 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersianRAG: A Retrieval-Augmented Generation System for Persian Language
Nov 05, 2024Retrieval augmented generation (RAG) models, which integrate large-scale pre-trained generative models with external retrieval mechanisms, have shown significant success in various natural language processing (NLP) tasks. However, applying RAG models in Persian language as a low-resource language, poses distinct challenges. These challenges primarily involve the preprocessing, embedding, retrieval, prompt construction, language modeling, and response evaluation of the system. In this paper, we address the challenges towards implementing a real-world RAG system for Persian language called PersianRAG. We propose novel solutions to overcome these obstacles and evaluate our approach using several Persian benchmark datasets. Our experimental results demonstrate the capability of the PersianRAG framework to enhance question answering task in Persian.
BAS: An Answer Selection Method Using BERT Language Model
Nov 11, 2019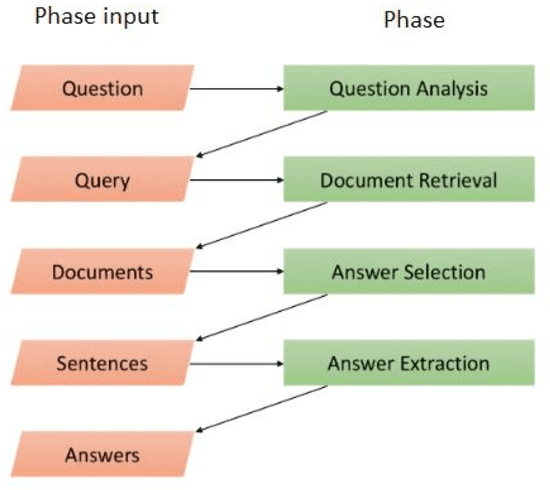



In recent years, Question Answering systems have become more popular and widely used by users. Despite the increasing popularity of these systems, the their performance is not even sufficient for textual data and requires further research. These systems consist of several parts that one of them is the Answer Selection component. This component detects the most relevant answer from a list of candidate answers. The methods presented in previous researches have attempted to provide an independent model to undertake the answer-selection task. An independent model cannot comprehend the syntactic and semantic features of questions and answers with a small training dataset. To fill this gap, language models can be employed in implementing the answer selection part. This action enables the model to have a better understanding of the language in order to understand questions and answers better than previous works. In this research, we will present the "BAS" (BERT Answer Selection) that uses the BERT language model to comprehend language. The empirical results of applying the model on the TrecQA Raw, TrecQA Clean, and WikiQA datasets demonstrate that using a robust language model such as BERT can enhance the performance. Using a more robust classifier also enhances the effect of the language model on the answer selection component. The results demonstrate that language comprehension is an essential requirement in natural language processing tasks such as answer-selection.
Attention-based Pairwise Multi-Perspective Convolutional Neural Network for Answer Selection in Question Answering
Sep 14, 2019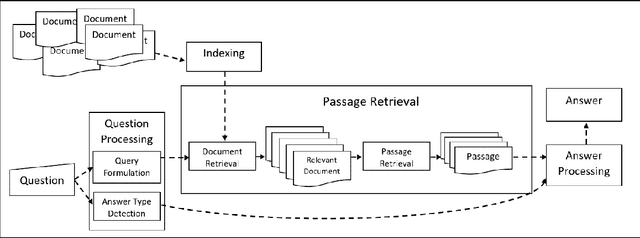
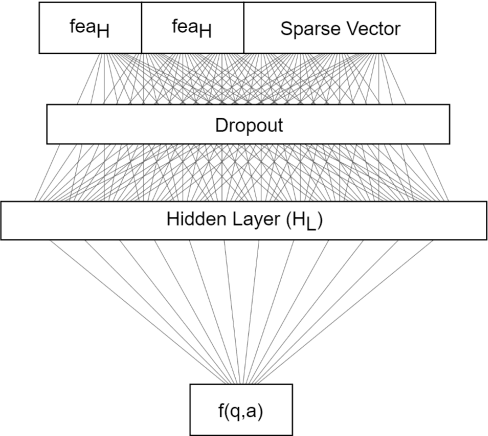
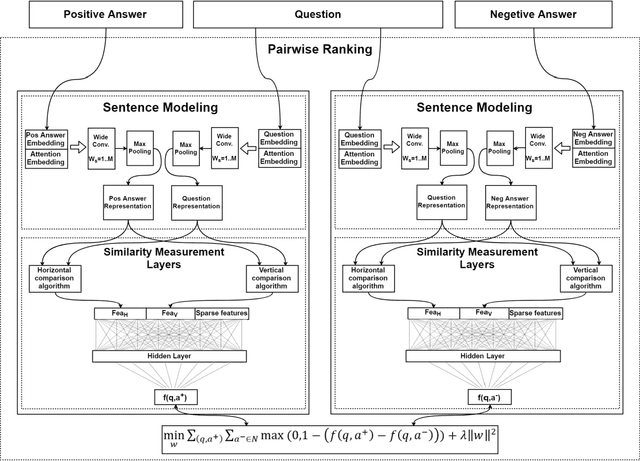
Over the past few years, question answering and information retrieval systems have become widely used. These systems attempt to find the answer of the asked questions from raw text sources. A component of these systems is Answer Selection which selects the most relevant answer from candidate answers. Syntactic similarities were mostly used to compute the similarity, but in recent works, deep neural networks have been used which have made a significant improvement in this field. In this research, a model is proposed to select the most relevant answers to the factoid question from the candidate answers. The proposed model ranks the candidate answers in terms of semantic and syntactic similarity to the question, using convolutional neural networks. In this research, Attention mechanism and Sparse feature vector use the context-sensitive interactions between questions and answer sentence. Wide convolution increases the importance of the interrogative word. Pairwise ranking is used to learn differentiable representations to distinguish positive and negative answers. Our model indicates strong performance on the TrecQA beating previous state-of-the-art systems by 2.62% in MAP and 2.13% in MRR while using the benefits of no additional syntactic parsers and external tools. The results show that using context-sensitive interactions between question and answer sentences can help to find the correct answer more accurately.
Structural Weights in Ontology Matching
Nov 15, 2013
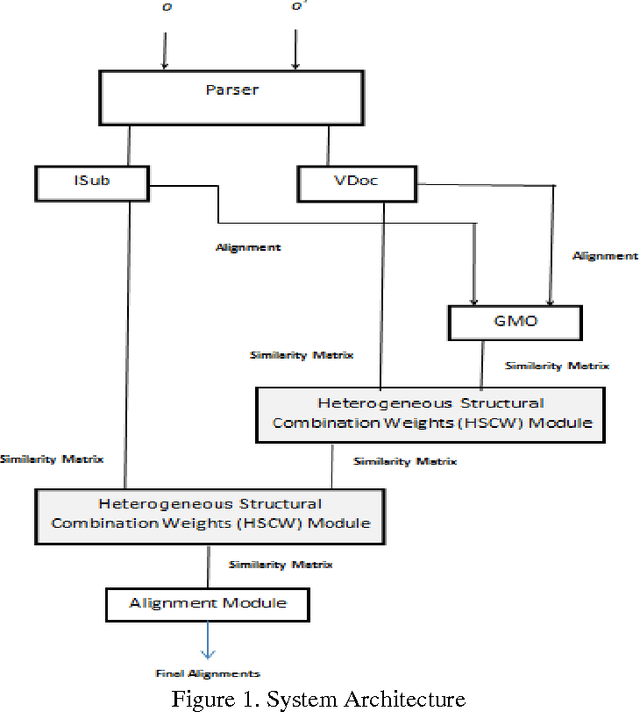
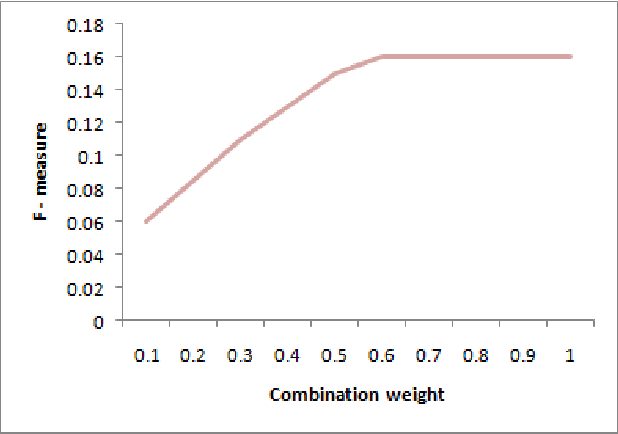
Ontology matching finds correspondences between similar entities of different ontologies. Two ontologies may be similar in some aspects such as structure, semantic etc. Most ontology matching systems integrate multiple matchers to extract all the similarities that two ontologies may have. Thus, we face a major problem to aggregate different similarities. Some matching systems use experimental weights for aggregation of similarities among different matchers while others use machine learning approaches and optimization algorithms to find optimal weights to assign to different matchers. However, both approaches have their own deficiencies. In this paper, we will point out the problems and shortcomings of current similarity aggregation strategies. Then, we propose a new strategy, which enables us to utilize the structural information of ontologies to get weights of matchers, for the similarity aggregation task. For achieving this goal, we create a new Ontology Matching system which it uses three available matchers, namely GMO, ISub and VDoc. We have tested our similarity aggregation strategy on the OAEI 2012 data set. Experimental results show significant improvements in accuracies of several cases, especially in matching the classes of ontologies. We will compare the performance of our similarity aggregation strategy with other well-known strategies