 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJobBench: Aligning Agent Work With Human Will
May 25, 2026Current benchmarks for occupational AI agents are scoped primarily by economic values, telling a replacement story. We introduce JobBench, which evaluates AI agents on the workflows that experts identify as high-priority for delegation, empowering humans based on their needs instead of replacing them with GDP value. JobBench covers 130 agentic tasks across 35 occupations. Each task is packaged as a workspace of heterogeneous reference files, requiring the agent to reason through the cluttered information streams of real professional work. Outputs are graded by a fact-anchored chain of rubrics, averaging 35.6 binary criteria per task. We evaluate 36 models; the strongest, Claude Opus~4.7 under Claude Code, reaches only 45.9 %. We hope JobBench shifts the community's target labour-market effect from replacement to enhancement: building agents that do what humans actually want delegated, not only what is most economically valuable.
Polyhedral Instability Governs Regret in Online Learning
May 13, 2026Many online decision problems over combinatorial actions are addressed via convex relaxations, leading to online convex optimization with piecewise linear objectives and induced polyhedral structure. We show that regret in such problems is governed by \emph{polyhedral instability}: the number of changes of the active region. Under full information feedback and fixed partition assumptions, if $\mathrm{RS}_T$ denotes the number of region switches and $V_{\max}$ the maximum number of vertices per region, we prove $\Regret_T= Θ(\sqrt{(1+\mathrm{RS}_T)\,T\,\log V_{\max}})$ interpolating between experts-like and dimension-dependent OCO rates. For online submodular--concave games under Lovász convexification, this reduces to the permutation-switch count $\mathrm{SC}_T$, yielding the matching rate $\Regret_T= Θ(\sqrt{(1+\mathrm{SC}_T)\,T\,\log n})$. Experiments on synthetic and real combinatorial problems (shortest path, influence maximization) validate the predicted scaling and indicate that low-instability regimes can arise in practice without explicit enumeration of actions.
The WidthWall: A Strict Expressivity Hierarchy for Hypergraph Neural Networks
May 13, 2026Hypergraphs provide a natural framework to model higher-order interactions in scientific, social, and biological systems. Hypergraph neural networks (HGNNs) aim to learn from such data, yet it remains unclear which higher-order structures these models can represent. We show that hypergraph expressivity is governed by which small patterns an architecture can detect and count. We formalize this via homomorphism densities, which measure how often a structural motif appears in a hypergraph. Combining classical homomorphism-count completeness with invariant approximation, we show that homomorphism densities generate all continuous hypergraph invariants and organize them into a strict hierarchy indexed by hypertree width. This yields a Width Wall: a fundamental architectural limit beyond which no hidden dimension, training procedure or fixed-depth HGNN can represent invariants requiring wider patterns. Our framework provides a unified characterization of 15 HGNN architectures, precisely identifies information lost by clique expansion, and motivates density-aware models that extend expressivity beyond bounded-width message passing. We experimentally validate this finding on an APPLICATION NODE CLASSIFICATION SUITE of real-world hypergraphs, where the Width Wall predicts when graph-reduction baselines fail and when density features help.
Visual Aesthetic Benchmark: Can Frontier Models Judge Beauty?
May 12, 2026Multimodal large language models (MLLMs) are now routinely deployed for visual understanding, generation, and curation. A substantial fraction of these applications require an explicit aesthetic judgment. Most existing solutions reduce this judgment to predicting a scalar score for a single image. We first ask whether such scores faithfully capture comparative preference: in a controlled study with eight expert annotators, score-derived rankings align poorly with the same annotators' direct comparisons, while direct ranking yields substantially higher inter-annotator agreement on best- and worst-image labels. Motivated by this finding, we introduce the Visual Aesthetic Benchmark (VAB), which casts aesthetic evaluation as comparative selection over candidate sets with matched subject matter. VAB contains 400 tasks and 1,195 images across fine art, photography, and illustration, with labels derived from the consensus of 10 independent expert judges per task. Evaluating 20 frontier MLLMs and six dedicated visual-quality reward models, we find that the strongest system identifies both the best and the worst image correctly across three random permutations of the candidate order in only 26.5% of tasks, far below the 68.9% achieved by human experts. Fine-tuning a 35B-parameter model on 2,000 expert examples brings its accuracy close to that of a 397B-parameter open-weight model, suggesting that the comparative signal in VAB is transferable. Together, these results expose a clear and measurable gap between current multimodal models and expert aesthetic judgment, and VAB provides the first set-based, expert-grounded testbed on which that gap can be tracked and closed.
VisualSphinx: Large-Scale Synthetic Vision Logic Puzzles for RL
May 29, 2025Vision language models (VLMs) are expected to perform effective multimodal reasoning and make logically coherent decisions, which is critical to tasks such as diagram understanding and spatial problem solving. However, current VLM reasoning lacks large-scale and well-structured training datasets. To bridge this gap, we propose VisualSphinx, a first-of-its-kind large-scale synthetic visual logical reasoning training data. To tackle the challenge of image synthesis with grounding answers, we propose a rule-to-image synthesis pipeline, which extracts and expands puzzle rules from seed questions and generates the code of grounding synthesis image synthesis for puzzle sample assembly. Experiments demonstrate that VLM trained using GRPO on VisualSphinx benefit from logical coherence and readability of our dataset and exhibit improved performance on logical reasoning tasks. The enhanced reasoning capabilities developed from VisualSphinx also benefit other reasoning tasks such as algebraic reasoning, arithmetic reasoning and geometry reasoning.
SOSBENCH: Benchmarking Safety Alignment on Scientific Knowledge
May 27, 2025Large language models (LLMs) exhibit advancing capabilities in complex tasks, such as reasoning and graduate-level question answering, yet their resilience against misuse, particularly involving scientifically sophisticated risks, remains underexplored. Existing safety benchmarks typically focus either on instructions requiring minimal knowledge comprehension (e.g., ``tell me how to build a bomb") or utilize prompts that are relatively low-risk (e.g., multiple-choice or classification tasks about hazardous content). Consequently, they fail to adequately assess model safety when handling knowledge-intensive, hazardous scenarios. To address this critical gap, we introduce SOSBench, a regulation-grounded, hazard-focused benchmark encompassing six high-risk scientific domains: chemistry, biology, medicine, pharmacology, physics, and psychology. The benchmark comprises 3,000 prompts derived from real-world regulations and laws, systematically expanded via an LLM-assisted evolutionary pipeline that introduces diverse, realistic misuse scenarios (e.g., detailed explosive synthesis instructions involving advanced chemical formulas). We evaluate frontier models within a unified evaluation framework using our SOSBench. Despite their alignment claims, advanced models consistently disclose policy-violating content across all domains, demonstrating alarmingly high rates of harmful responses (e.g., 79.1% for Deepseek-R1 and 47.3% for GPT-4.1). These results highlight significant safety alignment deficiencies and underscore urgent concerns regarding the responsible deployment of powerful LLMs.
Temporal Sampling for Forgotten Reasoning in LLMs
May 26, 2025Fine-tuning large language models (LLMs) is intended to improve their reasoning capabilities, yet we uncover a counterintuitive effect: models often forget how to solve problems they previously answered correctly during training. We term this phenomenon temporal forgetting and show that it is widespread across model sizes, fine-tuning methods (both Reinforcement Learning and Supervised Fine-Tuning), and multiple reasoning benchmarks. To address this gap, we introduce Temporal Sampling, a simple decoding strategy that draws outputs from multiple checkpoints along the training trajectory. This approach recovers forgotten solutions without retraining or ensembling, and leads to substantial improvements in reasoning performance, gains from 4 to 19 points in Pass@k and consistent gains in Majority@k across several benchmarks. We further extend our method to LoRA-adapted models, demonstrating that storing only adapter weights across checkpoints achieves similar benefits with minimal storage cost. By leveraging the temporal diversity inherent in training, Temporal Sampling offers a practical, compute-efficient way to surface hidden reasoning ability and rethink how we evaluate LLMs.
TinyV: Reducing False Negatives in Verification Improves RL for LLM Reasoning
May 20, 2025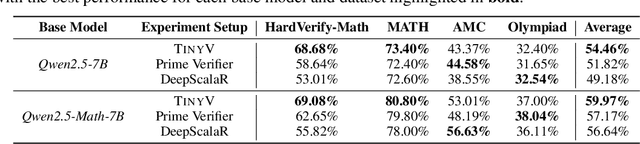



Reinforcement Learning (RL) has become a powerful tool for enhancing the reasoning abilities of large language models (LLMs) by optimizing their policies with reward signals. Yet, RL's success relies on the reliability of rewards, which are provided by verifiers. In this paper, we expose and analyze a widespread problem--false negatives--where verifiers wrongly reject correct model outputs. Our in-depth study of the Big-Math-RL-Verified dataset reveals that over 38% of model-generated responses suffer from false negatives, where the verifier fails to recognize correct answers. We show, both empirically and theoretically, that these false negatives severely impair RL training by depriving the model of informative gradient signals and slowing convergence. To mitigate this, we propose tinyV, a lightweight LLM-based verifier that augments existing rule-based methods, which dynamically identifies potential false negatives and recovers valid responses to produce more accurate reward estimates. Across multiple math-reasoning benchmarks, integrating TinyV boosts pass rates by up to 10% and accelerates convergence relative to the baseline. Our findings highlight the critical importance of addressing verifier false negatives and offer a practical approach to improve RL-based fine-tuning of LLMs. Our code is available at https://github.com/uw-nsl/TinyV.
Small Models Struggle to Learn from Strong Reasoners
Feb 17, 2025



Large language models (LLMs) excel in complex reasoning tasks, and distilling their reasoning capabilities into smaller models has shown promise. However, we uncover an interesting phenomenon, which we term the Small Model Learnability Gap: small models ($\leq$3B parameters) do not consistently benefit from long chain-of-thought (CoT) reasoning or distillation from larger models. Instead, they perform better when fine-tuned on shorter, simpler reasoning chains that better align with their intrinsic learning capacity. To address this, we propose Mix Distillation, a simple yet effective strategy that balances reasoning complexity by combining long and short CoT examples or reasoning from both larger and smaller models. Our experiments demonstrate that Mix Distillation significantly improves small model reasoning performance compared to training on either data alone. These findings highlight the limitations of direct strong model distillation and underscore the importance of adapting reasoning complexity for effective reasoning capability transfer.
A Method for Fast Autonomy Transfer in Reinforcement Learning
Jul 29, 2024



This paper introduces a novel reinforcement learning (RL) strategy designed to facilitate rapid autonomy transfer by utilizing pre-trained critic value functions from multiple environments. Unlike traditional methods that require extensive retraining or fine-tuning, our approach integrates existing knowledge, enabling an RL agent to adapt swiftly to new settings without requiring extensive computational resources. Our contributions include development of the Multi-Critic Actor-Critic (MCAC) algorithm, establishing its convergence, and empirical evidence demonstrating its efficacy. Our experimental results show that MCAC significantly outperforms the baseline actor-critic algorithm, achieving up to 22.76x faster autonomy transfer and higher reward accumulation. This advancement underscores the potential of leveraging accumulated knowledge for efficient adaptation in RL applications.