 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArticulate3D: Zero-Shot Text-Driven 3D Object Posing
Aug 26, 2025We propose a training-free method, Articulate3D, to pose a 3D asset through language control. Despite advances in vision and language models, this task remains surprisingly challenging. To achieve this goal, we decompose the problem into two steps. We modify a powerful image-generator to create target images conditioned on the input image and a text instruction. We then align the mesh to the target images through a multi-view pose optimisation step. In detail, we introduce a self-attention rewiring mechanism (RSActrl) that decouples the source structure from pose within an image generative model, allowing it to maintain a consistent structure across varying poses. We observed that differentiable rendering is an unreliable signal for articulation optimisation; instead, we use keypoints to establish correspondences between input and target images. The effectiveness of Articulate3D is demonstrated across a diverse range of 3D objects and free-form text prompts, successfully manipulating poses while maintaining the original identity of the mesh. Quantitative evaluations and a comparative user study, in which our method was preferred over 85\% of the time, confirm its superiority over existing approaches. Project page:https://odeb1.github.io/articulate3d_page_deb/
How Visual Representations Map to Language Feature Space in Multimodal LLMs
Jun 13, 2025Effective multimodal reasoning depends on the alignment of visual and linguistic representations, yet the mechanisms by which vision-language models (VLMs) achieve this alignment remain poorly understood. We introduce a methodological framework that deliberately maintains a frozen large language model (LLM) and a frozen vision transformer (ViT), connected solely by training a linear adapter during visual instruction tuning. This design is fundamental to our approach: by keeping the language model frozen, we ensure it maintains its original language representations without adaptation to visual data. Consequently, the linear adapter must map visual features directly into the LLM's existing representational space rather than allowing the language model to develop specialized visual understanding through fine-tuning. Our experimental design uniquely enables the use of pre-trained sparse autoencoders (SAEs) of the LLM as analytical probes. These SAEs remain perfectly aligned with the unchanged language model and serve as a snapshot of the learned language feature-representations. Through systematic analysis of SAE reconstruction error, sparsity patterns, and feature SAE descriptions, we reveal the layer-wise progression through which visual representations gradually align with language feature representations, converging in middle-to-later layers. This suggests a fundamental misalignment between ViT outputs and early LLM layers, raising important questions about whether current adapter-based architectures optimally facilitate cross-modal representation learning.
SafetyDPO: Scalable Safety Alignment for Text-to-Image Generation
Dec 13, 2024



Text-to-image (T2I) models have become widespread, but their limited safety guardrails expose end users to harmful content and potentially allow for model misuse. Current safety measures are typically limited to text-based filtering or concept removal strategies, able to remove just a few concepts from the model's generative capabilities. In this work, we introduce SafetyDPO, a method for safety alignment of T2I models through Direct Preference Optimization (DPO). We enable the application of DPO for safety purposes in T2I models by synthetically generating a dataset of harmful and safe image-text pairs, which we call CoProV2. Using a custom DPO strategy and this dataset, we train safety experts, in the form of low-rank adaptation (LoRA) matrices, able to guide the generation process away from specific safety-related concepts. Then, we merge the experts into a single LoRA using a novel merging strategy for optimal scaling performance. This expert-based approach enables scalability, allowing us to remove 7 times more harmful concepts from T2I models compared to baselines. SafetyDPO consistently outperforms the state-of-the-art on many benchmarks and establishes new practices for safety alignment in T2I networks. Code and data will be shared at https://safetydpo.github.io/.
Effortless Efficiency: Low-Cost Pruning of Diffusion Models
Dec 03, 2024Diffusion models have achieved impressive advancements in various vision tasks. However, these gains often rely on increasing model size, which escalates computational complexity and memory demands, complicating deployment, raising inference costs, and causing environmental impact. While some studies have explored pruning techniques to improve the memory efficiency of diffusion models, most existing methods require extensive retraining to retain the model performance. Retraining a modern large diffusion model is extremely costly and resource-intensive, which limits the practicality of these methods. In this work, we achieve low-cost diffusion pruning without retraining by proposing a model-agnostic structural pruning framework for diffusion models that learns a differentiable mask to sparsify the model. To ensure effective pruning that preserves the quality of the final denoised latent, we design a novel end-to-end pruning objective that spans the entire diffusion process. As end-to-end pruning is memory-intensive, we further propose time step gradient checkpointing, a technique that significantly reduces memory usage during optimization, enabling end-to-end pruning within a limited memory budget. Results on state-of-the-art U-Net diffusion models SDXL and diffusion transformers (FLUX) demonstrate that our method can effectively prune up to 20% parameters with minimal perceptible performance degradation, and notably, without the need for model retraining. We also showcase that our method can still prune on top of time step distilled diffusion models.
Hidden in Plain Sight: Evaluating Abstract Shape Recognition in Vision-Language Models
Nov 09, 2024Despite the importance of shape perception in human vision, early neural image classifiers relied less on shape information for object recognition than other (often spurious) features. While recent research suggests that current large Vision-Language Models (VLMs) exhibit more reliance on shape, we find them to still be seriously limited in this regard. To quantify such limitations, we introduce IllusionBench, a dataset that challenges current cutting-edge VLMs to decipher shape information when the shape is represented by an arrangement of visual elements in a scene. Our extensive evaluations reveal that, while these shapes are easily detectable by human annotators, current VLMs struggle to recognize them, indicating important avenues for future work in developing more robust visual perception systems. The full dataset and codebase are available at: \url{https://arshiahemmat.github.io/illusionbench/}
Sparse Autoencoders Reveal Universal Feature Spaces Across Large Language Models
Oct 09, 2024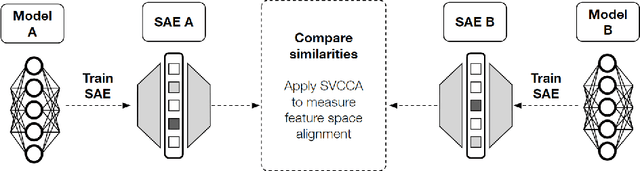
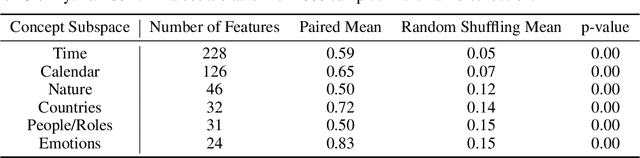
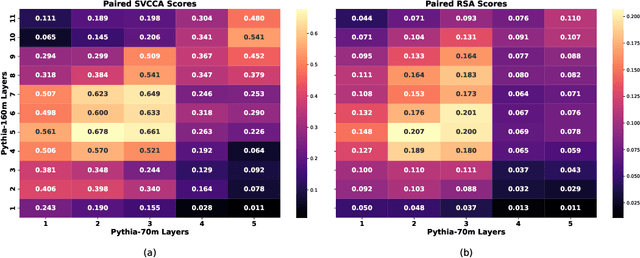
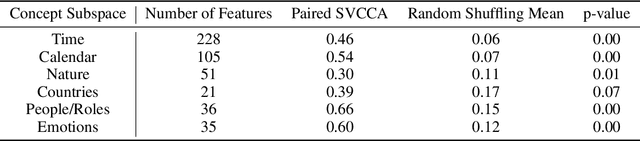
We investigate feature universality in large language models (LLMs), a research field that aims to understand how different models similarly represent concepts in the latent spaces of their intermediate layers. Demonstrating feature universality allows discoveries about latent representations to generalize across several models. However, comparing features across LLMs is challenging due to polysemanticity, in which individual neurons often correspond to multiple features rather than distinct ones. This makes it difficult to disentangle and match features across different models. To address this issue, we employ a method known as dictionary learning by using sparse autoencoders (SAEs) to transform LLM activations into more interpretable spaces spanned by neurons corresponding to individual features. After matching feature neurons across models via activation correlation, we apply representational space similarity metrics like Singular Value Canonical Correlation Analysis to analyze these SAE features across different LLMs. Our experiments reveal significant similarities in SAE feature spaces across various LLMs, providing new evidence for feature universality.
The Cognitive Revolution in Interpretability: From Explaining Behavior to Interpreting Representations and Algorithms
Aug 11, 2024Artificial neural networks have long been understood as "black boxes": though we know their computation graphs and learned parameters, the knowledge encoded by these weights and functions they perform are not inherently interpretable. As such, from the early days of deep learning, there have been efforts to explain these models' behavior and understand them internally; and recently, mechanistic interpretability (MI) has emerged as a distinct research area studying the features and implicit algorithms learned by foundation models such as large language models. In this work, we aim to ground MI in the context of cognitive science, which has long struggled with analogous questions in studying and explaining the behavior of "black box" intelligent systems like the human brain. We leverage several important ideas and developments in the history of cognitive science to disentangle divergent objectives in MI and indicate a clear path forward. First, we argue that current methods are ripe to facilitate a transition in deep learning interpretation echoing the "cognitive revolution" in 20th-century psychology that shifted the study of human psychology from pure behaviorism toward mental representations and processing. Second, we propose a taxonomy mirroring key parallels in computational neuroscience to describe two broad categories of MI research, semantic interpretation (what latent representations are learned and used) and algorithmic interpretation (what operations are performed over representations) to elucidate their divergent goals and objects of study. Finally, we elaborate the parallels and distinctions between various approaches in both categories, analyze the respective strengths and weaknesses of representative works, clarify underlying assumptions, outline key challenges, and discuss the possibility of unifying these modes of interpretation under a common framework.
Learning Visual Prompts for Guiding the Attention of Vision Transformers
Jun 05, 2024
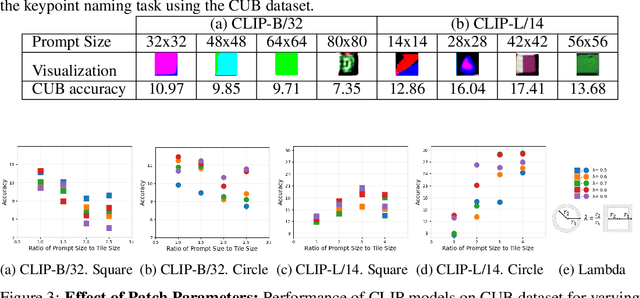
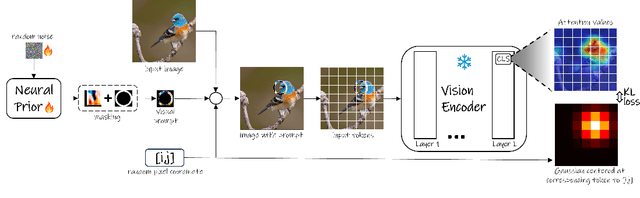

Visual prompting infuses visual information into the input image to adapt models toward specific predictions and tasks. Recently, manually crafted markers such as red circles are shown to guide the model to attend to a target region on the image. However, these markers only work on models trained with data containing those markers. Moreover, finding these prompts requires guesswork or prior knowledge of the domain on which the model is trained. This work circumvents manual design constraints by proposing to learn the visual prompts for guiding the attention of vision transformers. The learned visual prompt, added to any input image would redirect the attention of the pre-trained vision transformer to its spatial location on the image. Specifically, the prompt is learned in a self-supervised manner without requiring annotations and without fine-tuning the vision transformer. Our experiments demonstrate the effectiveness of the proposed optimization-based visual prompting strategy across various pre-trained vision encoders.
Latent Guard: a Safety Framework for Text-to-image Generation
Apr 11, 2024With the ability to generate high-quality images, text-to-image (T2I) models can be exploited for creating inappropriate content. To prevent misuse, existing safety measures are either based on text blacklists, which can be easily circumvented, or harmful content classification, requiring large datasets for training and offering low flexibility. Hence, we propose Latent Guard, a framework designed to improve safety measures in text-to-image generation. Inspired by blacklist-based approaches, Latent Guard learns a latent space on top of the T2I model's text encoder, where it is possible to check the presence of harmful concepts in the input text embeddings. Our proposed framework is composed of a data generation pipeline specific to the task using large language models, ad-hoc architectural components, and a contrastive learning strategy to benefit from the generated data. The effectiveness of our method is verified on three datasets and against four baselines. Code and data will be shared at https://github.com/rt219/LatentGuard.
On Discprecncies between Perturbation Evaluations of Graph Neural Network Attributions
Jan 01, 2024Neural networks are increasingly finding their way into the realm of graphs and modeling relationships between features. Concurrently graph neural network explanation approaches are being invented to uncover relationships between the nodes of the graphs. However, there is a disparity between the existing attribution methods, and it is unclear which attribution to trust. Therefore research has introduced evaluation experiments that assess them from different perspectives. In this work, we assess attribution methods from a perspective not previously explored in the graph domain: retraining. The core idea is to retrain the network on important (or not important) relationships as identified by the attributions and evaluate how networks can generalize based on these relationships. We reformulate the retraining framework to sidestep issues lurking in the previous formulation and propose guidelines for correct analysis. We run our analysis on four state-of-the-art GNN attribution methods and five synthetic and real-world graph classification datasets. The analysis reveals that attributions perform variably depending on the dataset and the network. Most importantly, we observe that the famous GNNExplainer performs similarly to an arbitrary designation of edge importance. The study concludes that the retraining evaluation cannot be used as a generalized benchmark and recommends it as a toolset to evaluate attributions on a specifically addressed network, dataset, and sparsity.