 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Prompt Engineering Techniques for RAG in Small Language Models: A Multi-Hop QA Approach
Feb 14, 2026Retrieval Augmented Generation (RAG) is a powerful approach for enhancing the factual grounding of language models by integrating external knowledge. While widely studied for large language models, the optimization of RAG for Small Language Models (SLMs) remains a critical research gap, particularly in complex, multi-hop question-answering tasks that require sophisticated reasoning. In these systems, prompt template design is a crucial yet under-explored factor influencing performance. This paper presents a large-scale empirical study to investigate this factor, evaluating 24 different prompt templates on the HotpotQA dataset. The set includes a standard RAG prompt, nine well-formed techniques from the literature, and 14 novel hybrid variants, all tested on two prominent SLMs: Qwen2.5-3B Instruct and Gemma3-4B-It. Our findings, based on a test set of 18720 instances, reveal significant performance gains of up to 83% on Qwen2.5 and 84.5% on Gemma3-4B-It, yielding an improvement of up to 6% for both models compared to the Standard RAG prompt. This research also offers concrete analysis and actionable recommendations for designing effective and efficient prompts for SLM-based RAG systems, practically for deployment in resource-constrained environments.
Delta-Audit: Explaining What Changes When Models Change
Aug 27, 2025



Model updates (new hyperparameters, kernels, depths, solvers, or data) change performance, but the \emph{reason} often remains opaque. We introduce \textbf{Delta-Attribution} (\mbox{$\Delta$-Attribution}), a model-agnostic framework that explains \emph{what changed} between versions $A$ and $B$ by differencing per-feature attributions: $\Delta\phi(x)=\phi_B(x)-\phi_A(x)$. We evaluate $\Delta\phi$ with a \emph{$\Delta$-Attribution Quality Suite} covering magnitude/sparsity (L1, Top-$k$, entropy), agreement/shift (rank-overlap@10, Jensen--Shannon divergence), behavioural alignment (Delta Conservation Error, DCE; Behaviour--Attribution Coupling, BAC; CO$\Delta$F), and robustness (noise, baseline sensitivity, grouped occlusion). Instantiated via fast occlusion/clamping in standardized space with a class-anchored margin and baseline averaging, we audit 45 settings: five classical families (Logistic Regression, SVC, Random Forests, Gradient Boosting, $k$NN), three datasets (Breast Cancer, Wine, Digits), and three A/B pairs per family. \textbf{Findings.} Inductive-bias changes yield large, behaviour-aligned deltas (e.g., SVC poly$\!\rightarrow$rbf on Breast Cancer: BAC$\approx$0.998, DCE$\approx$6.6; Random Forest feature-rule swap on Digits: BAC$\approx$0.997, DCE$\approx$7.5), while ``cosmetic'' tweaks (SVC \texttt{gamma=scale} vs.\ \texttt{auto}, $k$NN search) show rank-overlap@10$=1.0$ and DCE$\approx$0. The largest redistribution appears for deeper GB on Breast Cancer (JSD$\approx$0.357). $\Delta$-Attribution offers a lightweight update audit that complements accuracy by distinguishing benign changes from behaviourally meaningful or risky reliance shifts.
Context Awareness Gate For Retrieval Augmented Generation
Nov 25, 2024Retrieval Augmented Generation (RAG) has emerged as a widely adopted approach to mitigate the limitations of large language models (LLMs) in answering domain-specific questions. Previous research has predominantly focused on improving the accuracy and quality of retrieved data chunks to enhance the overall performance of the generation pipeline. However, despite ongoing advancements, the critical issue of retrieving irrelevant information -- which can impair the ability of the model to utilize its internal knowledge effectively -- has received minimal attention. In this work, we investigate the impact of retrieving irrelevant information in open-domain question answering, highlighting its significant detrimental effect on the quality of LLM outputs. To address this challenge, we propose the Context Awareness Gate (CAG) architecture, a novel mechanism that dynamically adjusts the LLMs' input prompt based on whether the user query necessitates external context retrieval. Additionally, we introduce the Vector Candidates method, a core mathematical component of CAG that is statistical, LLM-independent, and highly scalable. We further examine the distributions of relationships between contexts and questions, presenting a statistical analysis of these distributions. This analysis can be leveraged to enhance the context retrieval process in Retrieval Augmented Generation (RAG) systems.
Exploring the Potential of Machine Translation for Generating Named Entity Datasets: A Case Study between Persian and English
Feb 19, 2023This study focuses on the generation of Persian named entity datasets through the application of machine translation on English datasets. The generated datasets were evaluated by experimenting with one monolingual and one multilingual transformer model. Notably, the CoNLL 2003 dataset has achieved the highest F1 score of 85.11%. In contrast, the WNUT 2017 dataset yielded the lowest F1 score of 40.02%. The results of this study highlight the potential of machine translation in creating high-quality named entity recognition datasets for low-resource languages like Persian. The study compares the performance of these generated datasets with English named entity recognition systems and provides insights into the effectiveness of machine translation for this task. Additionally, this approach could be used to augment data in low-resource language or create noisy data to make named entity systems more robust and improve them.
An Evaluation of Persian-English Machine Translation Datasets with Transformers
Feb 01, 2023



Nowadays, many researchers are focusing their attention on the subject of machine translation (MT). However, Persian machine translation has remained unexplored despite a vast amount of research being conducted in languages with high resources, such as English. Moreover, while a substantial amount of research has been undertaken in statistical machine translation for some datasets in Persian, there is currently no standard baseline for transformer-based text2text models on each corpus. This study collected and analysed the most popular and valuable parallel corpora, which were used for Persian-English translation. Furthermore, we fine-tuned and evaluated two state-of-the-art attention-based seq2seq models on each dataset separately (48 results). We hope this paper will assist researchers in comparing their Persian to English and vice versa machine translation results to a standard baseline.
BAS: An Answer Selection Method Using BERT Language Model
Nov 11, 2019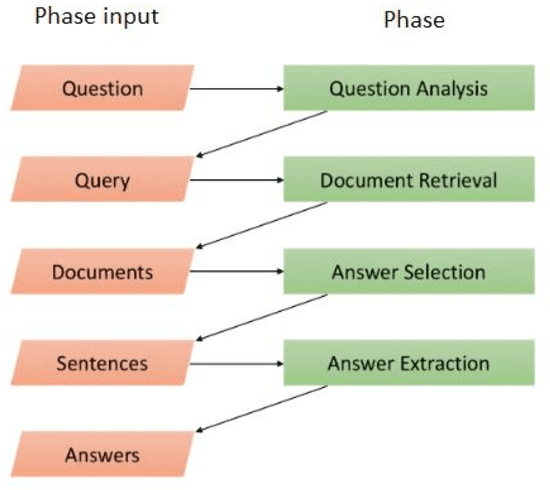



In recent years, Question Answering systems have become more popular and widely used by users. Despite the increasing popularity of these systems, the their performance is not even sufficient for textual data and requires further research. These systems consist of several parts that one of them is the Answer Selection component. This component detects the most relevant answer from a list of candidate answers. The methods presented in previous researches have attempted to provide an independent model to undertake the answer-selection task. An independent model cannot comprehend the syntactic and semantic features of questions and answers with a small training dataset. To fill this gap, language models can be employed in implementing the answer selection part. This action enables the model to have a better understanding of the language in order to understand questions and answers better than previous works. In this research, we will present the "BAS" (BERT Answer Selection) that uses the BERT language model to comprehend language. The empirical results of applying the model on the TrecQA Raw, TrecQA Clean, and WikiQA datasets demonstrate that using a robust language model such as BERT can enhance the performance. Using a more robust classifier also enhances the effect of the language model on the answer selection component. The results demonstrate that language comprehension is an essential requirement in natural language processing tasks such as answer-selection.
Attention-based Pairwise Multi-Perspective Convolutional Neural Network for Answer Selection in Question Answering
Sep 14, 2019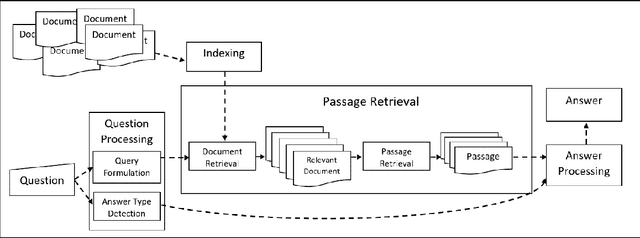
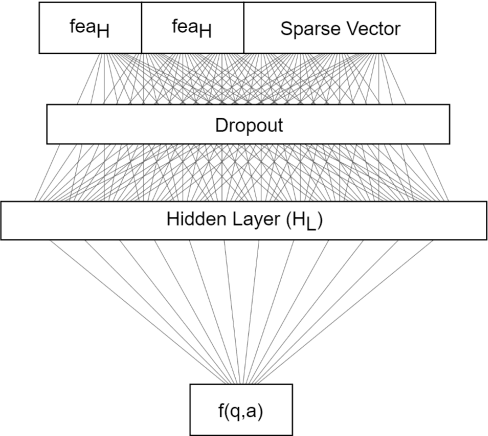
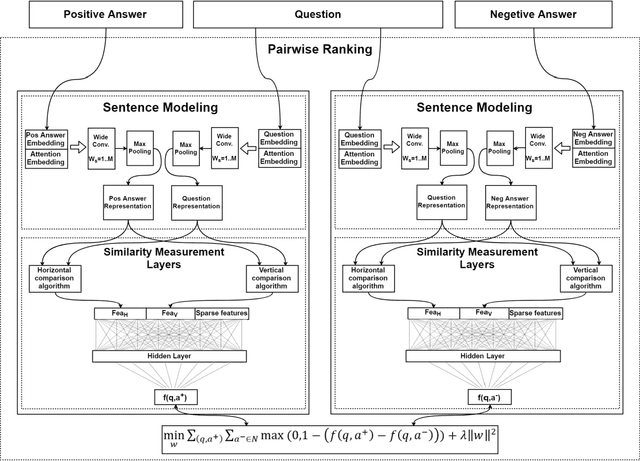
Over the past few years, question answering and information retrieval systems have become widely used. These systems attempt to find the answer of the asked questions from raw text sources. A component of these systems is Answer Selection which selects the most relevant answer from candidate answers. Syntactic similarities were mostly used to compute the similarity, but in recent works, deep neural networks have been used which have made a significant improvement in this field. In this research, a model is proposed to select the most relevant answers to the factoid question from the candidate answers. The proposed model ranks the candidate answers in terms of semantic and syntactic similarity to the question, using convolutional neural networks. In this research, Attention mechanism and Sparse feature vector use the context-sensitive interactions between questions and answer sentence. Wide convolution increases the importance of the interrogative word. Pairwise ranking is used to learn differentiable representations to distinguish positive and negative answers. Our model indicates strong performance on the TrecQA beating previous state-of-the-art systems by 2.62% in MAP and 2.13% in MRR while using the benefits of no additional syntactic parsers and external tools. The results show that using context-sensitive interactions between question and answer sentences can help to find the correct answer more accurately.