 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust-U1: Can MLLMs Self-Recover Corrupted Visual Content for Robust Understanding?
Jun 06, 2026Multimodal Large Language Models (MLLMs) have demonstrated remarkable success in visual understanding, yet their performance degrades significantly under real-world visual corruptions. While existing robustness enhancement approaches exist, they are limited: black-box feature alignment lacks interpretability, and white-box text-based reasoning cannot restore lost pixel-level details. This work investigates a fundamental research question: Can MLLMs recover corrupted visual content by themselves? To address this, we propose Robust-U1, a novel framework that equips MLLMs with explicit visual self-recovery capability for robust understanding. The approach comprises three core stages: supervised fine-tuning for initial reconstruction, reinforcement learning with dual rewards (pixel-level SSIM and semantic-level CLIP similarity) for aligning high visual quality, and multimodal reasoning that jointly considers both the corrupted input and the recovered image. Extensive experiments demonstrate that Robust-U1 achieves state-of-the-art robustness on the real-world corruption benchmark and maintains superior performance under adversarial corruptions on general VQA benchmarks. Analysis confirms that high-quality visual recovery directly enhances reasoning performance, establishing self-recovery as a critical mechanism for robust visual understanding. The source code is available at https://github.com/jqtangust/Robust-U1.
AvatarPointillist: AutoRegressive 4D Gaussian Avatarization
Apr 06, 2026We introduce AvatarPointillist, a novel framework for generating dynamic 4D Gaussian avatars from a single portrait image. At the core of our method is a decoder-only Transformer that autoregressively generates a point cloud for 3D Gaussian Splatting. This sequential approach allows for precise, adaptive construction, dynamically adjusting point density and the total number of points based on the subject's complexity. During point generation, the AR model also jointly predicts per-point binding information, enabling realistic animation. After generation, a dedicated Gaussian decoder converts the points into complete, renderable Gaussian attributes. We demonstrate that conditioning the decoder on the latent features from the AR generator enables effective interaction between stages and markedly improves fidelity. Extensive experiments validate that AvatarPointillist produces high-quality, photorealistic, and controllable avatars. We believe this autoregressive formulation represents a new paradigm for avatar generation, and we will release our code inspire future research.
RenderFlow: Single-Step Neural Rendering via Flow Matching
Jan 11, 2026Conventional physically based rendering (PBR) pipelines generate photorealistic images through computationally intensive light transport simulations. Although recent deep learning approaches leverage diffusion model priors with geometry buffers (G-buffers) to produce visually compelling results without explicit scene geometry or light simulation, they remain constrained by two major limitations. First, the iterative nature of the diffusion process introduces substantial latency. Second, the inherent stochasticity of these generative models compromises physical accuracy and temporal consistency. In response to these challenges, we propose a novel, end-to-end, deterministic, single-step neural rendering framework, RenderFlow, built upon a flow matching paradigm. To further strengthen both rendering quality and generalization, we propose an efficient and effective module for sparse keyframe guidance. Our method significantly accelerates the rendering process and, by optionally incorporating sparsely rendered keyframes as guidance, enhances both the physical plausibility and overall visual quality of the output. The resulting pipeline achieves near real-time performance with photorealistic rendering quality, effectively bridging the gap between the efficiency of modern generative models and the precision of traditional physically based rendering. Furthermore, we demonstrate the versatility of our framework by introducing a lightweight, adapter-based module that efficiently repurposes the pretrained forward model for the inverse rendering task of intrinsic decomposition.
LongVideoAgent: Multi-Agent Reasoning with Long Videos
Dec 23, 2025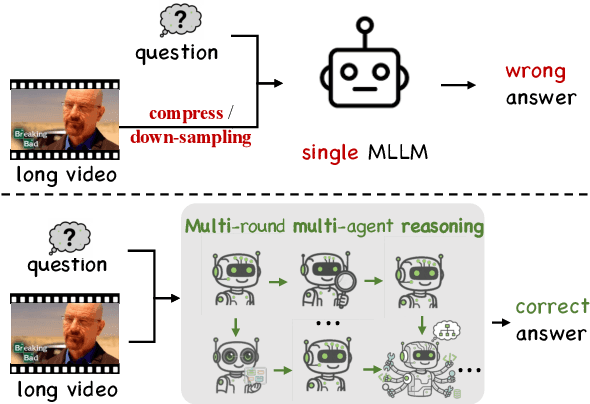


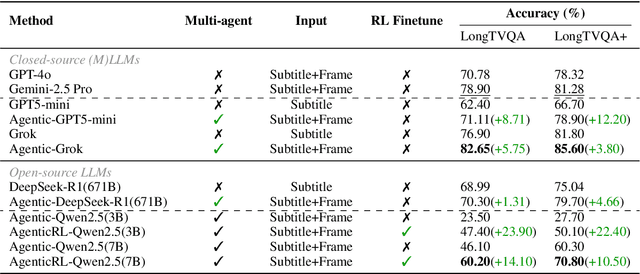
Recent advances in multimodal LLMs and systems that use tools for long-video QA point to the promise of reasoning over hour-long episodes. However, many methods still compress content into lossy summaries or rely on limited toolsets, weakening temporal grounding and missing fine-grained cues. We propose a multi-agent framework in which a master LLM coordinates a grounding agent to localize question-relevant segments and a vision agent to extract targeted textual observations. The master agent plans with a step limit, and is trained with reinforcement learning to encourage concise, correct, and efficient multi-agent cooperation. This design helps the master agent focus on relevant clips via grounding, complements subtitles with visual detail, and yields interpretable trajectories. On our proposed LongTVQA and LongTVQA+ which are episode-level datasets aggregated from TVQA/TVQA+, our multi-agent system significantly outperforms strong non-agent baselines. Experiments also show reinforcement learning further strengthens reasoning and planning for the trained agent. Code and data will be shared at https://longvideoagent.github.io/.
Robust-R1: Degradation-Aware Reasoning for Robust Visual Understanding
Dec 19, 2025Multimodal Large Language Models struggle to maintain reliable performance under extreme real-world visual degradations, which impede their practical robustness. Existing robust MLLMs predominantly rely on implicit training/adaptation that focuses solely on visual encoder generalization, suffering from limited interpretability and isolated optimization. To overcome these limitations, we propose Robust-R1, a novel framework that explicitly models visual degradations through structured reasoning chains. Our approach integrates: (i) supervised fine-tuning for degradation-aware reasoning foundations, (ii) reward-driven alignment for accurately perceiving degradation parameters, and (iii) dynamic reasoning depth scaling adapted to degradation intensity. To facilitate this approach, we introduce a specialized 11K dataset featuring realistic degradations synthesized across four critical real-world visual processing stages, each annotated with structured chains connecting degradation parameters, perceptual influence, pristine semantic reasoning chain, and conclusion. Comprehensive evaluations demonstrate state-of-the-art robustness: Robust-R1 outperforms all general and robust baselines on the real-world degradation benchmark R-Bench, while maintaining superior anti-degradation performance under multi-intensity adversarial degradations on MMMB, MMStar, and RealWorldQA.
Pointing to a Llama and Call it a Camel: On the Sycophancy of Multimodal Large Language Models
Sep 19, 2025



Multimodal large language models (MLLMs) have demonstrated extraordinary capabilities in conducting conversations based on image inputs. However, we observe that MLLMs exhibit a pronounced form of visual sycophantic behavior. While similar behavior has also been noted in text-based large language models (LLMs), it becomes significantly more prominent when MLLMs process image inputs. We refer to this phenomenon as the "sycophantic modality gap." To better understand this issue, we further analyze the factors that contribute to the exacerbation of this gap. To mitigate the visual sycophantic behavior, we first experiment with naive supervised fine-tuning to help the MLLM resist misleading instructions from the user. However, we find that this approach also makes the MLLM overly resistant to corrective instructions (i.e., stubborn even if it is wrong). To alleviate this trade-off, we propose Sycophantic Reflective Tuning (SRT), which enables the MLLM to engage in reflective reasoning, allowing it to determine whether a user's instruction is misleading or corrective before drawing a conclusion. After applying SRT, we observe a significant reduction in sycophantic behavior toward misleading instructions, without resulting in excessive stubbornness when receiving corrective instructions.
Follow-Your-Instruction: A Comprehensive MLLM Agent for World Data Synthesis
Aug 07, 2025With the growing demands of AI-generated content (AIGC), the need for high-quality, diverse, and scalable data has become increasingly crucial. However, collecting large-scale real-world data remains costly and time-consuming, hindering the development of downstream applications. While some works attempt to collect task-specific data via a rendering process, most approaches still rely on manual scene construction, limiting their scalability and accuracy. To address these challenges, we propose Follow-Your-Instruction, a Multimodal Large Language Model (MLLM)-driven framework for automatically synthesizing high-quality 2D, 3D, and 4D data. Our \textbf{Follow-Your-Instruction} first collects assets and their associated descriptions through multimodal inputs using the MLLM-Collector. Then it constructs 3D layouts, and leverages Vision-Language Models (VLMs) for semantic refinement through multi-view scenes with the MLLM-Generator and MLLM-Optimizer, respectively. Finally, it uses MLLM-Planner to generate temporally coherent future frames. We evaluate the quality of the generated data through comprehensive experiments on the 2D, 3D, and 4D generative tasks. The results show that our synthetic data significantly boosts the performance of existing baseline models, demonstrating Follow-Your-Instruction's potential as a scalable and effective data engine for generative intelligence.
ModelGrow: Continual Text-to-Video Pre-training with Model Expansion and Language Understanding Enhancement
Dec 25, 2024Text-to-video (T2V) generation has gained significant attention recently. However, the costs of training a T2V model from scratch remain persistently high, and there is considerable room for improving the generation performance, especially under limited computation resources. This work explores the continual general pre-training of text-to-video models, enabling the model to "grow" its abilities based on a pre-trained foundation, analogous to how humans acquire new knowledge based on past experiences. There is a lack of extensive study of the continual pre-training techniques in T2V generation. In this work, we take the initial step toward exploring this task systematically and propose ModelGrow. Specifically, we break this task into two key aspects: increasing model capacity and improving semantic understanding. For model capacity, we introduce several novel techniques to expand the model size, enabling it to store new knowledge and improve generation performance. For semantic understanding, we propose a method that leverages large language models as advanced text encoders, integrating them into T2V models to enhance language comprehension and guide generation results according to detailed prompts. This approach enables the model to achieve better semantic alignment, particularly in response to complex user prompts. Extensive experiments demonstrate the effectiveness of our method across various metrics. The source code and the model of ModelGrow will be publicly available.
VideoDPO: Omni-Preference Alignment for Video Diffusion Generation
Dec 18, 2024



Recent progress in generative diffusion models has greatly advanced text-to-video generation. While text-to-video models trained on large-scale, diverse datasets can produce varied outputs, these generations often deviate from user preferences, highlighting the need for preference alignment on pre-trained models. Although Direct Preference Optimization (DPO) has demonstrated significant improvements in language and image generation, we pioneer its adaptation to video diffusion models and propose a VideoDPO pipeline by making several key adjustments. Unlike previous image alignment methods that focus solely on either (i) visual quality or (ii) semantic alignment between text and videos, we comprehensively consider both dimensions and construct a preference score accordingly, which we term the OmniScore. We design a pipeline to automatically collect preference pair data based on the proposed OmniScore and discover that re-weighting these pairs based on the score significantly impacts overall preference alignment. Our experiments demonstrate substantial improvements in both visual quality and semantic alignment, ensuring that no preference aspect is neglected. Code and data will be shared at https://videodpo.github.io/.
SafetyDPO: Scalable Safety Alignment for Text-to-Image Generation
Dec 13, 2024



Text-to-image (T2I) models have become widespread, but their limited safety guardrails expose end users to harmful content and potentially allow for model misuse. Current safety measures are typically limited to text-based filtering or concept removal strategies, able to remove just a few concepts from the model's generative capabilities. In this work, we introduce SafetyDPO, a method for safety alignment of T2I models through Direct Preference Optimization (DPO). We enable the application of DPO for safety purposes in T2I models by synthetically generating a dataset of harmful and safe image-text pairs, which we call CoProV2. Using a custom DPO strategy and this dataset, we train safety experts, in the form of low-rank adaptation (LoRA) matrices, able to guide the generation process away from specific safety-related concepts. Then, we merge the experts into a single LoRA using a novel merging strategy for optimal scaling performance. This expert-based approach enables scalability, allowing us to remove 7 times more harmful concepts from T2I models compared to baselines. SafetyDPO consistently outperforms the state-of-the-art on many benchmarks and establishes new practices for safety alignment in T2I networks. Code and data will be shared at https://safetydpo.github.io/.