 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Disentangled Speech Representations with Contrastive Learning and Time-Invariant Retrieval
Jan 18, 2024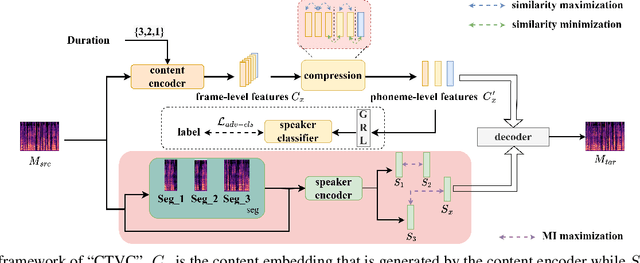
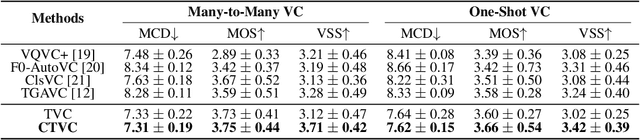
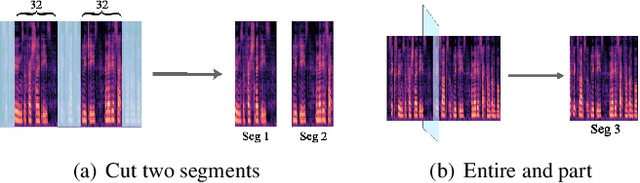

Voice conversion refers to transferring speaker identity with well-preserved content. Better disentanglement of speech representations leads to better voice conversion. Recent studies have found that phonetic information from input audio has the potential ability to well represent content. Besides, the speaker-style modeling with pre-trained models making the process more complex. To tackle these issues, we introduce a new method named "CTVC" which utilizes disentangled speech representations with contrastive learning and time-invariant retrieval. Specifically, a similarity-based compression module is used to facilitate a more intimate connection between the frame-level hidden features and linguistic information at phoneme-level. Additionally, a time-invariant retrieval is proposed for timbre extraction based on multiple segmentations and mutual information. Experimental results demonstrate that "CTVC" outperforms previous studies and improves the sound quality and similarity of converted results.
PMVC: Data Augmentation-Based Prosody Modeling for Expressive Voice Conversion
Aug 21, 2023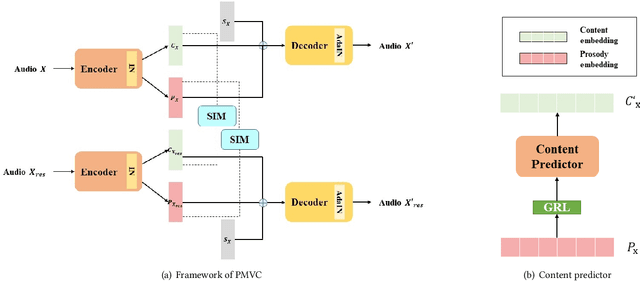



Voice conversion as the style transfer task applied to speech, refers to converting one person's speech into a new speech that sounds like another person's. Up to now, there has been a lot of research devoted to better implementation of VC tasks. However, a good voice conversion model should not only match the timbre information of the target speaker, but also expressive information such as prosody, pace, pause, etc. In this context, prosody modeling is crucial for achieving expressive voice conversion that sounds natural and convincing. Unfortunately, prosody modeling is important but challenging, especially without text transcriptions. In this paper, we firstly propose a novel voice conversion framework named 'PMVC', which effectively separates and models the content, timbre, and prosodic information from the speech without text transcriptions. Specially, we introduce a new speech augmentation algorithm for robust prosody extraction. And building upon this, mask and predict mechanism is applied in the disentanglement of prosody and content information. The experimental results on the AIShell-3 corpus supports our improvement of naturalness and similarity of converted speech.
Speech Representation Disentanglement with Adversarial Mutual Information Learning for One-shot Voice Conversion
Aug 18, 2022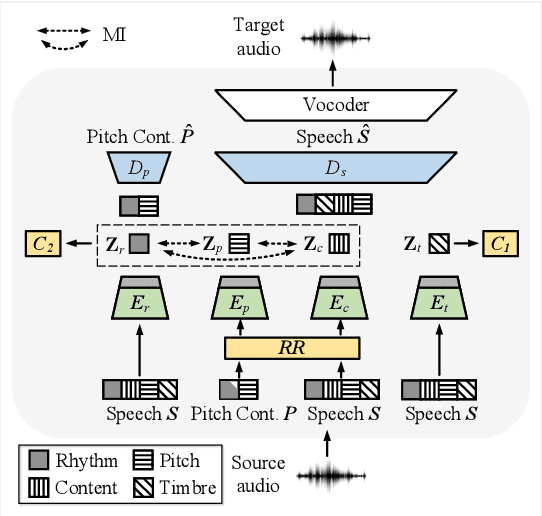

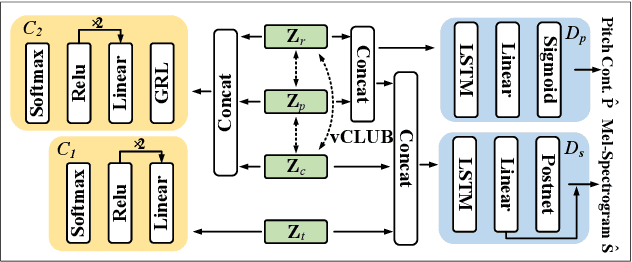
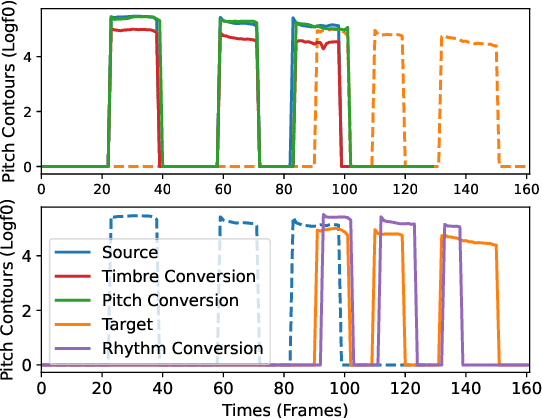
One-shot voice conversion (VC) with only a single target speaker's speech for reference has become a hot research topic. Existing works generally disentangle timbre, while information about pitch, rhythm and content is still mixed together. To perform one-shot VC effectively with further disentangling these speech components, we employ random resampling for pitch and content encoder and use the variational contrastive log-ratio upper bound of mutual information and gradient reversal layer based adversarial mutual information learning to ensure the different parts of the latent space containing only the desired disentangled representation during training. Experiments on the VCTK dataset show the model achieves state-of-the-art performance for one-shot VC in terms of naturalness and intellgibility. In addition, we can transfer characteristics of one-shot VC on timbre, pitch and rhythm separately by speech representation disentanglement. Our code, pre-trained models and demo are available at https://im1eon.github.io/IS2022-SRDVC/.
TGAVC: Improving Autoencoder Voice Conversion with Text-Guided and Adversarial Training
Aug 08, 2022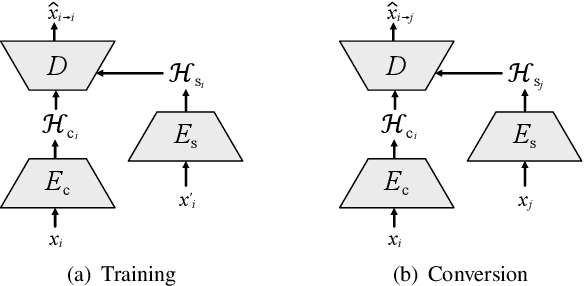
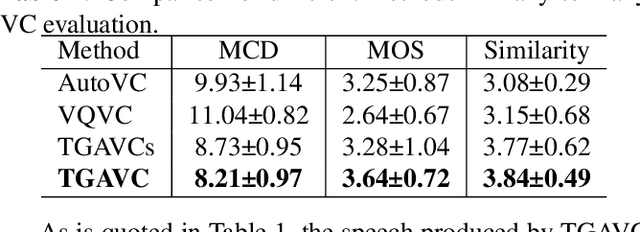
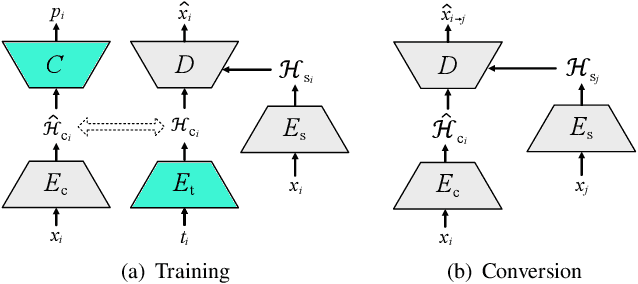
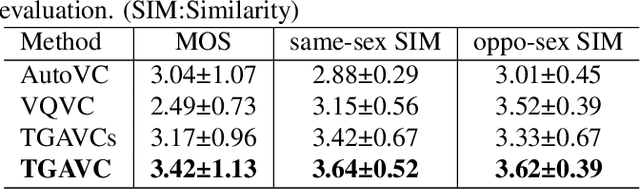
Non-parallel many-to-many voice conversion remains an interesting but challenging speech processing task. Recently, AutoVC, a conditional autoencoder based method, achieved excellent conversion results by disentangling the speaker identity and the speech content using information-constraining bottlenecks. However, due to the pure autoencoder training method, it is difficult to evaluate the separation effect of content and speaker identity. In this paper, a novel voice conversion framework, named $\boldsymbol T$ext $\boldsymbol G$uided $\boldsymbol A$utoVC(TGAVC), is proposed to more effectively separate content and timbre from speech, where an expected content embedding produced based on the text transcriptions is designed to guide the extraction of voice content. In addition, the adversarial training is applied to eliminate the speaker identity information in the estimated content embedding extracted from speech. Under the guidance of the expected content embedding and the adversarial training, the content encoder is trained to extract speaker-independent content embedding from speech. Experiments on AIShell-3 dataset show that the proposed model outperforms AutoVC in terms of naturalness and similarity of converted speech.
* ASRU 6 pages
AVQVC: One-shot Voice Conversion by Vector Quantization with applying contrastive learning
Feb 21, 2022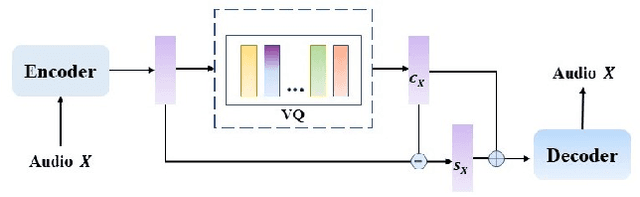

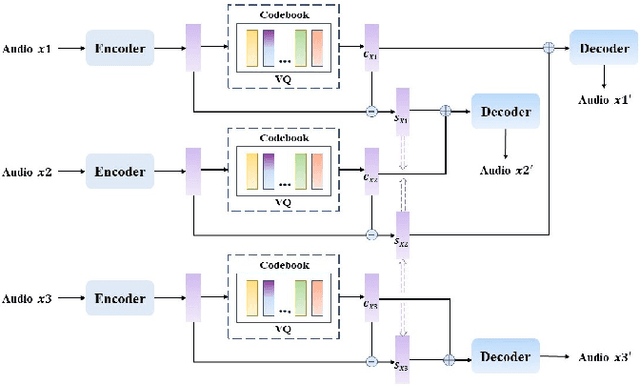
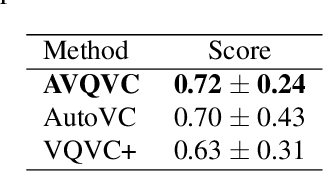
Voice Conversion(VC) refers to changing the timbre of a speech while retaining the discourse content. Recently, many works have focused on disentangle-based learning techniques to separate the timbre and the linguistic content information from a speech signal. Once successful, voice conversion will be feasible and straightforward. This paper proposed a novel one-shot voice conversion framework based on vector quantization voice conversion (VQVC) and AutoVC, called AVQVC. A new training method is applied to VQVC to separate content and timbre information from speech more effectively. The result shows that this approach has better performance than VQVC in separating content and timbre to improve the sound quality of generated speech.