 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMMDT: Decoding the Trustworthiness and Safety of Multimodal Foundation Models
Mar 19, 2025Multimodal foundation models (MMFMs) play a crucial role in various applications, including autonomous driving, healthcare, and virtual assistants. However, several studies have revealed vulnerabilities in these models, such as generating unsafe content by text-to-image models. Existing benchmarks on multimodal models either predominantly assess the helpfulness of these models, or only focus on limited perspectives such as fairness and privacy. In this paper, we present the first unified platform, MMDT (Multimodal DecodingTrust), designed to provide a comprehensive safety and trustworthiness evaluation for MMFMs. Our platform assesses models from multiple perspectives, including safety, hallucination, fairness/bias, privacy, adversarial robustness, and out-of-distribution (OOD) generalization. We have designed various evaluation scenarios and red teaming algorithms under different tasks for each perspective to generate challenging data, forming a high-quality benchmark. We evaluate a range of multimodal models using MMDT, and our findings reveal a series of vulnerabilities and areas for improvement across these perspectives. This work introduces the first comprehensive and unique safety and trustworthiness evaluation platform for MMFMs, paving the way for developing safer and more reliable MMFMs and systems. Our platform and benchmark are available at https://mmdecodingtrust.github.io/.
Natural Language Induced Adversarial Images
Oct 11, 2024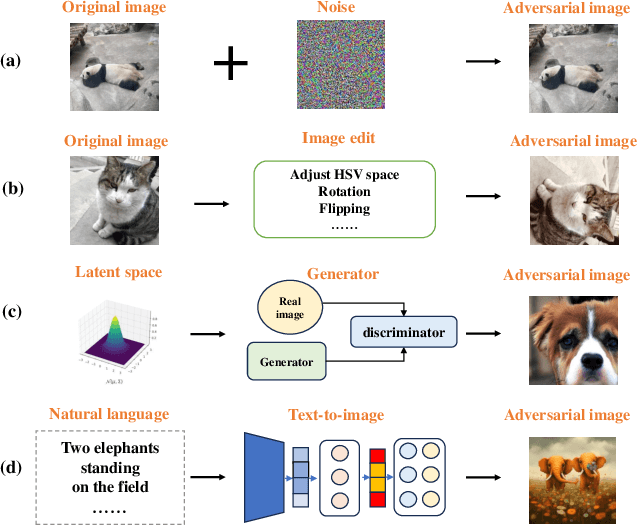

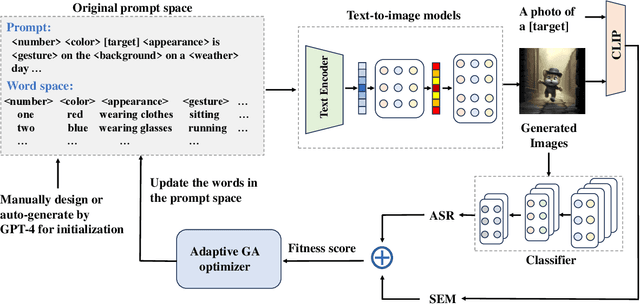

Research of adversarial attacks is important for AI security because it shows the vulnerability of deep learning models and helps to build more robust models. Adversarial attacks on images are most widely studied, which include noise-based attacks, image editing-based attacks, and latent space-based attacks. However, the adversarial examples crafted by these methods often lack sufficient semantic information, making it challenging for humans to understand the failure modes of deep learning models under natural conditions. To address this limitation, we propose a natural language induced adversarial image attack method. The core idea is to leverage a text-to-image model to generate adversarial images given input prompts, which are maliciously constructed to lead to misclassification for a target model. To adopt commercial text-to-image models for synthesizing more natural adversarial images, we propose an adaptive genetic algorithm (GA) for optimizing discrete adversarial prompts without requiring gradients and an adaptive word space reduction method for improving query efficiency. We further used CLIP to maintain the semantic consistency of the generated images. In our experiments, we found that some high-frequency semantic information such as "foggy", "humid", "stretching", etc. can easily cause classifier errors. This adversarial semantic information exists not only in generated images but also in photos captured in the real world. We also found that some adversarial semantic information can be transferred to unknown classification tasks. Furthermore, our attack method can transfer to different text-to-image models (e.g., Midjourney, DALL-E 3, etc.) and image classifiers. Our code is available at: https://github.com/zxp555/Natural-Language-Induced-Adversarial-Images.