 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnmasking the Factual-Conceptual Gap in Persian Language Models
Feb 19, 2026While emerging Persian NLP benchmarks have expanded into pragmatics and politeness, they rarely distinguish between memorized cultural facts and the ability to reason about implicit social norms. We introduce DivanBench, a diagnostic benchmark focused on superstitions and customs, arbitrary, context-dependent rules that resist simple logical deduction. Through 315 questions across three task types (factual retrieval, paired scenario verification, and situational reasoning), we evaluate seven Persian LLMs and reveal three critical failures: most models exhibit severe acquiescence bias, correctly identifying appropriate behaviors but failing to reject clear violations; continuous Persian pretraining amplifies this bias rather than improving reasoning, often degrading the model's ability to discern contradictions; and all models show a 21\% performance gap between retrieving factual knowledge and applying it in scenarios. These findings demonstrate that cultural competence requires more than scaling monolingual data, as current models learn to mimic cultural patterns without internalizing the underlying schemas.
TDGNet: Hallucination Detection in Diffusion Language Models via Temporal Dynamic Graphs
Feb 08, 2026Diffusion language models (D-LLMs) offer parallel denoising and bidirectional context, but hallucination detection for D-LLMs remains underexplored. Prior detectors developed for auto-regressive LLMs typically rely on single-pass cues and do not directly transfer to diffusion generation, where factuality evidence is distributed across the denoising trajectory and may appear, drift, or be self-corrected over time. We introduce TDGNet, a temporal dynamic graph framework that formulates hallucination detection as learning over evolving token-level attention graphs. At each denoising step, we sparsify the attention graph and update per-token memories via message passing, then apply temporal attention to aggregate trajectory-wide evidence for final prediction. Experiments on LLaDA-8B and Dream-7B across QA benchmarks show consistent AUROC improvements over output-based, latent-based, and static-graph baselines, with single-pass inference and modest overhead. These results highlight the importance of temporal reasoning on attention graphs for robust hallucination detection in diffusion language models.
3D-Guided Scalable Flow Matching for Generating Volumetric Tissue Spatial Transcriptomics from Serial Histology
Nov 18, 2025A scalable and robust 3D tissue transcriptomics profile can enable a holistic understanding of tissue organization and provide deeper insights into human biology and disease. Most predictive algorithms that infer ST directly from histology treat each section independently and ignore 3D structure, while existing 3D-aware approaches are not generative and do not scale well. We present Holographic Tissue Expression Inpainting and Analysis (HoloTea), a 3D-aware flow-matching framework that imputes spot-level gene expression from H&E while explicitly using information from adjacent sections. Our key idea is to retrieve morphologically corresponding spots on neighboring slides in a shared feature space and fuse this cross section context into a lightweight ControlNet, allowing conditioning to follow anatomical continuity. To better capture the count nature of the data, we introduce a 3D-consistent prior for flow matching that combines a learned zero-inflated negative binomial (ZINB) prior with a spatial-empirical prior constructed from neighboring sections. A global attention block introduces 3D H&E scaling linearly with the number of spots in the slide, enabling training and inference on large 3D ST datasets. Across three spatial transcriptomics datasets spanning different tissue types and resolutions, HoloTea consistently improves 3D expression accuracy and generalization compared to 2D and 3D baselines. We envision HoloTea advancing the creation of accurate 3D virtual tissues, ultimately accelerating biomarker discovery and deepening our understanding of disease.
Delta-Audit: Explaining What Changes When Models Change
Aug 27, 2025



Model updates (new hyperparameters, kernels, depths, solvers, or data) change performance, but the \emph{reason} often remains opaque. We introduce \textbf{Delta-Attribution} (\mbox{$\Delta$-Attribution}), a model-agnostic framework that explains \emph{what changed} between versions $A$ and $B$ by differencing per-feature attributions: $\Delta\phi(x)=\phi_B(x)-\phi_A(x)$. We evaluate $\Delta\phi$ with a \emph{$\Delta$-Attribution Quality Suite} covering magnitude/sparsity (L1, Top-$k$, entropy), agreement/shift (rank-overlap@10, Jensen--Shannon divergence), behavioural alignment (Delta Conservation Error, DCE; Behaviour--Attribution Coupling, BAC; CO$\Delta$F), and robustness (noise, baseline sensitivity, grouped occlusion). Instantiated via fast occlusion/clamping in standardized space with a class-anchored margin and baseline averaging, we audit 45 settings: five classical families (Logistic Regression, SVC, Random Forests, Gradient Boosting, $k$NN), three datasets (Breast Cancer, Wine, Digits), and three A/B pairs per family. \textbf{Findings.} Inductive-bias changes yield large, behaviour-aligned deltas (e.g., SVC poly$\!\rightarrow$rbf on Breast Cancer: BAC$\approx$0.998, DCE$\approx$6.6; Random Forest feature-rule swap on Digits: BAC$\approx$0.997, DCE$\approx$7.5), while ``cosmetic'' tweaks (SVC \texttt{gamma=scale} vs.\ \texttt{auto}, $k$NN search) show rank-overlap@10$=1.0$ and DCE$\approx$0. The largest redistribution appears for deeper GB on Breast Cancer (JSD$\approx$0.357). $\Delta$-Attribution offers a lightweight update audit that complements accuracy by distinguishing benign changes from behaviourally meaningful or risky reliance shifts.
MEENA (PersianMMMU): Multimodal-Multilingual Educational Exams for N-level Assessment
Aug 24, 2025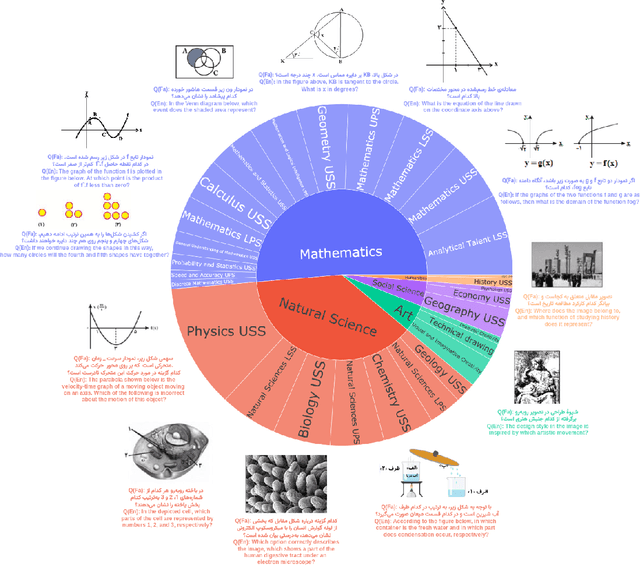

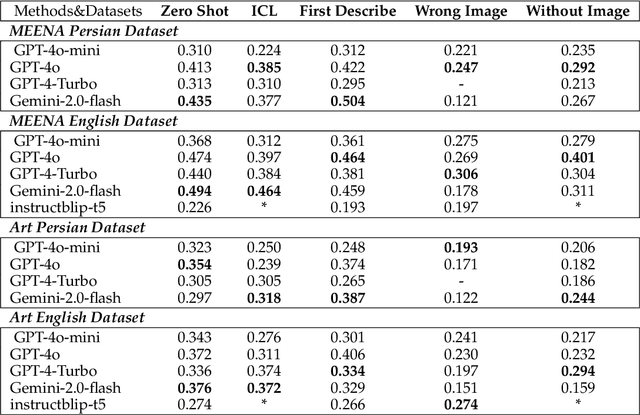
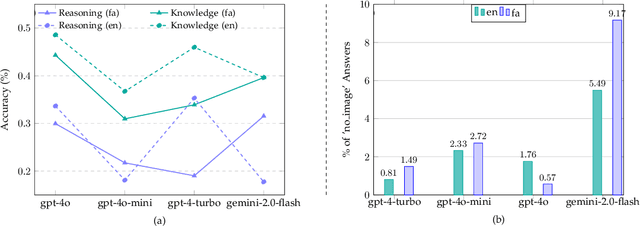
Recent advancements in large vision-language models (VLMs) have primarily focused on English, with limited attention given to other languages. To address this gap, we introduce MEENA (also known as PersianMMMU), the first dataset designed to evaluate Persian VLMs across scientific, reasoning, and human-level understanding tasks. Our dataset comprises approximately 7,500 Persian and 3,000 English questions, covering a wide range of topics such as reasoning, mathematics, physics, diagrams, charts, and Persian art and literature. Key features of MEENA include: (1) diverse subject coverage spanning various educational levels, from primary to upper secondary school, (2) rich metadata, including difficulty levels and descriptive answers, (3) original Persian data that preserves cultural nuances, (4) a bilingual structure to assess cross-linguistic performance, and (5) a series of diverse experiments assessing various capabilities, including overall performance, the model's ability to attend to images, and its tendency to generate hallucinations. We hope this benchmark contributes to enhancing VLM capabilities beyond English.
Context Awareness Gate For Retrieval Augmented Generation
Nov 25, 2024Retrieval Augmented Generation (RAG) has emerged as a widely adopted approach to mitigate the limitations of large language models (LLMs) in answering domain-specific questions. Previous research has predominantly focused on improving the accuracy and quality of retrieved data chunks to enhance the overall performance of the generation pipeline. However, despite ongoing advancements, the critical issue of retrieving irrelevant information -- which can impair the ability of the model to utilize its internal knowledge effectively -- has received minimal attention. In this work, we investigate the impact of retrieving irrelevant information in open-domain question answering, highlighting its significant detrimental effect on the quality of LLM outputs. To address this challenge, we propose the Context Awareness Gate (CAG) architecture, a novel mechanism that dynamically adjusts the LLMs' input prompt based on whether the user query necessitates external context retrieval. Additionally, we introduce the Vector Candidates method, a core mathematical component of CAG that is statistical, LLM-independent, and highly scalable. We further examine the distributions of relationships between contexts and questions, presenting a statistical analysis of these distributions. This analysis can be leveraged to enhance the context retrieval process in Retrieval Augmented Generation (RAG) systems.
Hidden in Plain Sight: Evaluating Abstract Shape Recognition in Vision-Language Models
Nov 09, 2024Despite the importance of shape perception in human vision, early neural image classifiers relied less on shape information for object recognition than other (often spurious) features. While recent research suggests that current large Vision-Language Models (VLMs) exhibit more reliance on shape, we find them to still be seriously limited in this regard. To quantify such limitations, we introduce IllusionBench, a dataset that challenges current cutting-edge VLMs to decipher shape information when the shape is represented by an arrangement of visual elements in a scene. Our extensive evaluations reveal that, while these shapes are easily detectable by human annotators, current VLMs struggle to recognize them, indicating important avenues for future work in developing more robust visual perception systems. The full dataset and codebase are available at: \url{https://arshiahemmat.github.io/illusionbench/}