 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShaping Advice in Deep Reinforcement Learning
Feb 19, 2022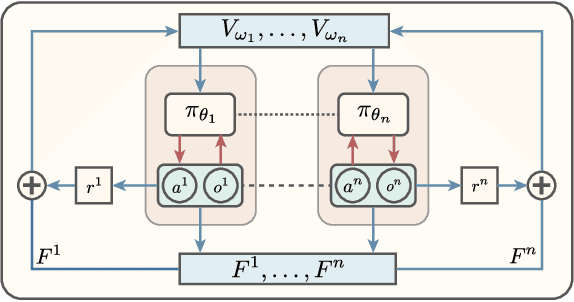
Reinforcement learning involves agents interacting with an environment to complete tasks. When rewards provided by the environment are sparse, agents may not receive immediate feedback on the quality of actions that they take, thereby affecting learning of policies. In this paper, we propose to methods to augment the reward signal from the environment with an additional reward termed shaping advice in both single and multi-agent reinforcement learning. The shaping advice is specified as a difference of potential functions at consecutive time-steps. Each potential function is a function of observations and actions of the agents. The use of potential functions is underpinned by an insight that the total potential when starting from any state and returning to the same state is always equal to zero. We show through theoretical analyses and experimental validation that the shaping advice does not distract agents from completing tasks specified by the environment reward. Theoretically, we prove that the convergence of policy gradients and value functions when using shaping advice implies the convergence of these quantities in the absence of shaping advice. We design two algorithms- Shaping Advice in Single-agent reinforcement learning (SAS) and Shaping Advice in Multi-agent reinforcement learning (SAM). Shaping advice in SAS and SAM needs to be specified only once at the start of training, and can easily be provided by non-experts. Experimentally, we evaluate SAS and SAM on two tasks in single-agent environments and three tasks in multi-agent environments that have sparse rewards. We observe that using shaping advice results in agents learning policies to complete tasks faster, and obtain higher rewards than algorithms that do not use shaping advice.
Agent-Temporal Attention for Reward Redistribution in Episodic Multi-Agent Reinforcement Learning
Jan 12, 2022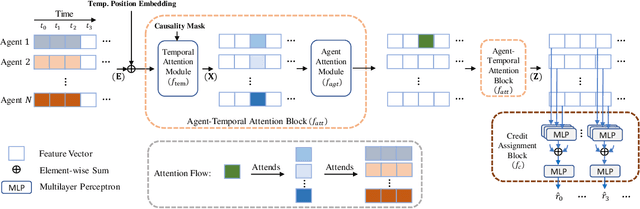
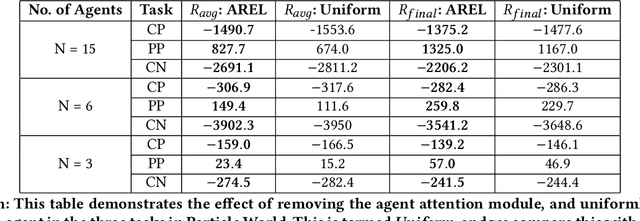
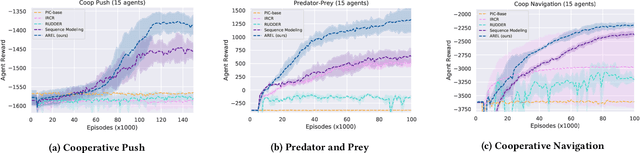

This paper considers multi-agent reinforcement learning (MARL) tasks where agents receive a shared global reward at the end of an episode. The delayed nature of this reward affects the ability of the agents to assess the quality of their actions at intermediate time-steps. This paper focuses on developing methods to learn a temporal redistribution of the episodic reward to obtain a dense reward signal. Solving such MARL problems requires addressing two challenges: identifying (1) relative importance of states along the length of an episode (along time), and (2) relative importance of individual agents' states at any single time-step (among agents). In this paper, we introduce Agent-Temporal Attention for Reward Redistribution in Episodic Multi-Agent Reinforcement Learning (AREL) to address these two challenges. AREL uses attention mechanisms to characterize the influence of actions on state transitions along trajectories (temporal attention), and how each agent is affected by other agents at each time-step (agent attention). The redistributed rewards predicted by AREL are dense, and can be integrated with any given MARL algorithm. We evaluate AREL on challenging tasks from the Particle World environment and the StarCraft Multi-Agent Challenge. AREL results in higher rewards in Particle World, and improved win rates in StarCraft compared to three state-of-the-art reward redistribution methods. Our code is available at https://github.com/baicenxiao/AREL.
Shaping Advice in Deep Multi-Agent Reinforcement Learning
Mar 29, 2021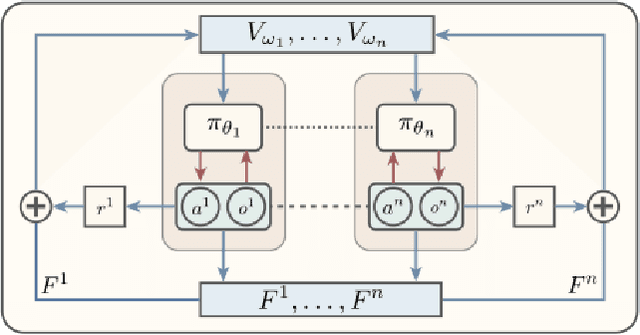
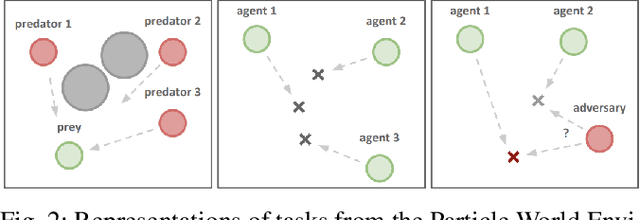
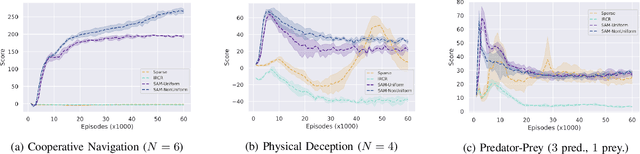

Multi-agent reinforcement learning involves multiple agents interacting with each other and a shared environment to complete tasks. When rewards provided by the environment are sparse, agents may not receive immediate feedback on the quality of actions that they take, thereby affecting learning of policies. In this paper, we propose a method called Shaping Advice in deep Multi-agent reinforcement learning (SAM) to augment the reward signal from the environment with an additional reward termed shaping advice. The shaping advice is given by a difference of potential functions at consecutive time-steps. Each potential function is a function of observations and actions of the agents. The shaping advice needs to be specified only once at the start of training, and can be easily provided by non-experts. We show through theoretical analyses and experimental validation that shaping advice provided by SAM does not distract agents from completing tasks specified by the environment reward. Theoretically, we prove that convergence of policy gradients and value functions when using SAM implies convergence of these quantities in the absence of SAM. Experimentally, we evaluate SAM on three tasks in the multi-agent Particle World environment that have sparse rewards. We observe that using SAM results in agents learning policies to complete tasks faster, and obtain higher rewards than: i) using sparse rewards alone; ii) a state-of-the-art reward redistribution method.
Safety-Critical Online Control with Adversarial Disturbances
Sep 20, 2020
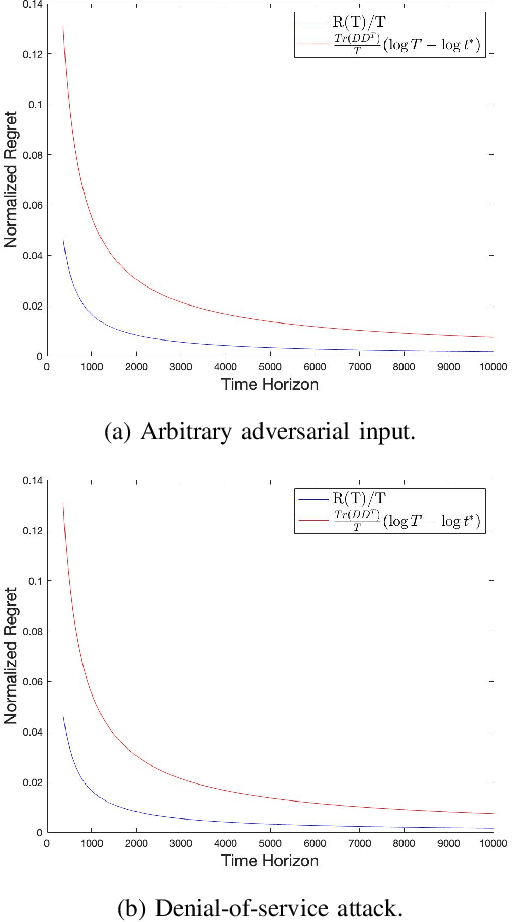
This paper studies the control of safety-critical dynamical systems in the presence of adversarial disturbances. We seek to synthesize state-feedback controllers to minimize a cost incurred due to the disturbance, while respecting a safety constraint. The safety constraint is given by a bound on an H-inf norm, while the cost is specified as an upper bound on the H-2 norm of the system. We consider an online setting where costs at each time are revealed only after the controller at that time is chosen. We propose an iterative approach to the synthesis of the controller by solving a modified discrete-time Riccati equation. Solutions of this equation enforce the safety constraint. We compare the cost of this controller with that of the optimal controller when one has complete knowledge of disturbances and costs in hindsight. We show that the regret function, which is defined as the difference between these costs, varies logarithmically with the time horizon. We validate our approach on a process control setup that is subject to two kinds of adversarial attacks.
FRESH: Interactive Reward Shaping in High-Dimensional State Spaces using Human Feedback
Jan 19, 2020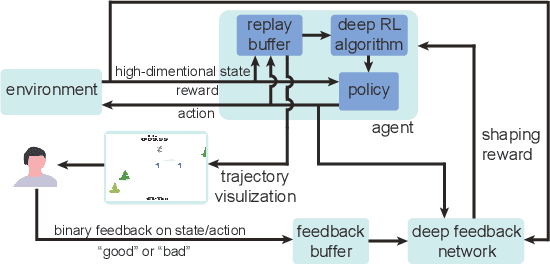
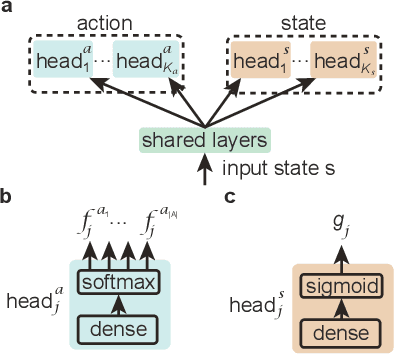
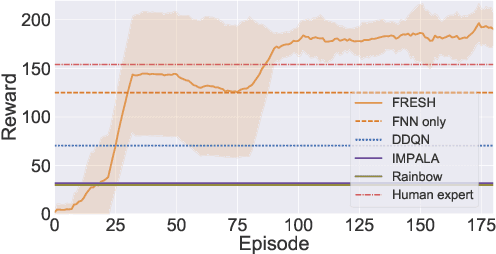
Reinforcement learning has been successful in training autonomous agents to accomplish goals in complex environments. Although this has been adapted to multiple settings, including robotics and computer games, human players often find it easier to obtain higher rewards in some environments than reinforcement learning algorithms. This is especially true of high-dimensional state spaces where the reward obtained by the agent is sparse or extremely delayed. In this paper, we seek to effectively integrate feedback signals supplied by a human operator with deep reinforcement learning algorithms in high-dimensional state spaces. We call this FRESH (Feedback-based REward SHaping). During training, a human operator is presented with trajectories from a replay buffer and then provides feedback on states and actions in the trajectory. In order to generalize feedback signals provided by the human operator to previously unseen states and actions at test-time, we use a feedback neural network. We use an ensemble of neural networks with a shared network architecture to represent model uncertainty and the confidence of the neural network in its output. The output of the feedback neural network is converted to a shaping reward that is augmented to the reward provided by the environment. We evaluate our approach on the Bowling and Skiing Atari games in the arcade learning environment. Although human experts have been able to achieve high scores in these environments, state-of-the-art deep learning algorithms perform poorly. We observe that FRESH is able to achieve much higher scores than state-of-the-art deep learning algorithms in both environments. FRESH also achieves a 21.4% higher score than a human expert in Bowling and does as well as a human expert in Skiing.
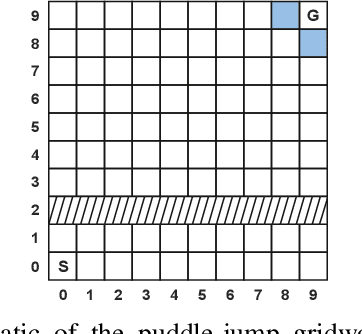
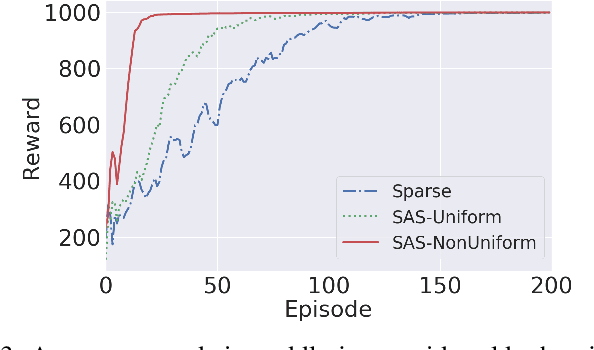
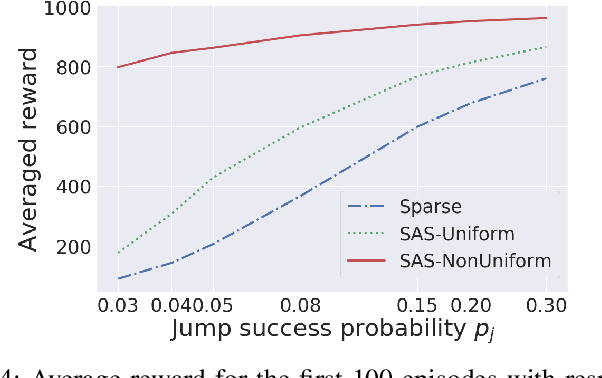
Potential-Based Advice for Stochastic Policy Learning
Jul 20, 2019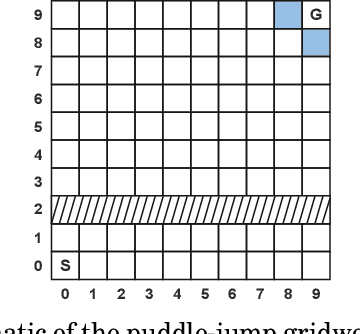
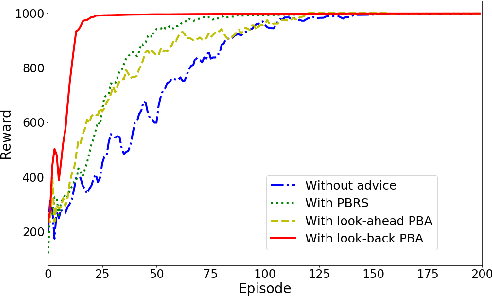
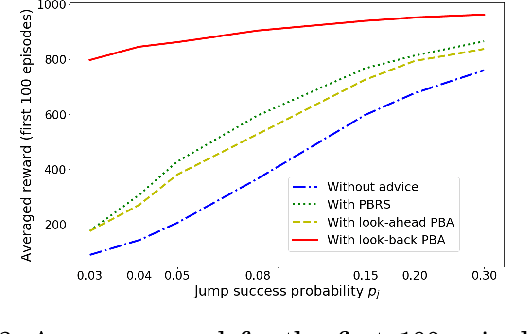
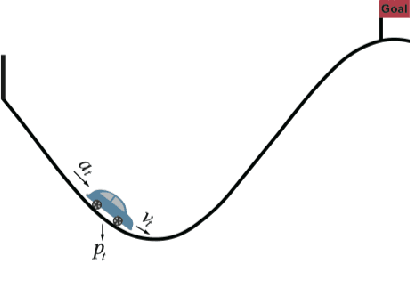
This paper augments the reward received by a reinforcement learning agent with potential functions in order to help the agent learn (possibly stochastic) optimal policies. We show that a potential-based reward shaping scheme is able to preserve optimality of stochastic policies, and demonstrate that the ability of an agent to learn an optimal policy is not affected when this scheme is augmented to soft Q-learning. We propose a method to impart potential based advice schemes to policy gradient algorithms. An algorithm that considers an advantage actor-critic architecture augmented with this scheme is proposed, and we give guarantees on its convergence. Finally, we evaluate our approach on a puddle-jump grid world with indistinguishable states, and the continuous state and action mountain car environment from classical control. Our results indicate that these schemes allow the agent to learn a stochastic optimal policy faster and obtain a higher average reward.
Assessing Shape Bias Property of Convolutional Neural Networks
Mar 21, 2018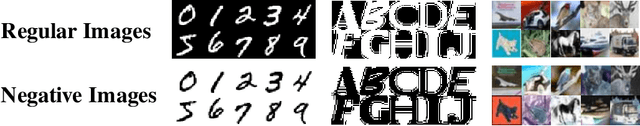
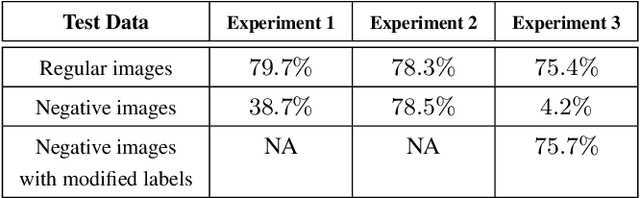
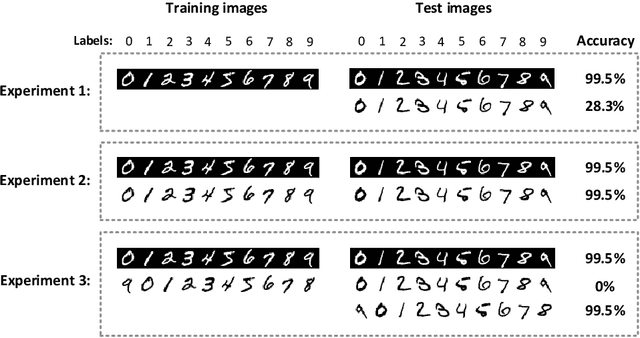
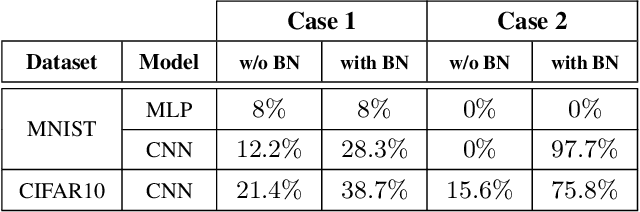
It is known that humans display "shape bias" when classifying new items, i.e., they prefer to categorize objects based on their shape rather than color. Convolutional Neural Networks (CNNs) are also designed to take into account the spatial structure of image data. In fact, experiments on image datasets, consisting of triples of a probe image, a shape-match and a color-match, have shown that one-shot learning models display shape bias as well. In this paper, we examine the shape bias property of CNNs. In order to conduct large scale experiments, we propose using the model accuracy on images with reversed brightness as a metric to evaluate the shape bias property. Such images, called negative images, contain objects that have the same shape as original images, but with different colors. Through extensive systematic experiments, we investigate the role of different factors, such as training data, model architecture, initialization and regularization techniques, on the shape bias property of CNNs. We show that it is possible to design different CNNs that achieve similar accuracy on original images, but perform significantly different on negative images, suggesting that CNNs do not intrinsically display shape bias. We then show that CNNs are able to learn and generalize the structures, when the model is properly initialized or data is properly augmented, and if batch normalization is used.
Attacking Automatic Video Analysis Algorithms: A Case Study of Google Cloud Video Intelligence API
Aug 14, 2017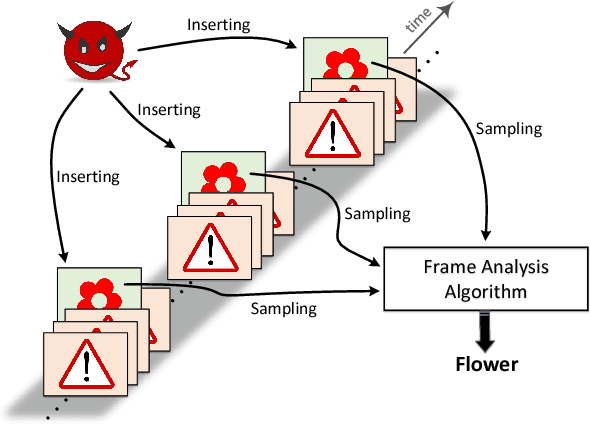


Due to the growth of video data on Internet, automatic video analysis has gained a lot of attention from academia as well as companies such as Facebook, Twitter and Google. In this paper, we examine the robustness of video analysis algorithms in adversarial settings. Specifically, we propose targeted attacks on two fundamental classes of video analysis algorithms, namely video classification and shot detection. We show that an adversary can subtly manipulate a video in such a way that a human observer would perceive the content of the original video, but the video analysis algorithm will return the adversary's desired outputs. We then apply the attacks on the recently released Google Cloud Video Intelligence API. The API takes a video file and returns the video labels (objects within the video), shot changes (scene changes within the video) and shot labels (description of video events over time). Through experiments, we show that the API generates video and shot labels by processing only the first frame of every second of the video. Hence, an adversary can deceive the API to output only her desired video and shot labels by periodically inserting an image into the video at the rate of one frame per second. We also show that the pattern of shot changes returned by the API can be mostly recovered by an algorithm that compares the histograms of consecutive frames. Based on our equivalent model, we develop a method for slightly modifying the video frames, in order to deceive the API into generating our desired pattern of shot changes. We perform extensive experiments with different videos and show that our attacks are consistently successful across videos with different characteristics. At the end, we propose introducing randomness to video analysis algorithms as a countermeasure to our attacks.
On the Limitation of Convolutional Neural Networks in Recognizing Negative Images
Aug 07, 2017
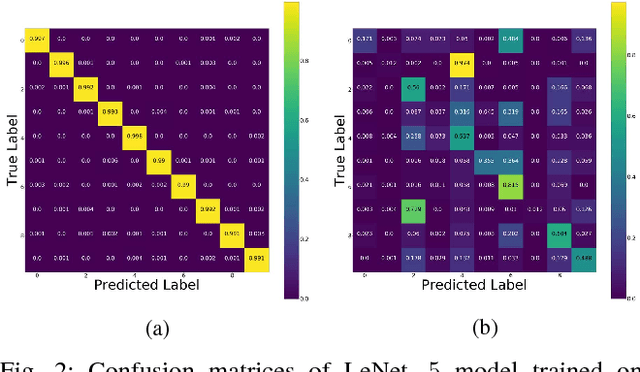
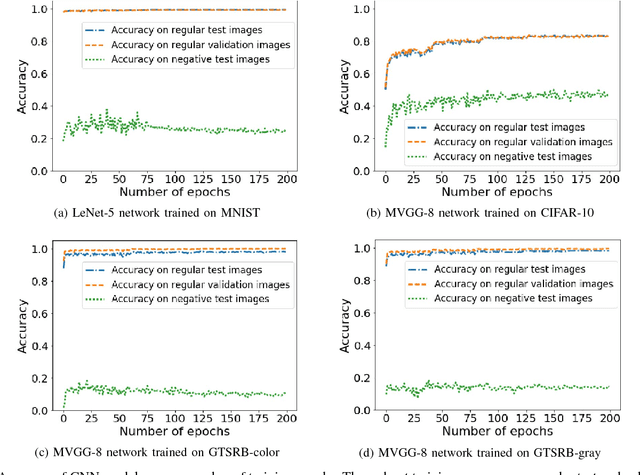
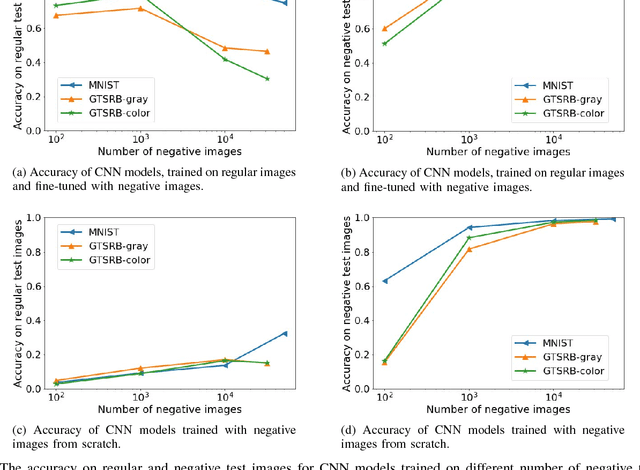
Convolutional Neural Networks (CNNs) have achieved state-of-the-art performance on a variety of computer vision tasks, particularly visual classification problems, where new algorithms reported to achieve or even surpass the human performance. In this paper, we examine whether CNNs are capable of learning the semantics of training data. To this end, we evaluate CNNs on negative images, since they share the same structure and semantics as regular images and humans can classify them correctly. Our experimental results indicate that when training on regular images and testing on negative images, the model accuracy is significantly lower than when it is tested on regular images. This leads us to the conjecture that current training methods do not effectively train models to generalize the concepts. We then introduce the notion of semantic adversarial examples - transformed inputs that semantically represent the same objects, but the model does not classify them correctly - and present negative images as one class of such inputs.
Deceiving Google's Cloud Video Intelligence API Built for Summarizing Videos
Mar 31, 2017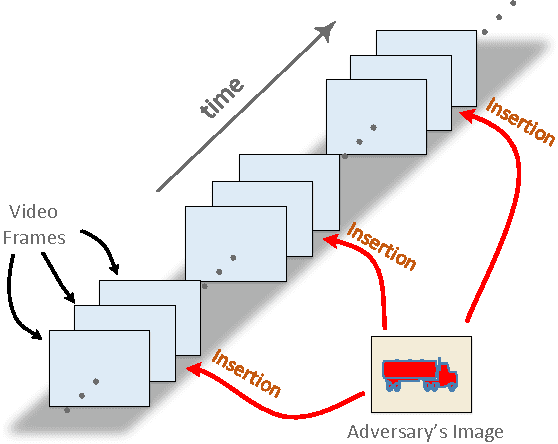
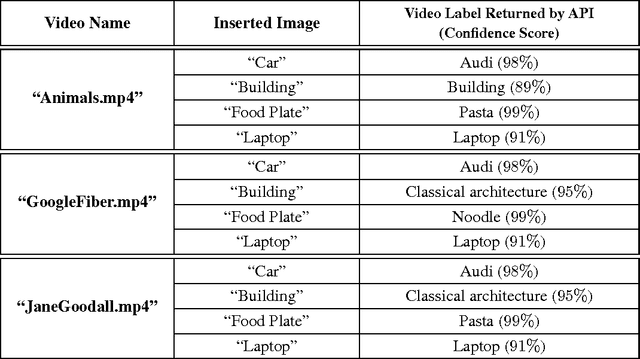

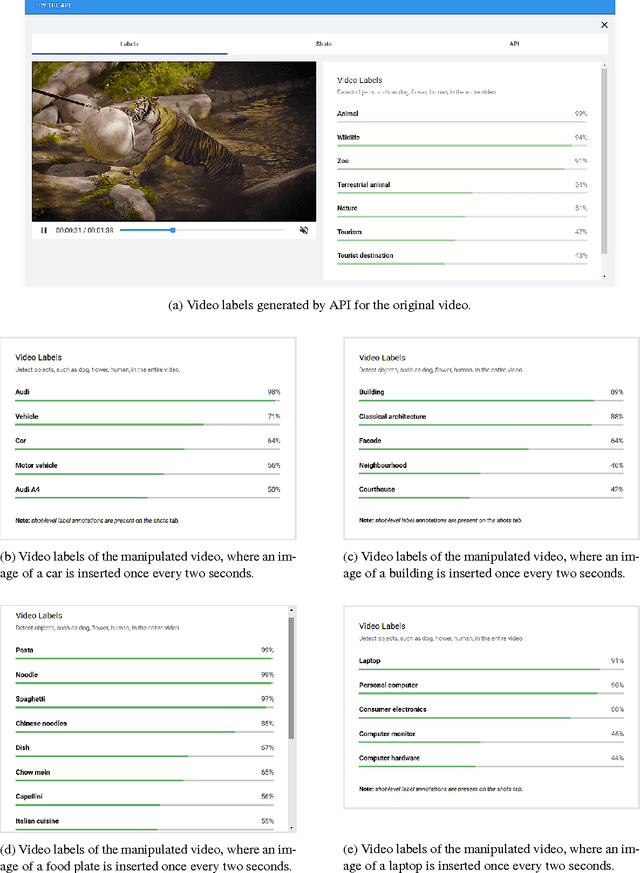
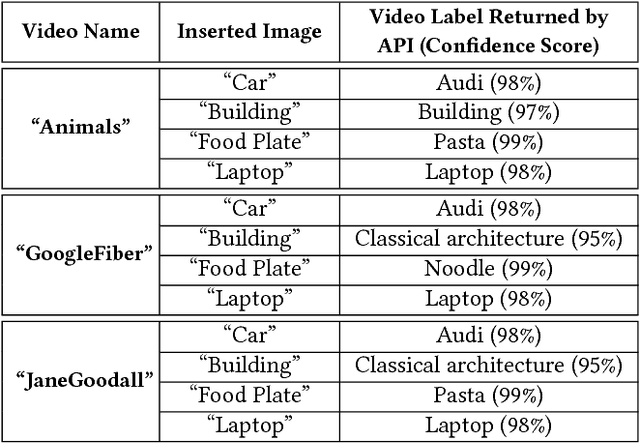
Despite the rapid progress of the techniques for image classification, video annotation has remained a challenging task. Automated video annotation would be a breakthrough technology, enabling users to search within the videos. Recently, Google introduced the Cloud Video Intelligence API for video analysis. As per the website, the system can be used to "separate signal from noise, by retrieving relevant information at the video, shot or per frame" level. A demonstration website has been also launched, which allows anyone to select a video for annotation. The API then detects the video labels (objects within the video) as well as shot labels (description of the video events over time). In this paper, we examine the usability of the Google's Cloud Video Intelligence API in adversarial environments. In particular, we investigate whether an adversary can subtly manipulate a video in such a way that the API will return only the adversary-desired labels. For this, we select an image, which is different from the video content, and insert it, periodically and at a very low rate, into the video. We found that if we insert one image every two seconds, the API is deceived into annotating the video as if it only contained the inserted image. Note that the modification to the video is hardly noticeable as, for instance, for a typical frame rate of 25, we insert only one image per 50 video frames. We also found that, by inserting one image per second, all the shot labels returned by the API are related to the inserted image. We perform the experiments on the sample videos provided by the API demonstration website and show that our attack is successful with different videos and images.