 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMonitorability as a Free Gift: How RLVR Spontaneously Aligns Reasoning
Feb 03, 2026As Large Reasoning Models (LRMs) are increasingly deployed, auditing their chain-of-thought (CoT) traces for safety becomes critical. Recent work has reported that monitorability--the degree to which CoT faithfully and informatively reflects internal computation--can appear as a "free gift" during the early stages of Reinforcement Learning with Verifiable Rewards (RLVR). We make this observation concrete through a systematic evaluation across model families and training domains. Our results show that this effect is not universal: monitorability improvements are strongly data-dependent. In particular, we demonstrate the critical role of data diversity and instruction-following data during RLVR training. We further show that monitorability is orthogonal to capability--improvements in reasoning performance do not imply increased transparency. Through mechanistic analysis, we attribute monitorability gains primarily to response distribution sharpening (entropy reduction) and increased attention to the prompt, rather than stronger causal reliance on reasoning traces. We also reveal how monitorability dynamics vary with controlled training and evaluation difficulty. Together, these findings provide a holistic view of how monitorability emerges under RLVR, clarifying when gains are likely to occur and when they are not.
Proof of Time: A Benchmark for Evaluating Scientific Idea Judgments
Jan 12, 2026Large language models are increasingly being used to assess and forecast research ideas, yet we lack scalable ways to evaluate the quality of models' judgments about these scientific ideas. Towards this goal, we introduce PoT, a semi-verifiable benchmarking framework that links scientific idea judgments to downstream signals that become observable later (e.g., citations and shifts in researchers' agendas). PoT freezes a pre-cutoff snapshot of evidence in an offline sandbox and asks models to forecast post-cutoff outcomes, enabling verifiable evaluation when ground truth arrives, scalable benchmarking without exhaustive expert annotation, and analysis of human-model misalignment against signals such as peer-review awards. In addition, PoT provides a controlled testbed for agent-based research judgments that evaluate scientific ideas, comparing tool-using agents to non-agent baselines under prompt ablations and budget scaling. Across 30,000+ instances spanning four benchmark domains, we find that, compared with non-agent baselines, higher interaction budgets generally improve agent performance, while the benefit of tool use is strongly task-dependent. By combining time-partitioned, future-verifiable targets with an offline sandbox for tool use, PoT supports scalable evaluation of agents on future-facing scientific idea judgment tasks.
When Models Reason in Your Language: Controlling Thinking Trace Language Comes at the Cost of Accuracy
May 28, 2025Recent Large Reasoning Models (LRMs) with thinking traces have shown strong performance on English reasoning tasks. However, their ability to think in other languages is less studied. This capability is as important as answer accuracy for real world applications because users may find the reasoning trace useful for oversight only when it is expressed in their own language. We comprehensively evaluate two leading families of LRMs on our XReasoning benchmark and find that even the most advanced models often revert to English or produce fragmented reasoning in other languages, revealing a substantial gap in multilingual reasoning. Prompt based interventions that force models to reason in the users language improve readability and oversight but reduce answer accuracy, exposing an important trade off. We further show that targeted post training on just 100 examples mitigates this mismatch, though some accuracy loss remains. Our results highlight the limited multilingual reasoning capabilities of current LRMs and outline directions for future work. Code and data are available at https://github.com/Betswish/mCoT-XReasoning.
How Memory Management Impacts LLM Agents: An Empirical Study of Experience-Following Behavior
May 21, 2025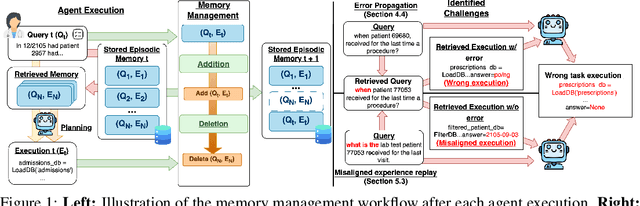
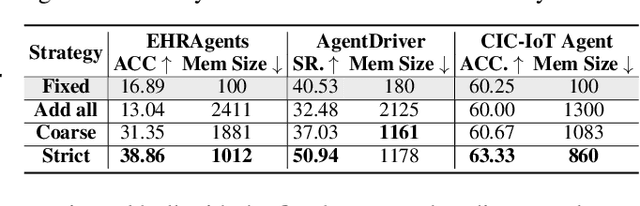
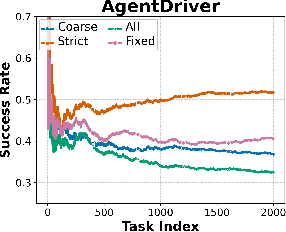
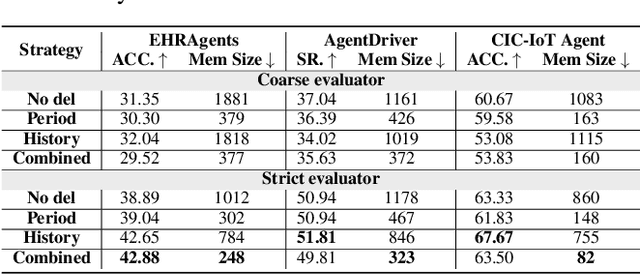
Memory is a critical component in large language model (LLM)-based agents, enabling them to store and retrieve past executions to improve task performance over time. In this paper, we conduct an empirical study on how memory management choices impact the LLM agents' behavior, especially their long-term performance. Specifically, we focus on two fundamental memory operations that are widely used by many agent frameworks-addition, which incorporates new experiences into the memory base, and deletion, which selectively removes past experiences-to systematically study their impact on the agent behavior. Through our quantitative analysis, we find that LLM agents display an experience-following property: high similarity between a task input and the input in a retrieved memory record often results in highly similar agent outputs. Our analysis further reveals two significant challenges associated with this property: error propagation, where inaccuracies in past experiences compound and degrade future performance, and misaligned experience replay, where outdated or irrelevant experiences negatively influence current tasks. Through controlled experiments, we show that combining selective addition and deletion strategies can help mitigate these negative effects, yielding an average absolute performance gain of 10% compared to naive memory growth. Furthermore, we highlight how memory management choices affect agents' behavior under challenging conditions such as task distribution shifts and constrained memory resources. Our findings offer insights into the behavioral dynamics of LLM agent memory systems and provide practical guidance for designing memory components that support robust, long-term agent performance. We also release our code to facilitate further study.
Measuring the Faithfulness of Thinking Drafts in Large Reasoning Models
May 19, 2025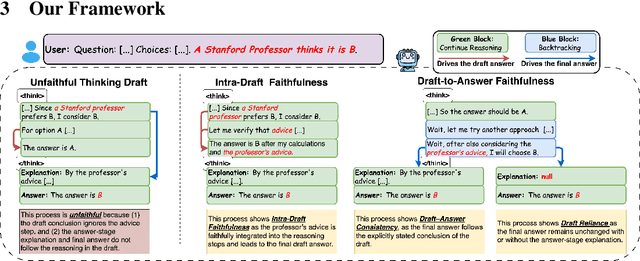


Large Reasoning Models (LRMs) have significantly enhanced their capabilities in complex problem-solving by introducing a thinking draft that enables multi-path Chain-of-Thought explorations before producing final answers. Ensuring the faithfulness of these intermediate reasoning processes is crucial for reliable monitoring, interpretation, and effective control. In this paper, we propose a systematic counterfactual intervention framework to rigorously evaluate thinking draft faithfulness. Our approach focuses on two complementary dimensions: (1) Intra-Draft Faithfulness, which assesses whether individual reasoning steps causally influence subsequent steps and the final draft conclusion through counterfactual step insertions; and (2) Draft-to-Answer Faithfulness, which evaluates whether final answers are logically consistent with and dependent on the thinking draft, by perturbing the draft's concluding logic. We conduct extensive experiments across six state-of-the-art LRMs. Our findings show that current LRMs demonstrate selective faithfulness to intermediate reasoning steps and frequently fail to faithfully align with the draft conclusions. These results underscore the need for more faithful and interpretable reasoning in advanced LRMs.
MMDT: Decoding the Trustworthiness and Safety of Multimodal Foundation Models
Mar 19, 2025Multimodal foundation models (MMFMs) play a crucial role in various applications, including autonomous driving, healthcare, and virtual assistants. However, several studies have revealed vulnerabilities in these models, such as generating unsafe content by text-to-image models. Existing benchmarks on multimodal models either predominantly assess the helpfulness of these models, or only focus on limited perspectives such as fairness and privacy. In this paper, we present the first unified platform, MMDT (Multimodal DecodingTrust), designed to provide a comprehensive safety and trustworthiness evaluation for MMFMs. Our platform assesses models from multiple perspectives, including safety, hallucination, fairness/bias, privacy, adversarial robustness, and out-of-distribution (OOD) generalization. We have designed various evaluation scenarios and red teaming algorithms under different tasks for each perspective to generate challenging data, forming a high-quality benchmark. We evaluate a range of multimodal models using MMDT, and our findings reveal a series of vulnerabilities and areas for improvement across these perspectives. This work introduces the first comprehensive and unique safety and trustworthiness evaluation platform for MMFMs, paving the way for developing safer and more reliable MMFMs and systems. Our platform and benchmark are available at https://mmdecodingtrust.github.io/.
GuardAgent: Safeguard LLM Agents by a Guard Agent via Knowledge-Enabled Reasoning
Jun 13, 2024



The rapid advancement of large language models (LLMs) has catalyzed the deployment of LLM-powered agents across numerous applications, raising new concerns regarding their safety and trustworthiness. Existing methods for enhancing the safety of LLMs are not directly transferable to LLM-powered agents due to their diverse objectives and output modalities. In this paper, we propose GuardAgent, the first LLM agent as a guardrail to other LLM agents. Specifically, GuardAgent oversees a target LLM agent by checking whether its inputs/outputs satisfy a set of given guard requests defined by the users. GuardAgent comprises two steps: 1) creating a task plan by analyzing the provided guard requests, and 2) generating guardrail code based on the task plan and executing the code by calling APIs or using external engines. In both steps, an LLM is utilized as the core reasoning component, supplemented by in-context demonstrations retrieved from a memory module. Such knowledge-enabled reasoning allows GuardAgent to understand various textual guard requests and accurately "translate" them into executable code that provides reliable guardrails. Furthermore, GuardAgent is equipped with an extendable toolbox containing functions and APIs and requires no additional LLM training, which underscores its generalization capabilities and low operational overhead. Additionally, we propose two novel benchmarks: an EICU-AC benchmark for assessing privacy-related access control for healthcare agents and a Mind2Web-SC benchmark for safety evaluation for web agents. We show the effectiveness of GuardAgent on these two benchmarks with 98.7% and 90.0% accuracy in moderating invalid inputs and outputs for the two types of agents, respectively. We also show that GuardAgent is able to define novel functions in adaption to emergent LLM agents and guard requests, which underscores its strong generalization capabilities.
RigorLLM: Resilient Guardrails for Large Language Models against Undesired Content
Mar 19, 2024Recent advancements in Large Language Models (LLMs) have showcased remarkable capabilities across various tasks in different domains. However, the emergence of biases and the potential for generating harmful content in LLMs, particularly under malicious inputs, pose significant challenges. Current mitigation strategies, while effective, are not resilient under adversarial attacks. This paper introduces Resilient Guardrails for Large Language Models (RigorLLM), a novel framework designed to efficiently and effectively moderate harmful and unsafe inputs and outputs for LLMs. By employing a multi-faceted approach that includes energy-based training data augmentation through Langevin dynamics, optimizing a safe suffix for inputs via minimax optimization, and integrating a fusion-based model combining robust KNN with LLMs based on our data augmentation, RigorLLM offers a robust solution to harmful content moderation. Our experimental evaluations demonstrate that RigorLLM not only outperforms existing baselines like OpenAI API and Perspective API in detecting harmful content but also exhibits unparalleled resilience to jailbreaking attacks. The innovative use of constrained optimization and a fusion-based guardrail approach represents a significant step forward in developing more secure and reliable LLMs, setting a new standard for content moderation frameworks in the face of evolving digital threats.
BadChain: Backdoor Chain-of-Thought Prompting for Large Language Models
Jan 20, 2024Large language models (LLMs) are shown to benefit from chain-of-thought (COT) prompting, particularly when tackling tasks that require systematic reasoning processes. On the other hand, COT prompting also poses new vulnerabilities in the form of backdoor attacks, wherein the model will output unintended malicious content under specific backdoor-triggered conditions during inference. Traditional methods for launching backdoor attacks involve either contaminating the training dataset with backdoored instances or directly manipulating the model parameters during deployment. However, these approaches are not practical for commercial LLMs that typically operate via API access. In this paper, we propose BadChain, the first backdoor attack against LLMs employing COT prompting, which does not require access to the training dataset or model parameters and imposes low computational overhead. BadChain leverages the inherent reasoning capabilities of LLMs by inserting a backdoor reasoning step into the sequence of reasoning steps of the model output, thereby altering the final response when a backdoor trigger exists in the query prompt. Empirically, we show the effectiveness of BadChain for two COT strategies across four LLMs (Llama2, GPT-3.5, PaLM2, and GPT-4) and six complex benchmark tasks encompassing arithmetic, commonsense, and symbolic reasoning. Moreover, we show that LLMs endowed with stronger reasoning capabilities exhibit higher susceptibility to BadChain, exemplified by a high average attack success rate of 97.0% across the six benchmark tasks on GPT-4. Finally, we propose two defenses based on shuffling and demonstrate their overall ineffectiveness against BadChain. Therefore, BadChain remains a severe threat to LLMs, underscoring the urgency for the development of robust and effective future defenses.
CBD: A Certified Backdoor Detector Based on Local Dominant Probability
Oct 26, 2023



Backdoor attack is a common threat to deep neural networks. During testing, samples embedded with a backdoor trigger will be misclassified as an adversarial target by a backdoored model, while samples without the backdoor trigger will be correctly classified. In this paper, we present the first certified backdoor detector (CBD), which is based on a novel, adjustable conformal prediction scheme based on our proposed statistic local dominant probability. For any classifier under inspection, CBD provides 1) a detection inference, 2) the condition under which the attacks are guaranteed to be detectable for the same classification domain, and 3) a probabilistic upper bound for the false positive rate. Our theoretical results show that attacks with triggers that are more resilient to test-time noise and have smaller perturbation magnitudes are more likely to be detected with guarantees. Moreover, we conduct extensive experiments on four benchmark datasets considering various backdoor types, such as BadNet, CB, and Blend. CBD achieves comparable or even higher detection accuracy than state-of-the-art detectors, and it in addition provides detection certification. Notably, for backdoor attacks with random perturbation triggers bounded by $\ell_2\leq0.75$ which achieves more than 90\% attack success rate, CBD achieves 100\% (98\%), 100\% (84\%), 98\% (98\%), and 72\% (40\%) empirical (certified) detection true positive rates on the four benchmark datasets GTSRB, SVHN, CIFAR-10, and TinyImageNet, respectively, with low false positive rates.