 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Method for Fast Autonomy Transfer in Reinforcement Learning
Jul 29, 2024



This paper introduces a novel reinforcement learning (RL) strategy designed to facilitate rapid autonomy transfer by utilizing pre-trained critic value functions from multiple environments. Unlike traditional methods that require extensive retraining or fine-tuning, our approach integrates existing knowledge, enabling an RL agent to adapt swiftly to new settings without requiring extensive computational resources. Our contributions include development of the Multi-Critic Actor-Critic (MCAC) algorithm, establishing its convergence, and empirical evidence demonstrating its efficacy. Our experimental results show that MCAC significantly outperforms the baseline actor-critic algorithm, achieving up to 22.76x faster autonomy transfer and higher reward accumulation. This advancement underscores the potential of leveraging accumulated knowledge for efficient adaptation in RL applications.
Safety-Critical Online Control with Adversarial Disturbances
Sep 20, 2020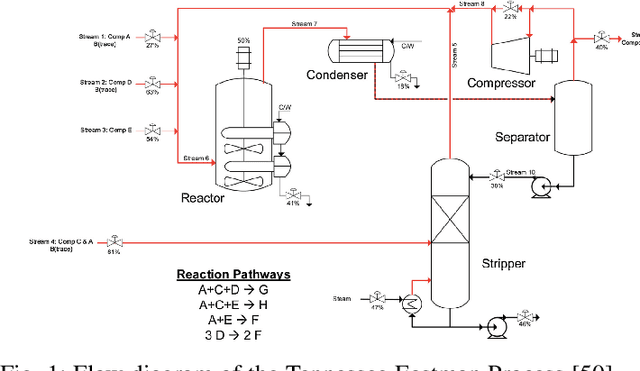
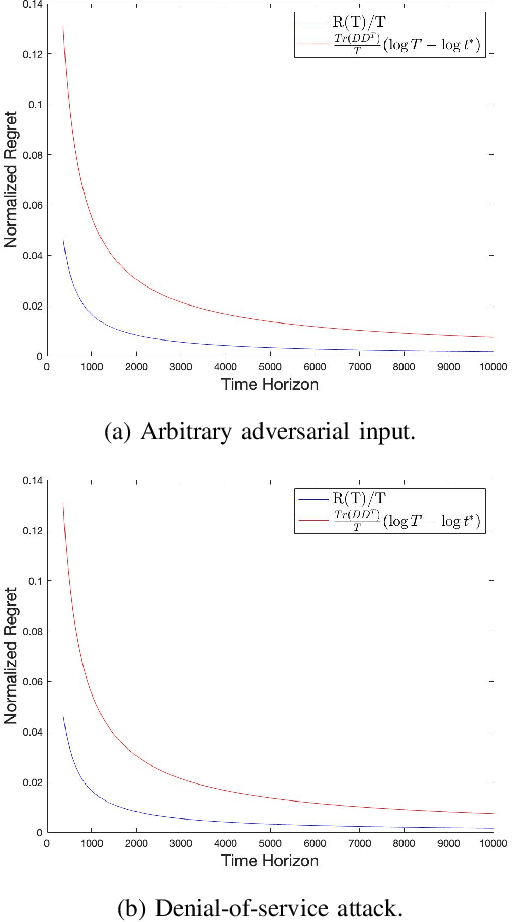
This paper studies the control of safety-critical dynamical systems in the presence of adversarial disturbances. We seek to synthesize state-feedback controllers to minimize a cost incurred due to the disturbance, while respecting a safety constraint. The safety constraint is given by a bound on an H-inf norm, while the cost is specified as an upper bound on the H-2 norm of the system. We consider an online setting where costs at each time are revealed only after the controller at that time is chosen. We propose an iterative approach to the synthesis of the controller by solving a modified discrete-time Riccati equation. Solutions of this equation enforce the safety constraint. We compare the cost of this controller with that of the optimal controller when one has complete knowledge of disturbances and costs in hindsight. We show that the regret function, which is defined as the difference between these costs, varies logarithmically with the time horizon. We validate our approach on a process control setup that is subject to two kinds of adversarial attacks.
FRESH: Interactive Reward Shaping in High-Dimensional State Spaces using Human Feedback
Jan 19, 2020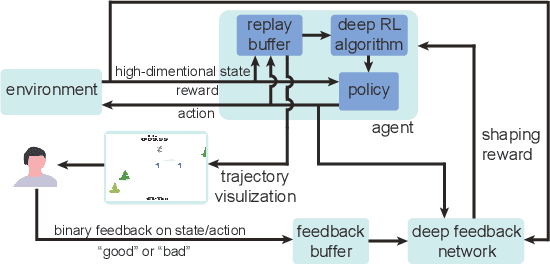
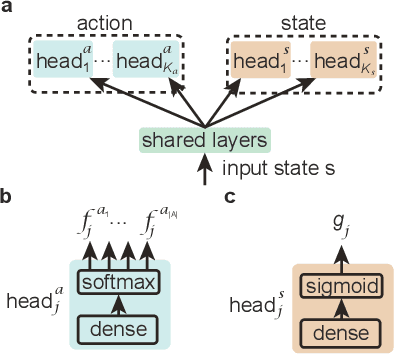
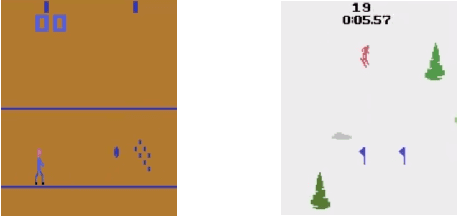
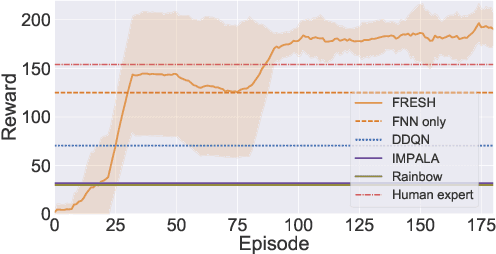
Reinforcement learning has been successful in training autonomous agents to accomplish goals in complex environments. Although this has been adapted to multiple settings, including robotics and computer games, human players often find it easier to obtain higher rewards in some environments than reinforcement learning algorithms. This is especially true of high-dimensional state spaces where the reward obtained by the agent is sparse or extremely delayed. In this paper, we seek to effectively integrate feedback signals supplied by a human operator with deep reinforcement learning algorithms in high-dimensional state spaces. We call this FRESH (Feedback-based REward SHaping). During training, a human operator is presented with trajectories from a replay buffer and then provides feedback on states and actions in the trajectory. In order to generalize feedback signals provided by the human operator to previously unseen states and actions at test-time, we use a feedback neural network. We use an ensemble of neural networks with a shared network architecture to represent model uncertainty and the confidence of the neural network in its output. The output of the feedback neural network is converted to a shaping reward that is augmented to the reward provided by the environment. We evaluate our approach on the Bowling and Skiing Atari games in the arcade learning environment. Although human experts have been able to achieve high scores in these environments, state-of-the-art deep learning algorithms perform poorly. We observe that FRESH is able to achieve much higher scores than state-of-the-art deep learning algorithms in both environments. FRESH also achieves a 21.4% higher score than a human expert in Bowling and does as well as a human expert in Skiing.
Potential-Based Advice for Stochastic Policy Learning
Jul 20, 2019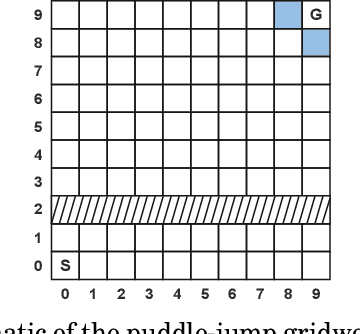
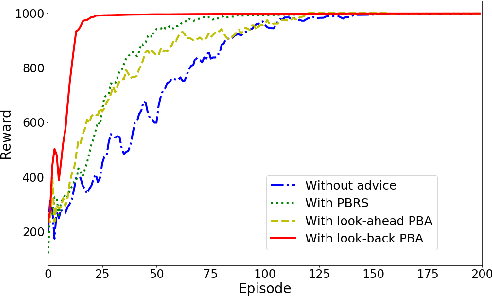
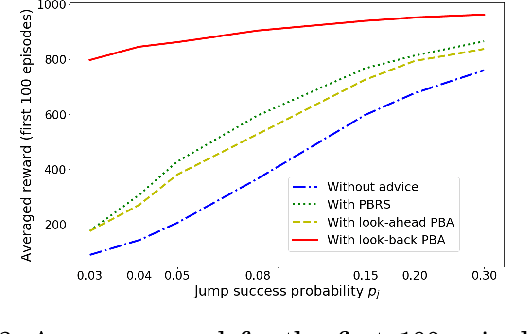
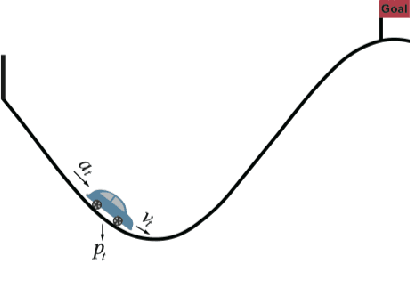
This paper augments the reward received by a reinforcement learning agent with potential functions in order to help the agent learn (possibly stochastic) optimal policies. We show that a potential-based reward shaping scheme is able to preserve optimality of stochastic policies, and demonstrate that the ability of an agent to learn an optimal policy is not affected when this scheme is augmented to soft Q-learning. We propose a method to impart potential based advice schemes to policy gradient algorithms. An algorithm that considers an advantage actor-critic architecture augmented with this scheme is proposed, and we give guarantees on its convergence. Finally, we evaluate our approach on a puddle-jump grid world with indistinguishable states, and the continuous state and action mountain car environment from classical control. Our results indicate that these schemes allow the agent to learn a stochastic optimal policy faster and obtain a higher average reward.