 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersianRAG: A Retrieval-Augmented Generation System for Persian Language
Nov 05, 2024Retrieval augmented generation (RAG) models, which integrate large-scale pre-trained generative models with external retrieval mechanisms, have shown significant success in various natural language processing (NLP) tasks. However, applying RAG models in Persian language as a low-resource language, poses distinct challenges. These challenges primarily involve the preprocessing, embedding, retrieval, prompt construction, language modeling, and response evaluation of the system. In this paper, we address the challenges towards implementing a real-world RAG system for Persian language called PersianRAG. We propose novel solutions to overcome these obstacles and evaluate our approach using several Persian benchmark datasets. Our experimental results demonstrate the capability of the PersianRAG framework to enhance question answering task in Persian.
Unsupervised Information Obfuscation for Split Inference of Neural Networks
Apr 23, 2021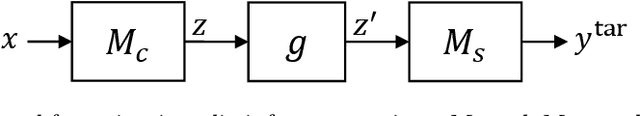
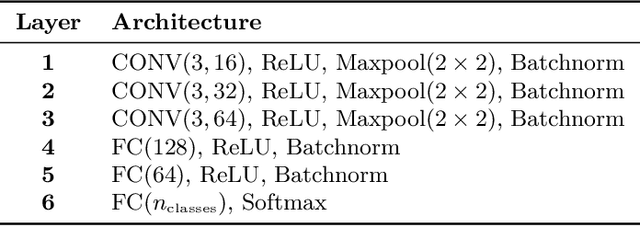

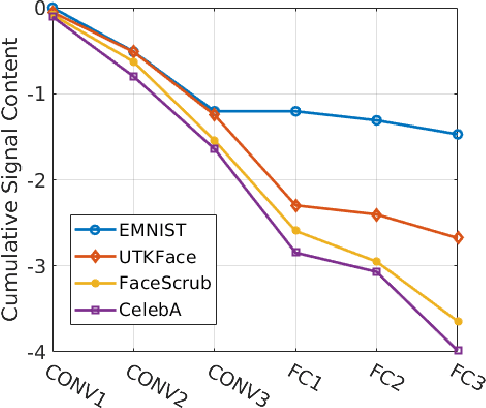
Splitting network computations between the edge device and a server enables low edge-compute inference of neural networks but might expose sensitive information about the test query to the server. To address this problem, existing techniques train the model to minimize information leakage for a given set of sensitive attributes. In practice, however, the test queries might contain attributes that are not foreseen during training. We propose instead an unsupervised obfuscation method to discard the information irrelevant to the main task. We formulate the problem via an information theoretical framework and derive an analytical solution for a given distortion to the model output. In our method, the edge device runs the model up to a split layer determined based on its computational capacity. It then obfuscates the obtained feature vector based on the first layer of the server model by removing the components in the null space as well as the low-energy components of the remaining signal. Our experimental results show that our method outperforms existing techniques in removing the information of the irrelevant attributes and maintaining the accuracy on the target label. We also show that our method reduces the communication cost and incurs only a small computational overhead.
Federated Learning of User Verification Models Without Sharing Embeddings
Apr 18, 2021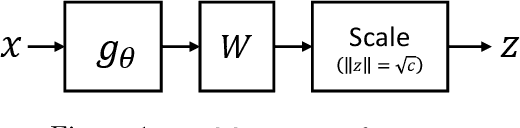
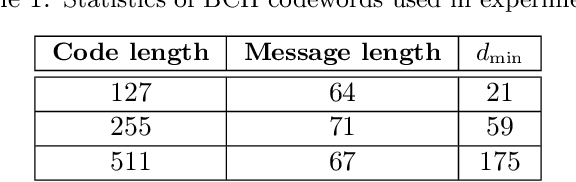
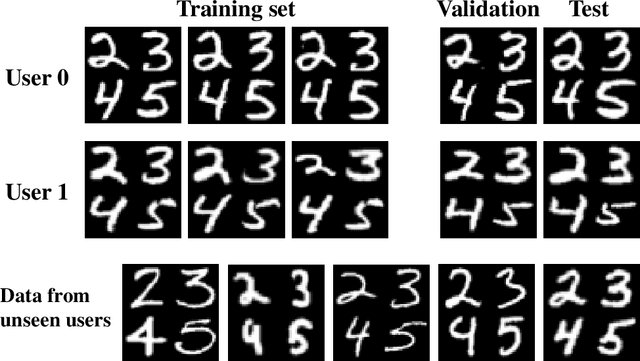
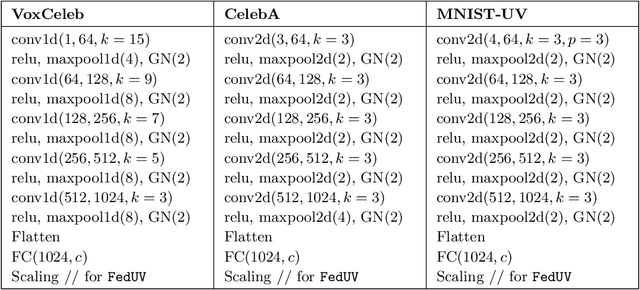
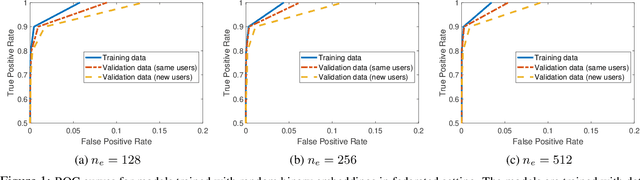
We consider the problem of training User Verification (UV) models in federated setting, where each user has access to the data of only one class and user embeddings cannot be shared with the server or other users. To address this problem, we propose Federated User Verification (FedUV), a framework in which users jointly learn a set of vectors and maximize the correlation of their instance embeddings with a secret linear combination of those vectors. We show that choosing the linear combinations from the codewords of an error-correcting code allows users to collaboratively train the model without revealing their embedding vectors. We present the experimental results for user verification with voice, face, and handwriting data and show that FedUV is on par with existing approaches, while not sharing the embeddings with other users or the server.
Federated Learning of User Authentication Models
Jul 09, 2020
Machine learning-based User Authentication (UA) models have been widely deployed in smart devices. UA models are trained to map input data of different users to highly separable embedding vectors, which are then used to accept or reject new inputs at test time. Training UA models requires having direct access to the raw inputs and embedding vectors of users, both of which are privacy-sensitive information. In this paper, we propose Federated User Authentication (FedUA), a framework for privacy-preserving training of UA models. FedUA adopts federated learning framework to enable a group of users to jointly train a model without sharing the raw inputs. It also allows users to generate their embeddings as random binary vectors, so that, unlike the existing approach of constructing the spread out embeddings by the server, the embedding vectors are kept private as well. We show our method is privacy-preserving, scalable with number of users, and allows new users to be added to training without changing the output layer. Our experimental results on the VoxCeleb dataset for speaker verification shows our method reliably rejects data of unseen users at very high true positive rates.
Are Odds Really Odd? Bypassing Statistical Detection of Adversarial Examples
Jul 28, 2019
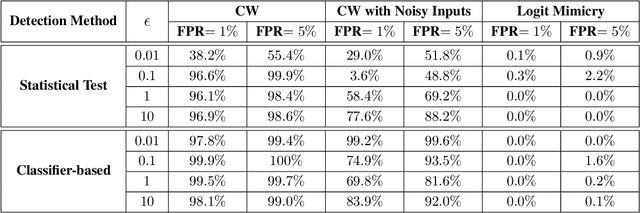
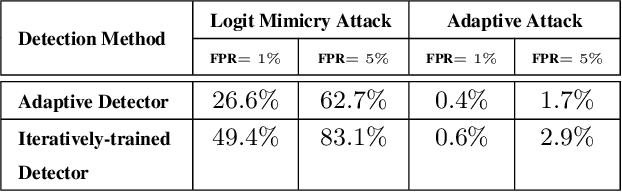
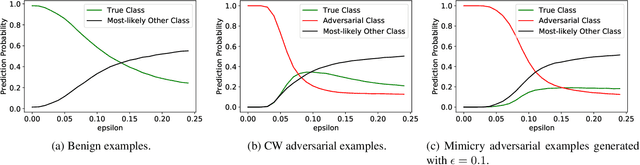
Deep learning classifiers are known to be vulnerable to adversarial examples. A recent paper presented at ICML 2019 proposed a statistical test detection method based on the observation that logits of noisy adversarial examples are biased toward the true class. The method is evaluated on CIFAR-10 dataset and is shown to achieve 99% true positive rate (TPR) at only 1% false positive rate (FPR). In this paper, we first develop a classifier-based adaptation of the statistical test method and show that it improves the detection performance. We then propose Logit Mimicry Attack method to generate adversarial examples such that their logits mimic those of benign images. We show that our attack bypasses both statistical test and classifier-based methods, reducing their TPR to less than 2:2% and 1:6%, respectively, even at 5% FPR. We finally show that a classifier-based detector that is trained with logits of mimicry adversarial examples can be evaded by an adaptive attacker that specifically targets the detector. Furthermore, even a detector that is iteratively trained to defend against adaptive attacker cannot be made robust, indicating that statistics of logits cannot be used to detect adversarial examples.
Dropping Pixels for Adversarial Robustness
May 01, 2019

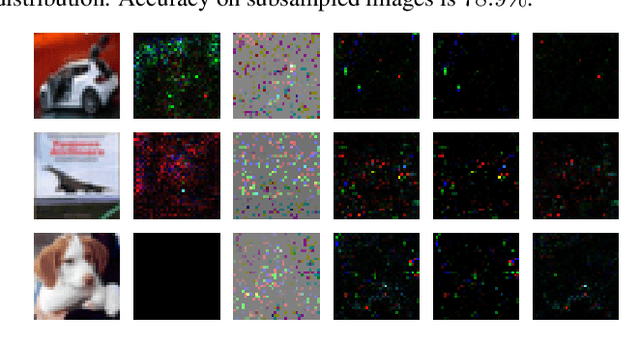
Deep neural networks are vulnerable against adversarial examples. In this paper, we propose to train and test the networks with randomly subsampled images with high drop rates. We show that this approach significantly improves robustness against adversarial examples in all cases of bounded L0, L2 and L_inf perturbations, while reducing the standard accuracy by a small value. We argue that subsampling pixels can be thought to provide a set of robust features for the input image and, thus, improves robustness without performing adversarial training.
Assessing Shape Bias Property of Convolutional Neural Networks
Mar 21, 2018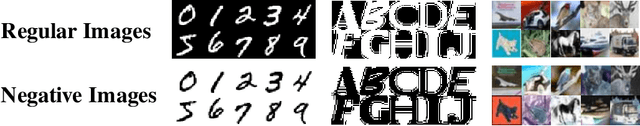
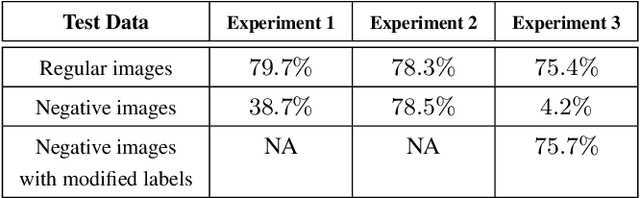
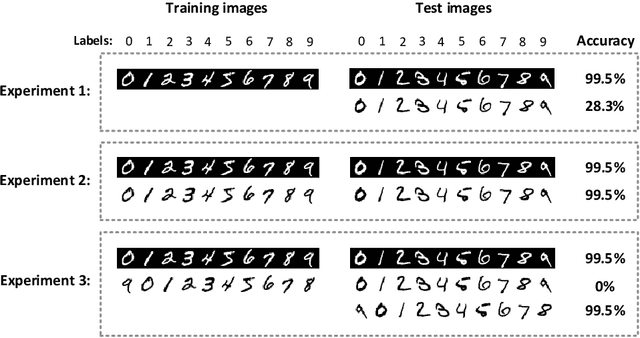
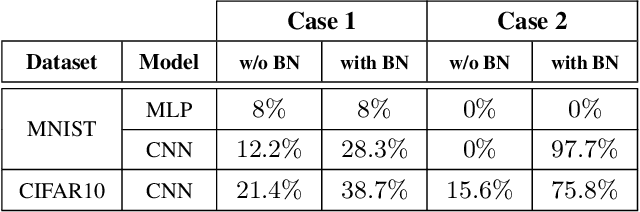
It is known that humans display "shape bias" when classifying new items, i.e., they prefer to categorize objects based on their shape rather than color. Convolutional Neural Networks (CNNs) are also designed to take into account the spatial structure of image data. In fact, experiments on image datasets, consisting of triples of a probe image, a shape-match and a color-match, have shown that one-shot learning models display shape bias as well. In this paper, we examine the shape bias property of CNNs. In order to conduct large scale experiments, we propose using the model accuracy on images with reversed brightness as a metric to evaluate the shape bias property. Such images, called negative images, contain objects that have the same shape as original images, but with different colors. Through extensive systematic experiments, we investigate the role of different factors, such as training data, model architecture, initialization and regularization techniques, on the shape bias property of CNNs. We show that it is possible to design different CNNs that achieve similar accuracy on original images, but perform significantly different on negative images, suggesting that CNNs do not intrinsically display shape bias. We then show that CNNs are able to learn and generalize the structures, when the model is properly initialized or data is properly augmented, and if batch normalization is used.
Semantic Adversarial Examples
Mar 16, 2018
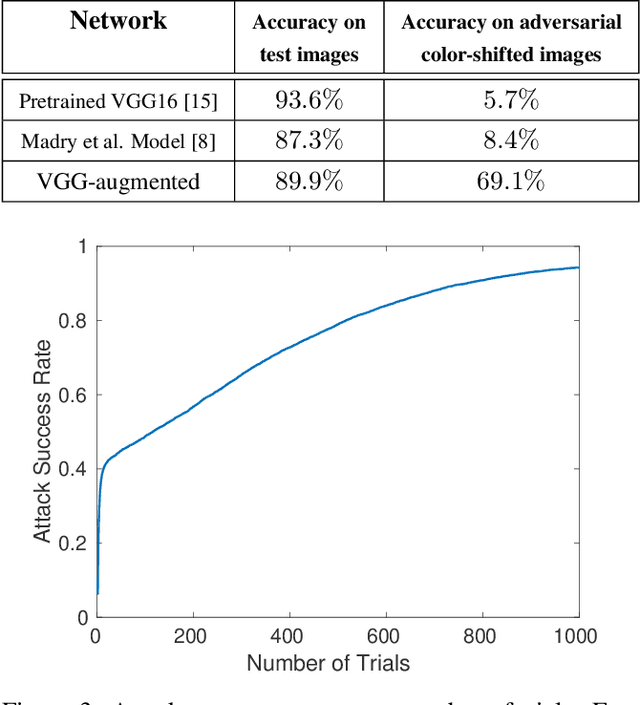

Deep neural networks are known to be vulnerable to adversarial examples, i.e., images that are maliciously perturbed to fool the model. Generating adversarial examples has been mostly limited to finding small perturbations that maximize the model prediction error. Such images, however, contain artificial perturbations that make them somewhat distinguishable from natural images. This property is used by several defense methods to counter adversarial examples by applying denoising filters or training the model to be robust to small perturbations. In this paper, we introduce a new class of adversarial examples, namely "Semantic Adversarial Examples," as images that are arbitrarily perturbed to fool the model, but in such a way that the modified image semantically represents the same object as the original image. We formulate the problem of generating such images as a constrained optimization problem and develop an adversarial transformation based on the shape bias property of human cognitive system. In our method, we generate adversarial images by first converting the RGB image into the HSV (Hue, Saturation and Value) color space and then randomly shifting the Hue and Saturation components, while keeping the Value component the same. Our experimental results on CIFAR10 dataset show that the accuracy of VGG16 network on adversarial color-shifted images is 5.7%.
Attacking Automatic Video Analysis Algorithms: A Case Study of Google Cloud Video Intelligence API
Aug 14, 2017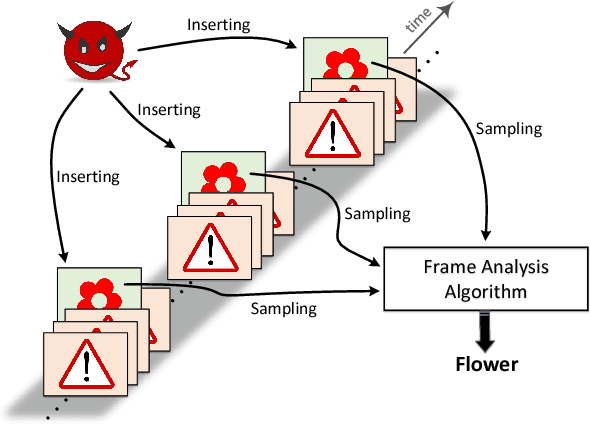


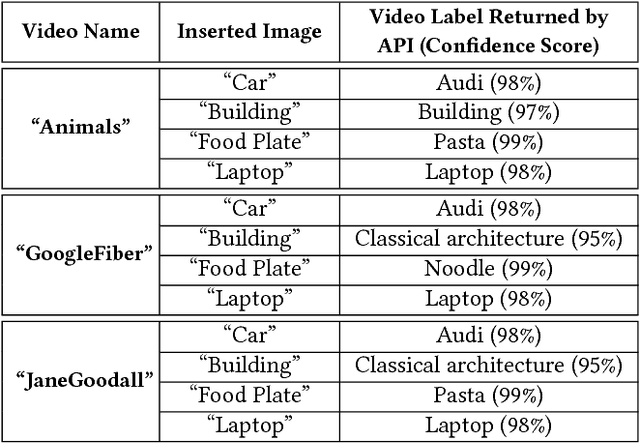
Due to the growth of video data on Internet, automatic video analysis has gained a lot of attention from academia as well as companies such as Facebook, Twitter and Google. In this paper, we examine the robustness of video analysis algorithms in adversarial settings. Specifically, we propose targeted attacks on two fundamental classes of video analysis algorithms, namely video classification and shot detection. We show that an adversary can subtly manipulate a video in such a way that a human observer would perceive the content of the original video, but the video analysis algorithm will return the adversary's desired outputs. We then apply the attacks on the recently released Google Cloud Video Intelligence API. The API takes a video file and returns the video labels (objects within the video), shot changes (scene changes within the video) and shot labels (description of video events over time). Through experiments, we show that the API generates video and shot labels by processing only the first frame of every second of the video. Hence, an adversary can deceive the API to output only her desired video and shot labels by periodically inserting an image into the video at the rate of one frame per second. We also show that the pattern of shot changes returned by the API can be mostly recovered by an algorithm that compares the histograms of consecutive frames. Based on our equivalent model, we develop a method for slightly modifying the video frames, in order to deceive the API into generating our desired pattern of shot changes. We perform extensive experiments with different videos and show that our attacks are consistently successful across videos with different characteristics. At the end, we propose introducing randomness to video analysis algorithms as a countermeasure to our attacks.
On the Limitation of Convolutional Neural Networks in Recognizing Negative Images
Aug 07, 2017
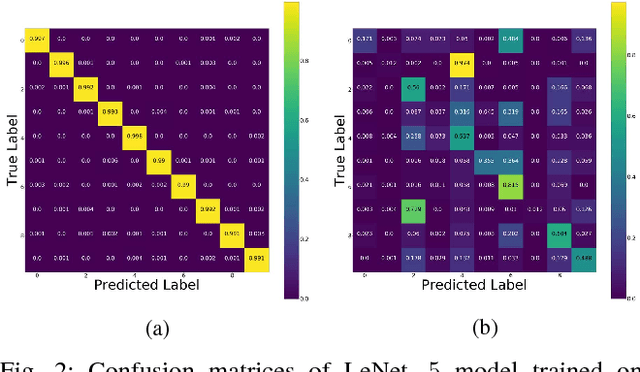
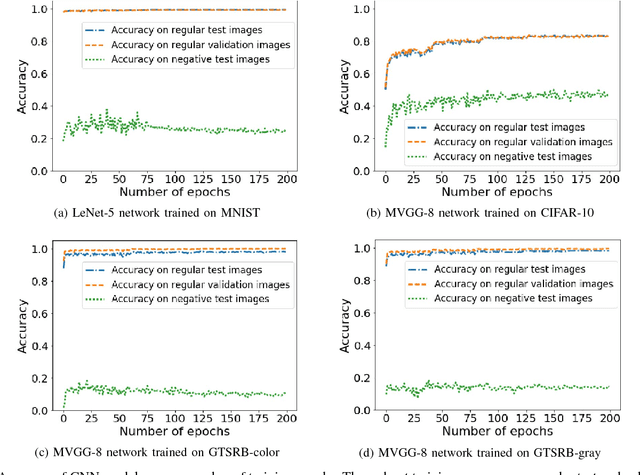
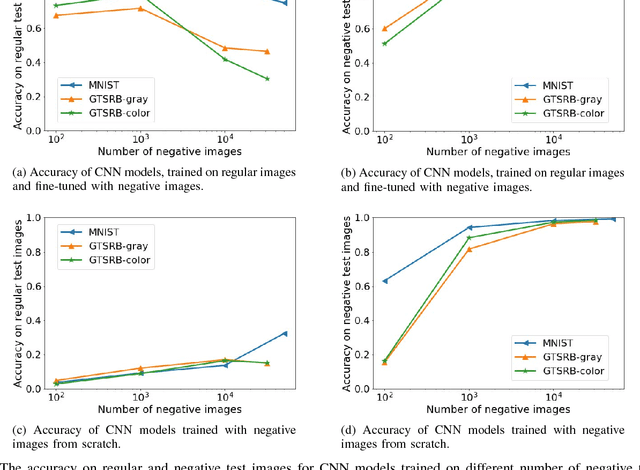
Convolutional Neural Networks (CNNs) have achieved state-of-the-art performance on a variety of computer vision tasks, particularly visual classification problems, where new algorithms reported to achieve or even surpass the human performance. In this paper, we examine whether CNNs are capable of learning the semantics of training data. To this end, we evaluate CNNs on negative images, since they share the same structure and semantics as regular images and humans can classify them correctly. Our experimental results indicate that when training on regular images and testing on negative images, the model accuracy is significantly lower than when it is tested on regular images. This leads us to the conjecture that current training methods do not effectively train models to generalize the concepts. We then introduce the notion of semantic adversarial examples - transformed inputs that semantically represent the same objects, but the model does not classify them correctly - and present negative images as one class of such inputs.