 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Visual Prompts for Guiding the Attention of Vision Transformers
Jun 05, 2024
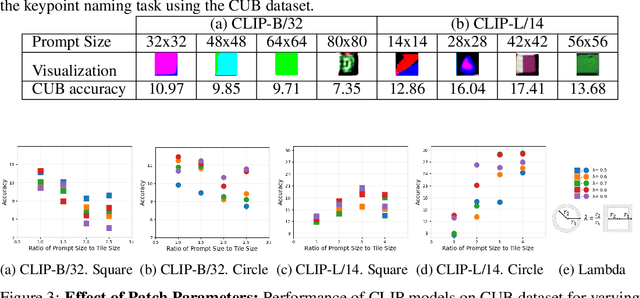
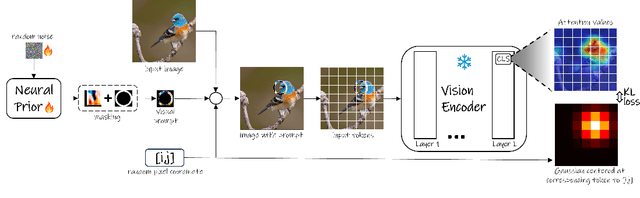

Visual prompting infuses visual information into the input image to adapt models toward specific predictions and tasks. Recently, manually crafted markers such as red circles are shown to guide the model to attend to a target region on the image. However, these markers only work on models trained with data containing those markers. Moreover, finding these prompts requires guesswork or prior knowledge of the domain on which the model is trained. This work circumvents manual design constraints by proposing to learn the visual prompts for guiding the attention of vision transformers. The learned visual prompt, added to any input image would redirect the attention of the pre-trained vision transformer to its spatial location on the image. Specifically, the prompt is learned in a self-supervised manner without requiring annotations and without fine-tuning the vision transformer. Our experiments demonstrate the effectiveness of the proposed optimization-based visual prompting strategy across various pre-trained vision encoders.
On Discprecncies between Perturbation Evaluations of Graph Neural Network Attributions
Jan 01, 2024Neural networks are increasingly finding their way into the realm of graphs and modeling relationships between features. Concurrently graph neural network explanation approaches are being invented to uncover relationships between the nodes of the graphs. However, there is a disparity between the existing attribution methods, and it is unclear which attribution to trust. Therefore research has introduced evaluation experiments that assess them from different perspectives. In this work, we assess attribution methods from a perspective not previously explored in the graph domain: retraining. The core idea is to retrain the network on important (or not important) relationships as identified by the attributions and evaluate how networks can generalize based on these relationships. We reformulate the retraining framework to sidestep issues lurking in the previous formulation and propose guidelines for correct analysis. We run our analysis on four state-of-the-art GNN attribution methods and five synthetic and real-world graph classification datasets. The analysis reveals that attributions perform variably depending on the dataset and the network. Most importantly, we observe that the famous GNNExplainer performs similarly to an arbitrary designation of edge importance. The study concludes that the retraining evaluation cannot be used as a generalized benchmark and recommends it as a toolset to evaluate attributions on a specifically addressed network, dataset, and sparsity.