 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransformer-based CoVaR: Systemic Risk in Textual Information
Feb 13, 2026Conditional Value-at-Risk (CoVaR) quantifies systemic financial risk by measuring the loss quantile of one asset, conditional on another asset experiencing distress. We develop a Transformer-based methodology that integrates financial news articles directly with market data to improve CoVaR estimates. Unlike approaches that use predefined sentiment scores, our method incorporates raw text embeddings generated by a large language model (LLM). We prove explicit error bounds for our Transformer CoVaR estimator, showing that accurate CoVaR learning is possible even with small datasets. Using U.S. market returns and Reuters news items from 2006--2013, our out-of-sample results show that textual information impacts the CoVaR forecasts. With better predictive performance, we identify a pronounced negative dip during market stress periods across several equity assets when comparing the Transformer-based CoVaR to both the CoVaR without text and the CoVaR using traditional sentiment measures. Our results show that textual data can be used to effectively model systemic risk without requiring prohibitively large data sets.
UVEB: A Large-scale Benchmark and Baseline Towards Real-World Underwater Video Enhancement
Apr 27, 2024

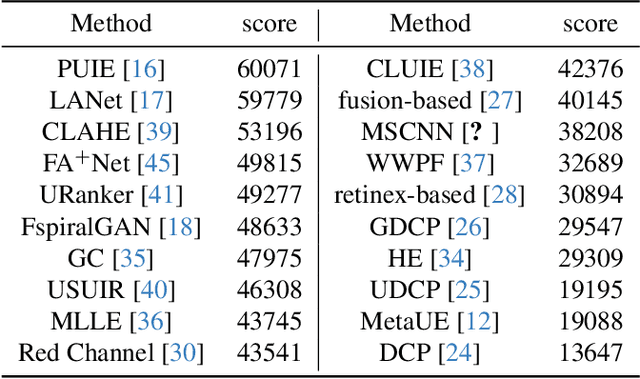

Learning-based underwater image enhancement (UIE) methods have made great progress. However, the lack of large-scale and high-quality paired training samples has become the main bottleneck hindering the development of UIE. The inter-frame information in underwater videos can accelerate or optimize the UIE process. Thus, we constructed the first large-scale high-resolution underwater video enhancement benchmark (UVEB) to promote the development of underwater vision.It contains 1,308 pairs of video sequences and more than 453,000 high-resolution with 38\% Ultra-High-Definition (UHD) 4K frame pairs. UVEB comes from multiple countries, containing various scenes and video degradation types to adapt to diverse and complex underwater environments. We also propose the first supervised underwater video enhancement method, UVE-Net. UVE-Net converts the current frame information into convolutional kernels and passes them to adjacent frames for efficient inter-frame information exchange. By fully utilizing the redundant degraded information of underwater videos, UVE-Net completes video enhancement better. Experiments show the effective network design and good performance of UVE-Net.
Personalized Federated Learning via Gradient Modulation for Heterogeneous Text Summarization
Apr 23, 2023Text summarization is essential for information aggregation and demands large amounts of training data. However, concerns about data privacy and security limit data collection and model training. To eliminate this concern, we propose a federated learning text summarization scheme, which allows users to share the global model in a cooperative learning manner without sharing raw data. Personalized federated learning (PFL) balances personalization and generalization in the process of optimizing the global model, to guide the training of local models. However, multiple local data have different distributions of semantics and context, which may cause the local model to learn deviated semantic and context information. In this paper, we propose FedSUMM, a dynamic gradient adapter to provide more appropriate local parameters for local model. Simultaneously, FedSUMM uses differential privacy to prevent parameter leakage during distributed training. Experimental evidence verifies FedSUMM can achieve faster model convergence on PFL algorithm for task-specific text summarization, and the method achieves superior performance for different optimization metrics for text summarization.
Blur the Linguistic Boundary: Interpreting Chinese Buddhist Sutra in English via Neural Machine Translation
Sep 30, 2022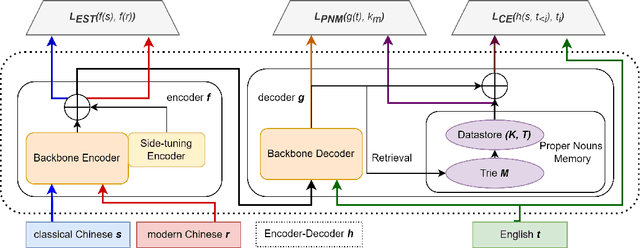
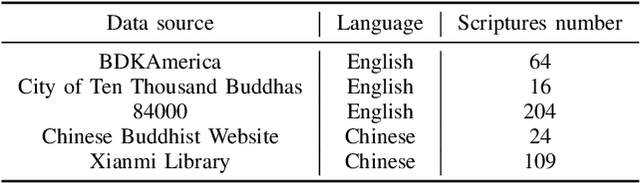

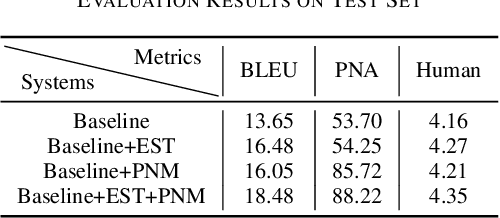
Buddhism is an influential religion with a long-standing history and profound philosophy. Nowadays, more and more people worldwide aspire to learn the essence of Buddhism, attaching importance to Buddhism dissemination. However, Buddhist scriptures written in classical Chinese are obscure to most people and machine translation applications. For instance, general Chinese-English neural machine translation (NMT) fails in this domain. In this paper, we proposed a novel approach to building a practical NMT model for Buddhist scriptures. The performance of our translation pipeline acquired highly promising results in ablation experiments under three criteria.
GraphPB: Graphical Representations of Prosody Boundary in Speech Synthesis
Dec 03, 2020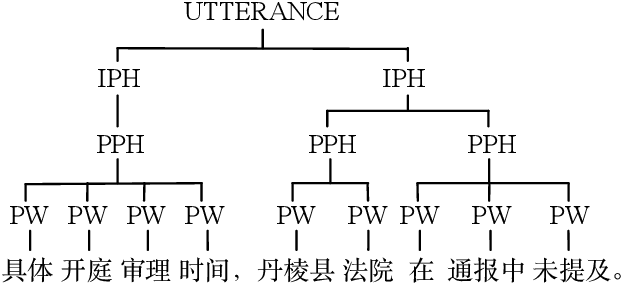

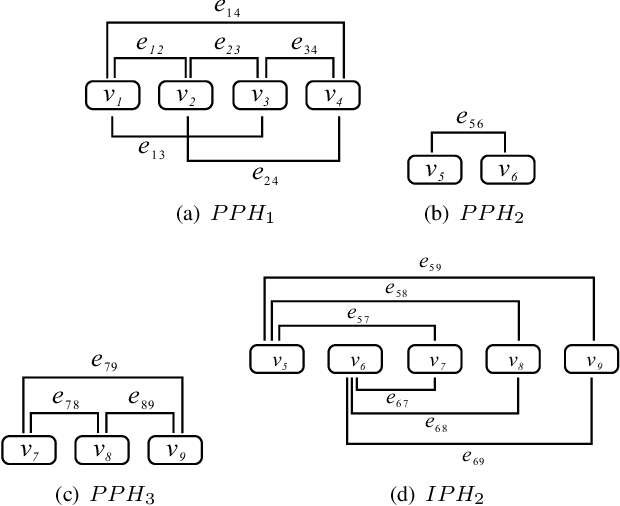

This paper introduces a graphical representation approach of prosody boundary (GraphPB) in the task of Chinese speech synthesis, intending to parse the semantic and syntactic relationship of input sequences in a graphical domain for improving the prosody performance. The nodes of the graph embedding are formed by prosodic words, and the edges are formed by the other prosodic boundaries, namely prosodic phrase boundary (PPH) and intonation phrase boundary (IPH). Different Graph Neural Networks (GNN) like Gated Graph Neural Network (GGNN) and Graph Long Short-term Memory (G-LSTM) are utilised as graph encoders to exploit the graphical prosody boundary information. Graph-to-sequence model is proposed and formed by a graph encoder and an attentional decoder. Two techniques are proposed to embed sequential information into the graph-to-sequence text-to-speech model. The experimental results show that this proposed approach can encode the phonetic and prosody rhythm of an utterance. The mean opinion score (MOS) of these GNN models shows comparative results with the state-of-the-art sequence-to-sequence models with better performance in the aspect of prosody. This provides an alternative approach for prosody modelling in end-to-end speech synthesis.