 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Knowing to Doing Precisely: A General Self-Correction and Termination Framework for VLA models
Feb 02, 2026While vision-language-action (VLA) models for embodied agents integrate perception, reasoning, and control, they remain constrained by two critical weaknesses: first, during grasping tasks, the action tokens generated by the language model often exhibit subtle spatial deviations from the target object, resulting in grasp failures; second, they lack the ability to reliably recognize task completion, which leads to redundant actions and frequent timeout errors. To address these challenges and enhance robustness, we propose a lightweight, training-free framework, VLA-SCT. This framework operates as a self-correcting control loop, combining data-driven action refinement with conditional logic for termination. Consequently, compared to baseline approaches, our method achieves consistent improvements across all datasets in the LIBERO benchmark, significantly increasing the success rate of fine manipulation tasks and ensuring accurate task completion, thereby promoting the deployment of more reliable VLA agents in complex, unstructured environments.
FastGraphTTS: An Ultrafast Syntax-Aware Speech Synthesis Framework
Sep 16, 2023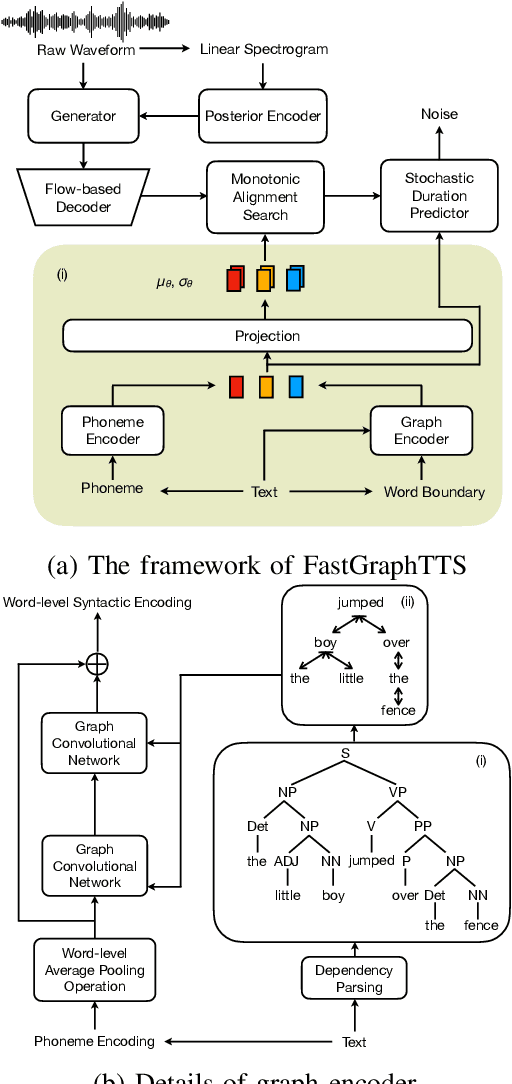

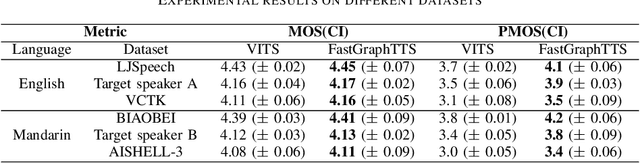
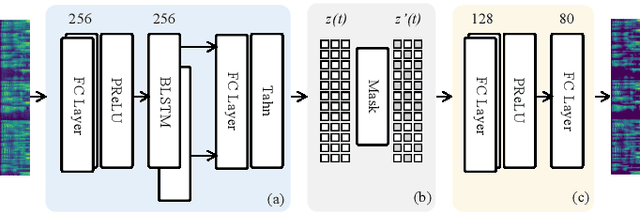
This paper integrates graph-to-sequence into an end-to-end text-to-speech framework for syntax-aware modelling with syntactic information of input text. Specifically, the input text is parsed by a dependency parsing module to form a syntactic graph. The syntactic graph is then encoded by a graph encoder to extract the syntactic hidden information, which is concatenated with phoneme embedding and input to the alignment and flow-based decoding modules to generate the raw audio waveform. The model is experimented on two languages, English and Mandarin, using single-speaker, few samples of target speakers, and multi-speaker datasets, respectively. Experimental results show better prosodic consistency performance between input text and generated audio, and also get higher scores in the subjective prosodic evaluation, and show the ability of voice conversion. Besides, the efficiency of the model is largely boosted through the design of the AI chip operator with 5x acceleration.
SAR: Self-Supervised Anti-Distortion Representation for End-To-End Speech Model
Apr 23, 2023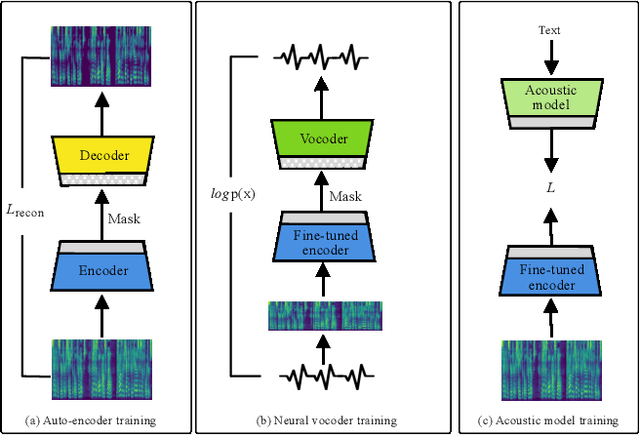
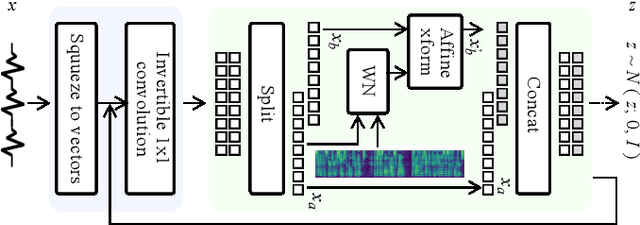
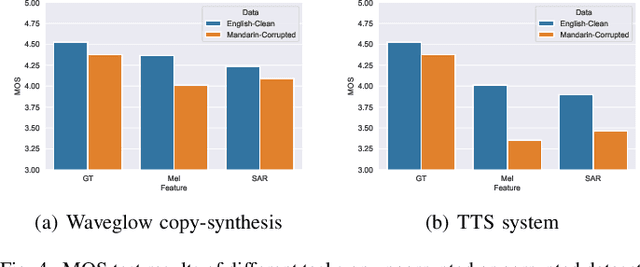
In recent Text-to-Speech (TTS) systems, a neural vocoder often generates speech samples by solely conditioning on acoustic features predicted from an acoustic model. However, there are always distortions existing in the predicted acoustic features, compared to those of the groundtruth, especially in the common case of poor acoustic modeling due to low-quality training data. To overcome such limits, we propose a Self-supervised learning framework to learn an Anti-distortion acoustic Representation (SAR) to replace human-crafted acoustic features by introducing distortion prior to an auto-encoder pre-training process. The learned acoustic representation from the proposed framework is proved anti-distortion compared to the most commonly used mel-spectrogram through both objective and subjective evaluation.
Pre-Avatar: An Automatic Presentation Generation Framework Leveraging Talking Avatar
Oct 13, 2022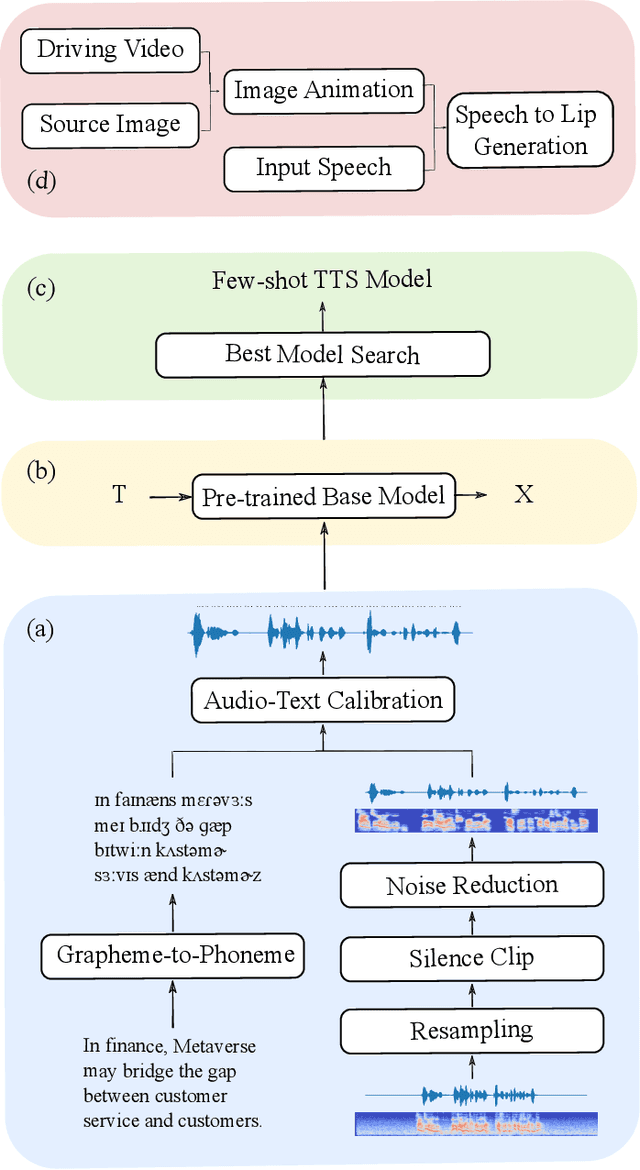
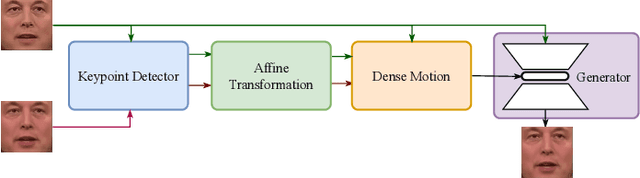

Since the beginning of the COVID-19 pandemic, remote conferencing and school-teaching have become important tools. The previous applications aim to save the commuting cost with real-time interactions. However, our application is going to lower the production and reproduction costs when preparing the communication materials. This paper proposes a system called Pre-Avatar, generating a presentation video with a talking face of a target speaker with 1 front-face photo and a 3-minute voice recording. Technically, the system consists of three main modules, user experience interface (UEI), talking face module and few-shot text-to-speech (TTS) module. The system firstly clones the target speaker's voice, and then generates the speech, and finally generate an avatar with appropriate lip and head movements. Under any scenario, users only need to replace slides with different notes to generate another new video. The demo has been released here and will be published as free software for use.
Speech Representation Disentanglement with Adversarial Mutual Information Learning for One-shot Voice Conversion
Aug 18, 2022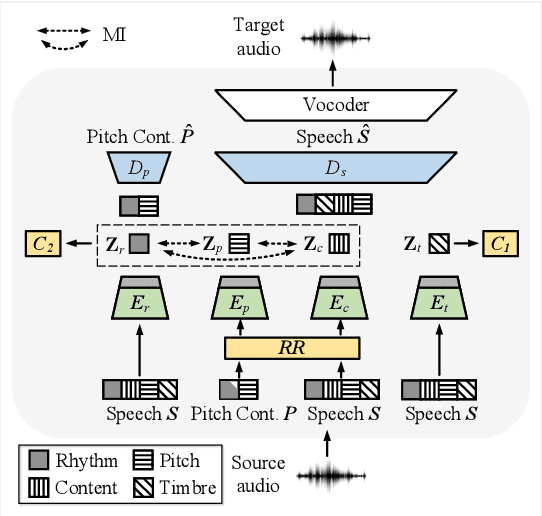

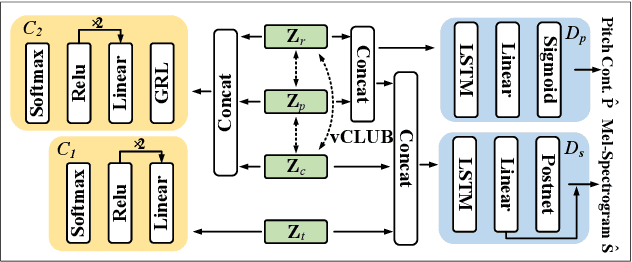
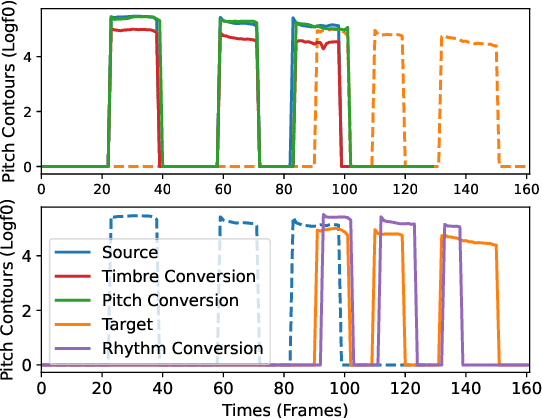
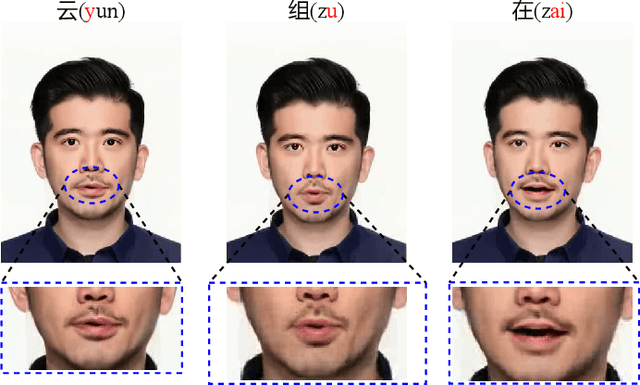
One-shot voice conversion (VC) with only a single target speaker's speech for reference has become a hot research topic. Existing works generally disentangle timbre, while information about pitch, rhythm and content is still mixed together. To perform one-shot VC effectively with further disentangling these speech components, we employ random resampling for pitch and content encoder and use the variational contrastive log-ratio upper bound of mutual information and gradient reversal layer based adversarial mutual information learning to ensure the different parts of the latent space containing only the desired disentangled representation during training. Experiments on the VCTK dataset show the model achieves state-of-the-art performance for one-shot VC in terms of naturalness and intellgibility. In addition, we can transfer characteristics of one-shot VC on timbre, pitch and rhythm separately by speech representation disentanglement. Our code, pre-trained models and demo are available at https://im1eon.github.io/IS2022-SRDVC/.
GraphPB: Graphical Representations of Prosody Boundary in Speech Synthesis
Dec 03, 2020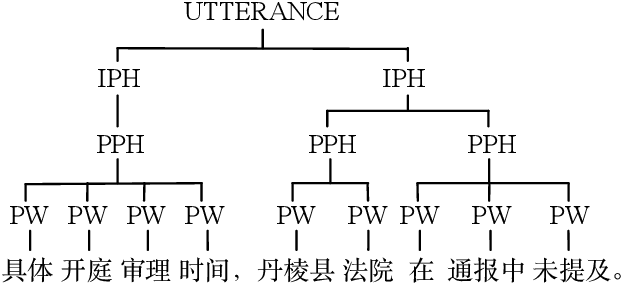

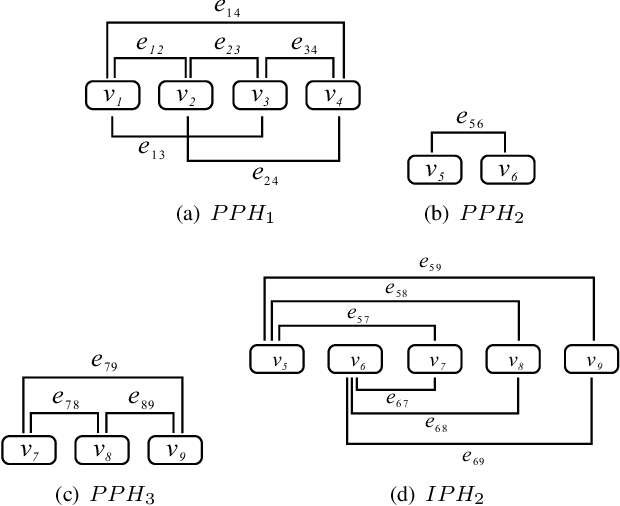

This paper introduces a graphical representation approach of prosody boundary (GraphPB) in the task of Chinese speech synthesis, intending to parse the semantic and syntactic relationship of input sequences in a graphical domain for improving the prosody performance. The nodes of the graph embedding are formed by prosodic words, and the edges are formed by the other prosodic boundaries, namely prosodic phrase boundary (PPH) and intonation phrase boundary (IPH). Different Graph Neural Networks (GNN) like Gated Graph Neural Network (GGNN) and Graph Long Short-term Memory (G-LSTM) are utilised as graph encoders to exploit the graphical prosody boundary information. Graph-to-sequence model is proposed and formed by a graph encoder and an attentional decoder. Two techniques are proposed to embed sequential information into the graph-to-sequence text-to-speech model. The experimental results show that this proposed approach can encode the phonetic and prosody rhythm of an utterance. The mean opinion score (MOS) of these GNN models shows comparative results with the state-of-the-art sequence-to-sequence models with better performance in the aspect of prosody. This provides an alternative approach for prosody modelling in end-to-end speech synthesis.
GraphTTS: graph-to-sequence modelling in neural text-to-speech
Mar 04, 2020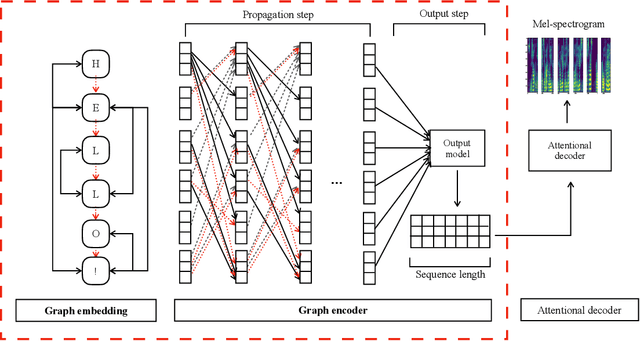

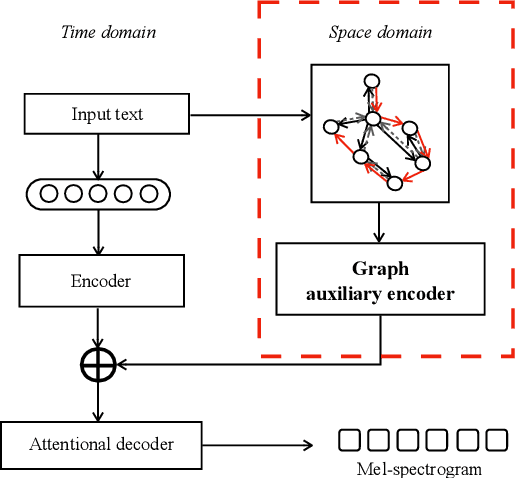
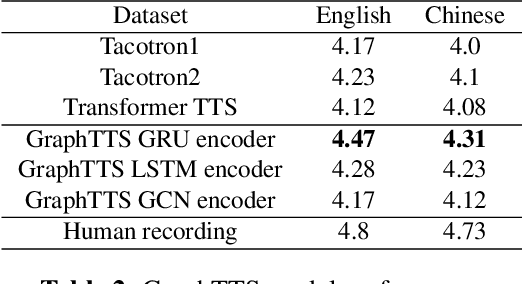
This paper leverages the graph-to-sequence method in neural text-to-speech (GraphTTS), which maps the graph embedding of the input sequence to spectrograms. The graphical inputs consist of node and edge representations constructed from input texts. The encoding of these graphical inputs incorporates syntax information by a GNN encoder module. Besides, applying the encoder of GraphTTS as a graph auxiliary encoder (GAE) can analyse prosody information from the semantic structure of texts. This can remove the manual selection of reference audios process and makes prosody modelling an end-to-end procedure. Experimental analysis shows that GraphTTS outperforms the state-of-the-art sequence-to-sequence models by 0.24 in Mean Opinion Score (MOS). GAE can adjust the pause, ventilation and tones of synthesised audios automatically. This experimental conclusion may give some inspiration to researchers working on improving speech synthesis prosody.