 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArchPilot: A Proxy-Guided Multi-Agent Approach for Machine Learning Engineering
Nov 06, 2025Recent LLM-based agents have demonstrated strong capabilities in automated ML engineering. However, they heavily rely on repeated full training runs to evaluate candidate solutions, resulting in significant computational overhead, limited scalability to large search spaces, and slow iteration cycles. To address these challenges, we introduce ArchPilot, a multi-agent system that integrates architecture generation, proxy-based evaluation, and adaptive search into a unified framework. ArchPilot consists of three specialized agents: an orchestration agent that coordinates the search process using a Monte Carlo Tree Search (MCTS)-inspired novel algorithm with a restart mechanism and manages memory of previous candidates; a generation agent that iteratively generates, improves, and debugs candidate architectures; and an evaluation agent that executes proxy training runs, generates and optimizes proxy functions, and aggregates the proxy scores into a fidelity-aware performance metric. This multi-agent collaboration allows ArchPilot to prioritize high-potential candidates with minimal reliance on expensive full training runs, facilitating efficient ML engineering under limited budgets. Experiments on MLE-Bench demonstrate that ArchPilot outperforms SOTA baselines such as AIDE and ML-Master, validating the effectiveness of our multi-agent system.
MMDT: Decoding the Trustworthiness and Safety of Multimodal Foundation Models
Mar 19, 2025Multimodal foundation models (MMFMs) play a crucial role in various applications, including autonomous driving, healthcare, and virtual assistants. However, several studies have revealed vulnerabilities in these models, such as generating unsafe content by text-to-image models. Existing benchmarks on multimodal models either predominantly assess the helpfulness of these models, or only focus on limited perspectives such as fairness and privacy. In this paper, we present the first unified platform, MMDT (Multimodal DecodingTrust), designed to provide a comprehensive safety and trustworthiness evaluation for MMFMs. Our platform assesses models from multiple perspectives, including safety, hallucination, fairness/bias, privacy, adversarial robustness, and out-of-distribution (OOD) generalization. We have designed various evaluation scenarios and red teaming algorithms under different tasks for each perspective to generate challenging data, forming a high-quality benchmark. We evaluate a range of multimodal models using MMDT, and our findings reveal a series of vulnerabilities and areas for improvement across these perspectives. This work introduces the first comprehensive and unique safety and trustworthiness evaluation platform for MMFMs, paving the way for developing safer and more reliable MMFMs and systems. Our platform and benchmark are available at https://mmdecodingtrust.github.io/.
RigorLLM: Resilient Guardrails for Large Language Models against Undesired Content
Mar 19, 2024Recent advancements in Large Language Models (LLMs) have showcased remarkable capabilities across various tasks in different domains. However, the emergence of biases and the potential for generating harmful content in LLMs, particularly under malicious inputs, pose significant challenges. Current mitigation strategies, while effective, are not resilient under adversarial attacks. This paper introduces Resilient Guardrails for Large Language Models (RigorLLM), a novel framework designed to efficiently and effectively moderate harmful and unsafe inputs and outputs for LLMs. By employing a multi-faceted approach that includes energy-based training data augmentation through Langevin dynamics, optimizing a safe suffix for inputs via minimax optimization, and integrating a fusion-based model combining robust KNN with LLMs based on our data augmentation, RigorLLM offers a robust solution to harmful content moderation. Our experimental evaluations demonstrate that RigorLLM not only outperforms existing baselines like OpenAI API and Perspective API in detecting harmful content but also exhibits unparalleled resilience to jailbreaking attacks. The innovative use of constrained optimization and a fusion-based guardrail approach represents a significant step forward in developing more secure and reliable LLMs, setting a new standard for content moderation frameworks in the face of evolving digital threats.
SecretGen: Privacy Recovery on Pre-Trained Models via Distribution Discrimination
Jul 25, 2022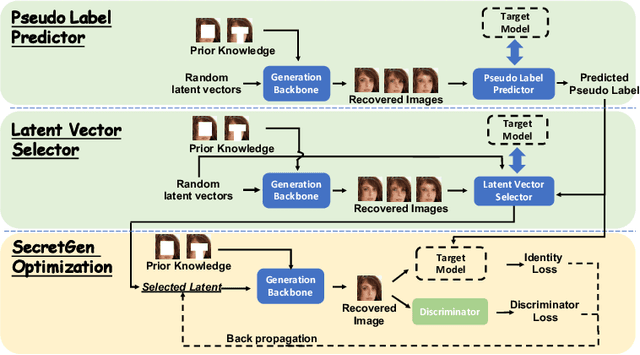

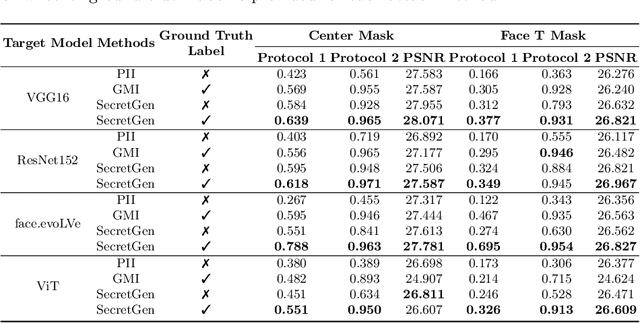
Transfer learning through the use of pre-trained models has become a growing trend for the machine learning community. Consequently, numerous pre-trained models are released online to facilitate further research. However, it raises extensive concerns on whether these pre-trained models would leak privacy-sensitive information of their training data. Thus, in this work, we aim to answer the following questions: "Can we effectively recover private information from these pre-trained models? What are the sufficient conditions to retrieve such sensitive information?" We first explore different statistical information which can discriminate the private training distribution from other distributions. Based on our observations, we propose a novel private data reconstruction framework, SecretGen, to effectively recover private information. Compared with previous methods which can recover private data with the ground true prediction of the targeted recovery instance, SecretGen does not require such prior knowledge, making it more practical. We conduct extensive experiments on different datasets under diverse scenarios to compare SecretGen with other baselines and provide a systematic benchmark to better understand the impact of different auxiliary information and optimization operations. We show that without prior knowledge about true class prediction, SecretGen is able to recover private data with similar performance compared with the ones that leverage such prior knowledge. If the prior knowledge is given, SecretGen will significantly outperform baseline methods. We also propose several quantitative metrics to further quantify the privacy vulnerability of pre-trained models, which will help the model selection for privacy-sensitive applications. Our code is available at: https://github.com/AI-secure/SecretGen.
On Generating Identifiable Virtual Faces
Oct 15, 2021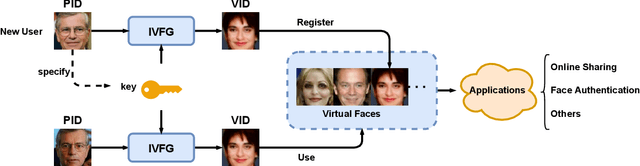


Face anonymization with generative models have become increasingly prevalent since they sanitize private information by generating virtual face images, ensuring both privacy and image utility. Such virtual face images are usually not identifiable after the removal or protection of the original identity. In this paper, we formalize and tackle the problem of generating identifiable virtual face images. Our virtual face images are visually different from the original ones for privacy protection. In addition, they are bound with new virtual identities, which can be directly used for face recognition. We propose an Identifiable Virtual Face Generator (IVFG) to generate the virtual face images. The IVFG projects the latent vectors of the original face images into virtual ones according to a user specific key, based on which the virtual face images are generated. To make the virtual face images identifiable, we propose a multi-task learning objective as well as a triplet styled training strategy to learn the IVFG. Various experiments demonstrate the effectiveness of the IVFG for generate identifiable virtual face images.