 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersianRAG: A Retrieval-Augmented Generation System for Persian Language
Nov 05, 2024Retrieval augmented generation (RAG) models, which integrate large-scale pre-trained generative models with external retrieval mechanisms, have shown significant success in various natural language processing (NLP) tasks. However, applying RAG models in Persian language as a low-resource language, poses distinct challenges. These challenges primarily involve the preprocessing, embedding, retrieval, prompt construction, language modeling, and response evaluation of the system. In this paper, we address the challenges towards implementing a real-world RAG system for Persian language called PersianRAG. We propose novel solutions to overcome these obstacles and evaluate our approach using several Persian benchmark datasets. Our experimental results demonstrate the capability of the PersianRAG framework to enhance question answering task in Persian.
Evaluating ChatGPT as a Question Answering System: A Comprehensive Analysis and Comparison with Existing Models
Dec 11, 2023In the current era, a multitude of language models has emerged to cater to user inquiries. Notably, the GPT-3.5 Turbo language model has gained substantial attention as the underlying technology for ChatGPT. Leveraging extensive parameters, this model adeptly responds to a wide range of questions. However, due to its reliance on internal knowledge, the accuracy of responses may not be absolute. This article scrutinizes ChatGPT as a Question Answering System (QAS), comparing its performance to other existing QASs. The primary focus is on evaluating ChatGPT's proficiency in extracting responses from provided paragraphs, a core QAS capability. Additionally, performance comparisons are made in scenarios without a surrounding passage. Multiple experiments, exploring response hallucination and considering question complexity, were conducted on ChatGPT. Evaluation employed well-known Question Answering (QA) datasets, including SQuAD, NewsQA, and PersianQuAD, across English and Persian languages. Metrics such as F-score, exact match, and accuracy were employed in the assessment. The study reveals that, while ChatGPT demonstrates competence as a generative model, it is less effective in question answering compared to task-specific models. Providing context improves its performance, and prompt engineering enhances precision, particularly for questions lacking explicit answers in provided paragraphs. ChatGPT excels at simpler factual questions compared to "how" and "why" question types. The evaluation highlights occurrences of hallucinations, where ChatGPT provides responses to questions without available answers in the provided context.
A Survey of Credit Card Fraud Detection Techniques: Data and Technique Oriented Perspective
Nov 19, 2016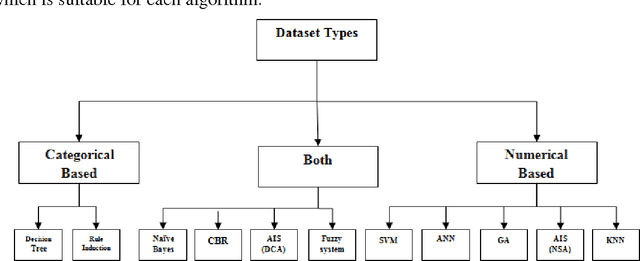
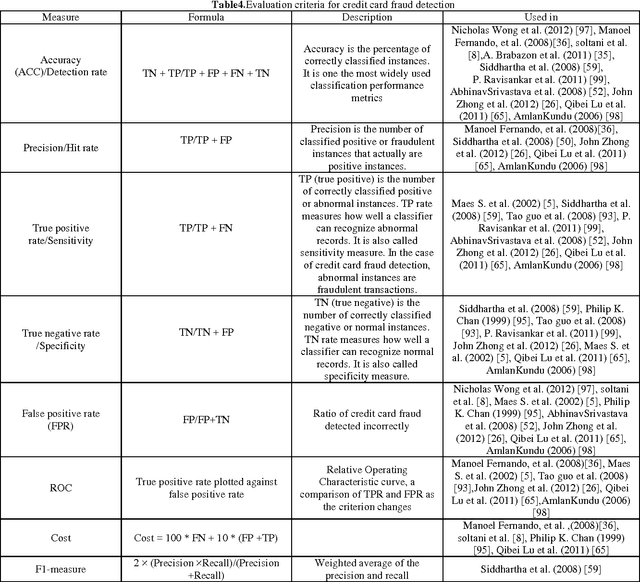
Credit card plays a very important rule in today's economy. It becomes an unavoidable part of household, business and global activities. Although using credit cards provides enormous benefits when used carefully and responsibly,significant credit and financial damages may be caused by fraudulent activities. Many techniques have been proposed to confront the growth in credit card fraud. However, all of these techniques have the same goal of avoiding the credit card fraud; each one has its own drawbacks, advantages and characteristics. In this paper, after investigating difficulties of credit card fraud detection, we seek to review the state of the art in credit card fraud detection techniques, data sets and evaluation criteria.The advantages and disadvantages of fraud detection methods are enumerated and compared.Furthermore, a classification of mentioned techniques into two main fraud detection approaches, namely, misuses (supervised) and anomaly detection (unsupervised) is presented. Again, a classification of techniques is proposed based on capability to process the numerical and categorical data sets. Different data sets used in literature are then described and grouped into real and synthesized data and the effective and common attributes are extracted for further usage.Moreover, evaluation employed criterions in literature are collected and discussed.Consequently, open issues for credit card fraud detection are explained as guidelines for new researchers.