDreamer leverages the pretrained Stable Diffusion with latent-code motion dynamics and temporal cross-frame attention as the base video generator. The video generator is further customized for the given multiple subjects by the proposed Disen-Mix Finetuning and Human-in-the-Loop Re-finetuning strategy, which can tackle the attribute binding problem of multi-subject generation. We also introduce MultiStudioBench, a benchmark for evaluating customized multi-subject text-to-video generation models. Extensive experiments demonstrate the remarkable ability of VideoDreamer to generate videos with new content such as new events and backgrounds, tailored to the customized multiple subjects. Our project page is available at https://videodreamer23.github.io/.