 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTRU: Targeted Reverse Update for Efficient Multimodal Recommendation Unlearning
Apr 02, 2026Multimodal recommendation systems (MRS) jointly model user-item interaction graphs and rich item content, but this tight coupling makes user data difficult to remove once learned. Approximate machine unlearning offers an efficient alternative to full retraining, yet existing methods for MRS mainly rely on a largely uniform reverse update across the model. We show that this assumption is fundamentally mismatched to modern MRS: deleted-data influence is not uniformly distributed, but concentrated unevenly across \textit{ranking behavior}, \textit{modality branches}, and \textit{network layers}. This non-uniformity gives rise to three bottlenecks in MRS unlearning: target-item persistence in the collaborative graph, modality imbalance across feature branches, and layer-wise sensitivity in the parameter space. To address this mismatch, we propose \textbf{targeted reverse update} (TRU), a plug-and-play unlearning framework for MRS. Instead of applying a blind global reversal, TRU performs three coordinated interventions across the model hierarchy: a ranking fusion gate to suppress residual target-item influence in ranking, branch-wise modality scaling to preserve retained multimodal representations, and capacity-aware layer isolation to localize reverse updates to deletion-sensitive modules. Experiments across two representative backbones, three datasets, and three unlearning regimes show that TRU consistently achieves a better retain-forget trade-off than prior approximate baselines, while security audits further confirm deeper forgetting and behavior closer to a full retraining on the retained data.
MarineEval: Assessing the Marine Intelligence of Vision-Language Models
Dec 24, 2025We have witnessed promising progress led by large language models (LLMs) and further vision language models (VLMs) in handling various queries as a general-purpose assistant. VLMs, as a bridge to connect the visual world and language corpus, receive both visual content and various text-only user instructions to generate corresponding responses. Though great success has been achieved by VLMs in various fields, in this work, we ask whether the existing VLMs can act as domain experts, accurately answering marine questions, which require significant domain expertise and address special domain challenges/requirements. To comprehensively evaluate the effectiveness and explore the boundary of existing VLMs, we construct the first large-scale marine VLM dataset and benchmark called MarineEval, with 2,000 image-based question-answering pairs. During our dataset construction, we ensure the diversity and coverage of the constructed data: 7 task dimensions and 20 capacity dimensions. The domain requirements are specially integrated into the data construction and further verified by the corresponding marine domain experts. We comprehensively benchmark 17 existing VLMs on our MarineEval and also investigate the limitations of existing models in answering marine research questions. The experimental results reveal that existing VLMs cannot effectively answer the domain-specific questions, and there is still a large room for further performance improvements. We hope our new benchmark and observations will facilitate future research. Project Page: http://marineeval.hkustvgd.com/
ORCA: Object Recognition and Comprehension for Archiving Marine Species
Dec 24, 2025Marine visual understanding is essential for monitoring and protecting marine ecosystems, enabling automatic and scalable biological surveys. However, progress is hindered by limited training data and the lack of a systematic task formulation that aligns domain-specific marine challenges with well-defined computer vision tasks, thereby limiting effective model application. To address this gap, we present ORCA, a multi-modal benchmark for marine research comprising 14,647 images from 478 species, with 42,217 bounding box annotations and 22,321 expert-verified instance captions. The dataset provides fine-grained visual and textual annotations that capture morphology-oriented attributes across diverse marine species. To catalyze methodological advances, we evaluate 18 state-of-the-art models on three tasks: object detection (closed-set and open-vocabulary), instance captioning, and visual grounding. Results highlight key challenges, including species diversity, morphological overlap, and specialized domain demands, underscoring the difficulty of marine understanding. ORCA thus establishes a comprehensive benchmark to advance research in marine domain. Project Page: http://orca.hkustvgd.com/.
All-in-One Image Compression and Restoration
Feb 05, 2025



Visual images corrupted by various types and levels of degradations are commonly encountered in practical image compression. However, most existing image compression methods are tailored for clean images, therefore struggling to achieve satisfying results on these images. Joint compression and restoration methods typically focus on a single type of degradation and fail to address a variety of degradations in practice. To this end, we propose a unified framework for all-in-one image compression and restoration, which incorporates the image restoration capability against various degradations into the process of image compression. The key challenges involve distinguishing authentic image content from degradations, and flexibly eliminating various degradations without prior knowledge. Specifically, the proposed framework approaches these challenges from two perspectives: i.e., content information aggregation, and degradation representation aggregation. Extensive experiments demonstrate the following merits of our model: 1) superior rate-distortion (RD) performance on various degraded inputs while preserving the performance on clean data; 2) strong generalization ability to real-world and unseen scenarios; 3) higher computing efficiency over compared methods. Our code is available at https://github.com/ZeldaM1/All-in-one.
CoralSCOP-LAT: Labeling and Analyzing Tool for Coral Reef Images with Dense Mask
Oct 27, 2024
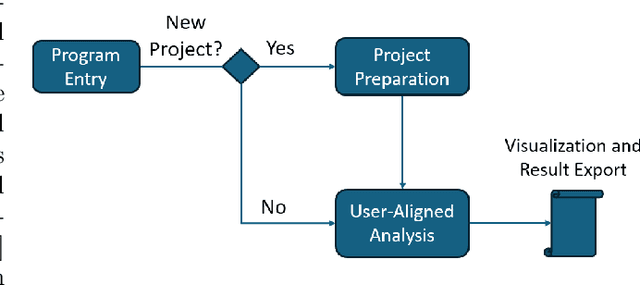
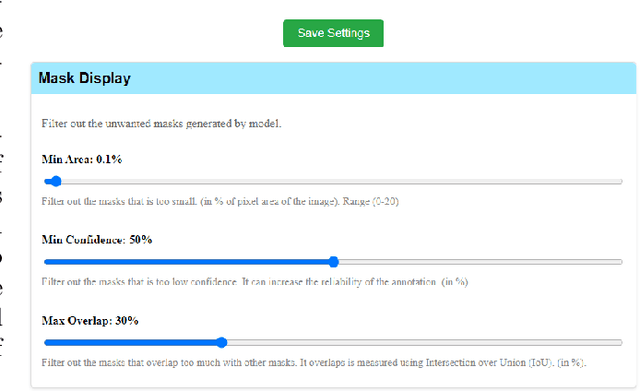
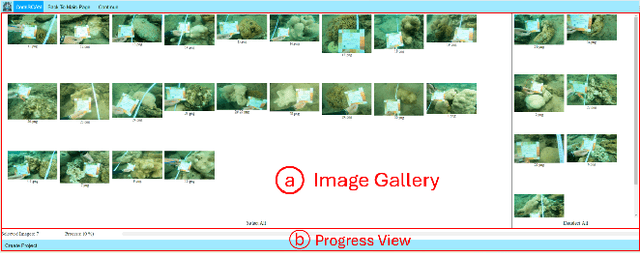
Images of coral reefs provide invaluable information, which is essentially critical for surveying and monitoring the coral reef ecosystems. Robust and precise identification of coral reef regions within surveying imagery is paramount for assessing coral coverage, spatial distribution, and other statistical analyses. However, existing coral reef analytical approaches mainly focus on sparse points sampled from the whole imagery, which are highly subject to the sampling density and cannot accurately express the coral ambulance. Meanwhile, the analysis is both time-consuming and labor-intensive, and it is also limited to coral biologists. In this work, we propose CoralSCOP-LAT, an automatic and semi-automatic coral reef labeling and analysis tool, specially designed to segment coral reef regions (dense pixel masks) in coral reef images, significantly promoting analysis proficiency and accuracy. CoralSCOP-LAT leverages the advanced coral reef foundation model to accurately delineate coral regions, supporting dense coral reef analysis and reducing the dependency on manual annotation. The proposed CoralSCOP-LAT surpasses the existing tools by a large margin from analysis efficiency, accuracy, and flexibility. We perform comprehensive evaluations from various perspectives and the comparison demonstrates that CoralSCOP-LAT not only accelerates the coral reef analysis but also improves accuracy in coral segmentation and analysis. Our CoralSCOP-LAT, as the first dense coral reef analysis tool in the market, facilitates repeated large-scale coral reef monitoring analysis, contributing to more informed conservation efforts and sustainable management of coral reef ecosystems. Our tool will be available at https://coralscop.hkustvgd.com/.
Bridge-Coder: Unlocking LLMs' Potential to Overcome Language Gaps in Low-Resource Code
Oct 24, 2024
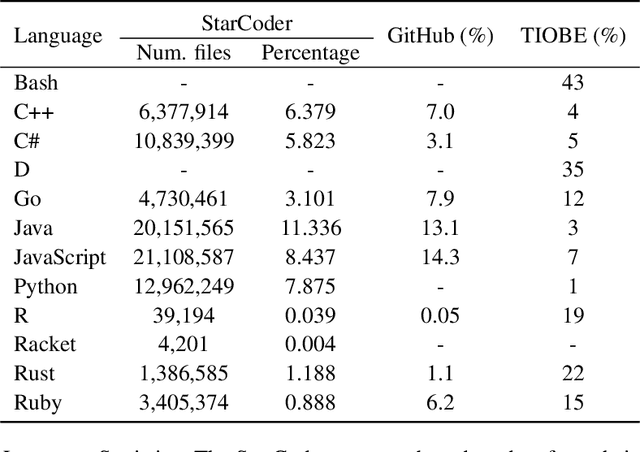

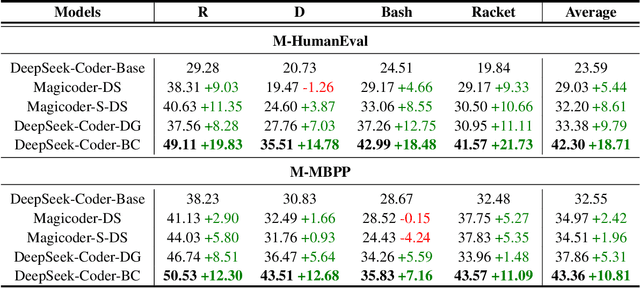
Large Language Models (LLMs) demonstrate strong proficiency in generating code for high-resource programming languages (HRPLs) like Python but struggle significantly with low-resource programming languages (LRPLs) such as Racket or D. This performance gap deepens the digital divide, preventing developers using LRPLs from benefiting equally from LLM advancements and reinforcing disparities in innovation within underrepresented programming communities. While generating additional training data for LRPLs is promising, it faces two key challenges: manual annotation is labor-intensive and costly, and LLM-generated LRPL code is often of subpar quality. The underlying cause of this issue is the gap between natural language to programming language gap (NL-PL Gap), which is especially pronounced in LRPLs due to limited aligned data. In this work, we introduce a novel approach called Bridge-Coder, which leverages LLMs' intrinsic capabilities to enhance the performance on LRPLs. Our method consists of two key stages. Bridge Generation, where we create high-quality dataset by utilizing LLMs' general knowledge understanding, proficiency in HRPLs, and in-context learning abilities. Then, we apply the Bridged Alignment, which progressively improves the alignment between NL instructions and LRPLs. Experimental results across multiple LRPLs show that Bridge-Coder significantly enhances model performance, demonstrating the effectiveness and generalization of our approach. Furthermore, we offer a detailed analysis of the key components of our method, providing valuable insights for future work aimed at addressing the challenges associated with LRPLs.
UVEB: A Large-scale Benchmark and Baseline Towards Real-World Underwater Video Enhancement
Apr 27, 2024

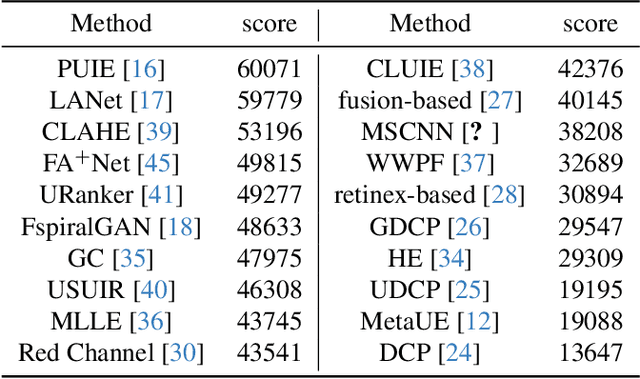

Learning-based underwater image enhancement (UIE) methods have made great progress. However, the lack of large-scale and high-quality paired training samples has become the main bottleneck hindering the development of UIE. The inter-frame information in underwater videos can accelerate or optimize the UIE process. Thus, we constructed the first large-scale high-resolution underwater video enhancement benchmark (UVEB) to promote the development of underwater vision.It contains 1,308 pairs of video sequences and more than 453,000 high-resolution with 38\% Ultra-High-Definition (UHD) 4K frame pairs. UVEB comes from multiple countries, containing various scenes and video degradation types to adapt to diverse and complex underwater environments. We also propose the first supervised underwater video enhancement method, UVE-Net. UVE-Net converts the current frame information into convolutional kernels and passes them to adjacent frames for efficient inter-frame information exchange. By fully utilizing the redundant degraded information of underwater videos, UVE-Net completes video enhancement better. Experiments show the effective network design and good performance of UVE-Net.
Exploring Boundary of GPT-4V on Marine Analysis: A Preliminary Case Study
Jan 04, 2024Large language models (LLMs) have demonstrated a powerful ability to answer various queries as a general-purpose assistant. The continuous multi-modal large language models (MLLM) empower LLMs with the ability to perceive visual signals. The launch of GPT-4 (Generative Pre-trained Transformers) has generated significant interest in the research communities. GPT-4V(ison) has demonstrated significant power in both academia and industry fields, as a focal point in a new artificial intelligence generation. Though significant success was achieved by GPT-4V, exploring MLLMs in domain-specific analysis (e.g., marine analysis) that required domain-specific knowledge and expertise has gained less attention. In this study, we carry out the preliminary and comprehensive case study of utilizing GPT-4V for marine analysis. This report conducts a systematic evaluation of existing GPT-4V, assessing the performance of GPT-4V on marine research and also setting a new standard for future developments in MLLMs. The experimental results of GPT-4V show that the responses generated by GPT-4V are still far away from satisfying the domain-specific requirements of the marine professions. All images and prompts used in this study will be available at https://github.com/hkust-vgd/Marine_GPT-4V_Eval
MarineGPT: Unlocking Secrets of Ocean to the Public
Oct 20, 2023
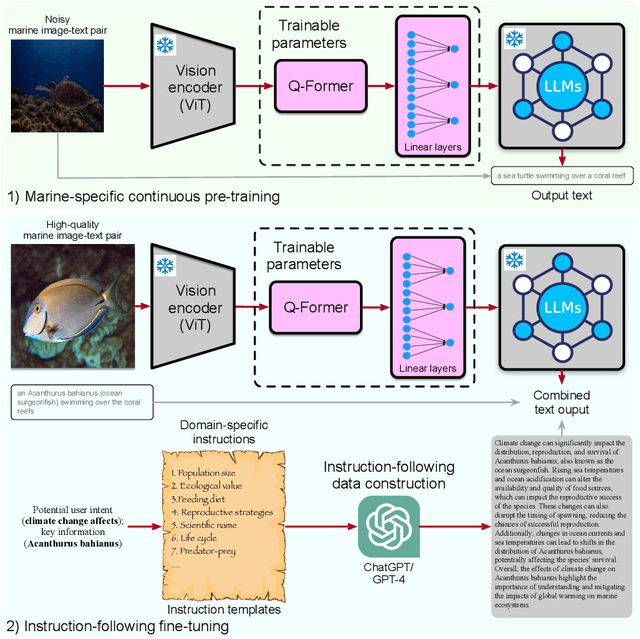

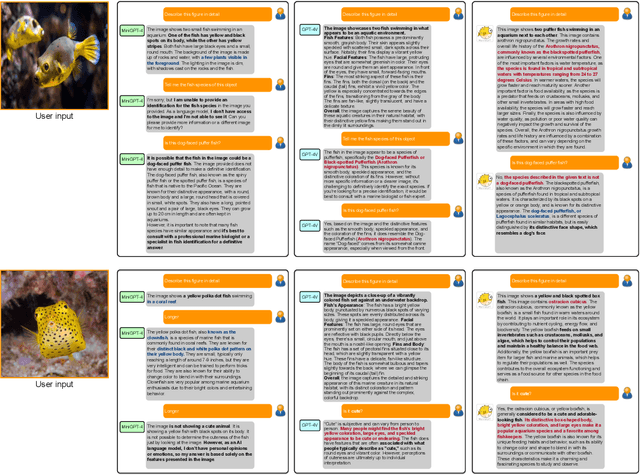
Large language models (LLMs), such as ChatGPT/GPT-4, have proven to be powerful tools in promoting the user experience as an AI assistant. The continuous works are proposing multi-modal large language models (MLLM), empowering LLMs with the ability to sense multiple modality inputs through constructing a joint semantic space (e.g. visual-text space). Though significant success was achieved in LLMs and MLLMs, exploring LLMs and MLLMs in domain-specific applications that required domain-specific knowledge and expertise has been less conducted, especially for \textbf{marine domain}. Different from general-purpose MLLMs, the marine-specific MLLM is required to yield much more \textbf{sensitive}, \textbf{informative}, and \textbf{scientific} responses. In this work, we demonstrate that the existing MLLMs optimized on huge amounts of readily available general-purpose training data show a minimal ability to understand domain-specific intents and then generate informative and satisfactory responses. To address these issues, we propose \textbf{MarineGPT}, the first vision-language model specially designed for the marine domain, unlocking the secrets of the ocean to the public. We present our \textbf{Marine-5M} dataset with more than 5 million marine image-text pairs to inject domain-specific marine knowledge into our model and achieve better marine vision and language alignment. Our MarineGPT not only pushes the boundaries of marine understanding to the general public but also offers a standard protocol for adapting a general-purpose assistant to downstream domain-specific experts. We pave the way for a wide range of marine applications while setting valuable data and pre-trained models for future research in both academic and industrial communities.
ACNet: Approaching-and-Centralizing Network for Zero-Shot Sketch-Based Image Retrieval
Nov 24, 2021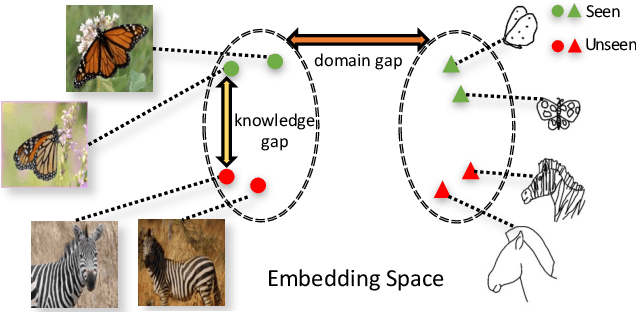
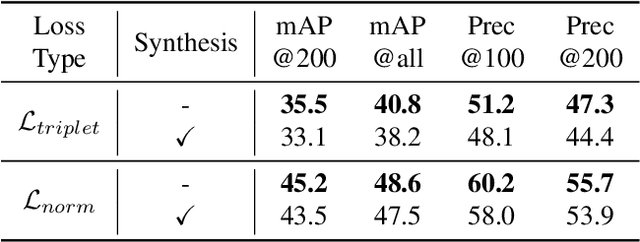
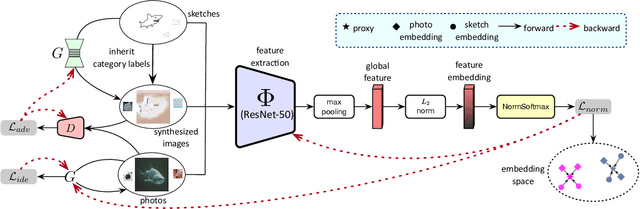
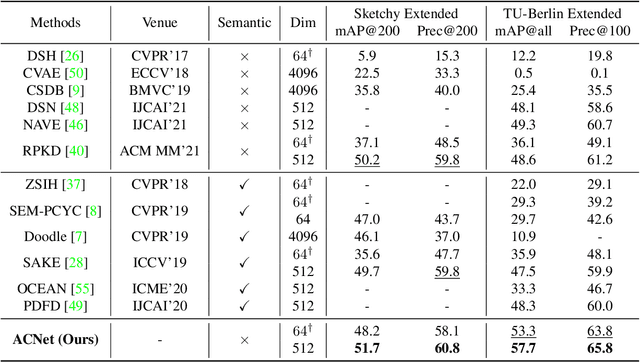
The huge domain gap between sketches and photos and the highly abstract sketch representations pose challenges for sketch-based image retrieval (\underline{SBIR}). The zero-shot sketch-based image retrieval (\underline{ZS-SBIR}) is more generic and practical but poses an even greater challenge because of the additional knowledge gap between the seen and unseen categories. To simultaneously mitigate both gaps, we propose an \textbf{A}pproaching-and-\textbf{C}entralizing \textbf{Net}work (termed ``\textbf{ACNet}'') to jointly optimize sketch-to-photo synthesis and the image retrieval. The retrieval module guides the synthesis module to generate large amounts of diverse photo-like images which gradually approach the photo domain, and thus better serve the retrieval module than ever to learn domain-agnostic representations and category-agnostic common knowledge for generalizing to unseen categories. These diverse images generated with retrieval guidance can effectively alleviate the overfitting problem troubling concrete category-specific training samples with high gradients. We also discover the use of proxy-based NormSoftmax loss is effective in the zero-shot setting because its centralizing effect can stabilize our joint training and promote the generalization ability to unseen categories. Our approach is simple yet effective, which achieves state-of-the-art performance on two widely used ZS-SBIR datasets and surpasses previous methods by a large margin.