 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTGAVC: Improving Autoencoder Voice Conversion with Text-Guided and Adversarial Training
Aug 08, 2022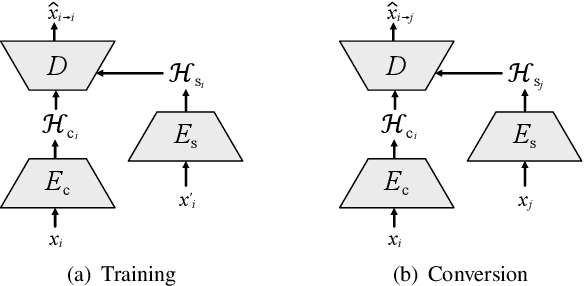
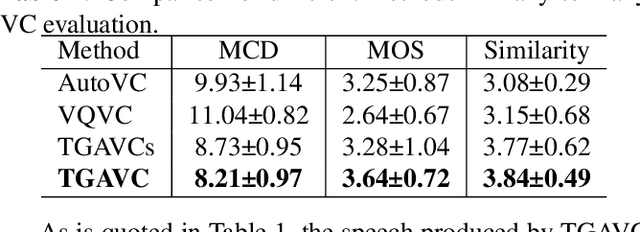
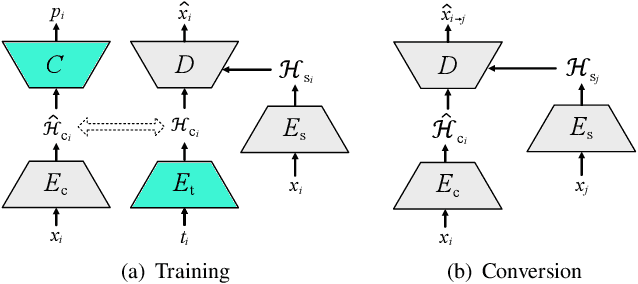
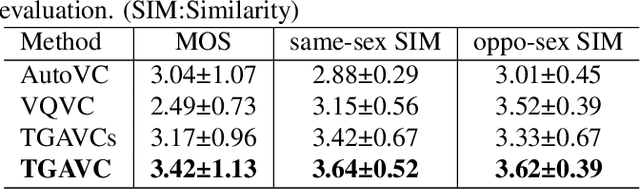
Non-parallel many-to-many voice conversion remains an interesting but challenging speech processing task. Recently, AutoVC, a conditional autoencoder based method, achieved excellent conversion results by disentangling the speaker identity and the speech content using information-constraining bottlenecks. However, due to the pure autoencoder training method, it is difficult to evaluate the separation effect of content and speaker identity. In this paper, a novel voice conversion framework, named $\boldsymbol T$ext $\boldsymbol G$uided $\boldsymbol A$utoVC(TGAVC), is proposed to more effectively separate content and timbre from speech, where an expected content embedding produced based on the text transcriptions is designed to guide the extraction of voice content. In addition, the adversarial training is applied to eliminate the speaker identity information in the estimated content embedding extracted from speech. Under the guidance of the expected content embedding and the adversarial training, the content encoder is trained to extract speaker-independent content embedding from speech. Experiments on AIShell-3 dataset show that the proposed model outperforms AutoVC in terms of naturalness and similarity of converted speech.
* ASRU 6 pages
Tiny-Sepformer: A Tiny Time-Domain Transformer Network for Speech Separation
Jun 30, 2022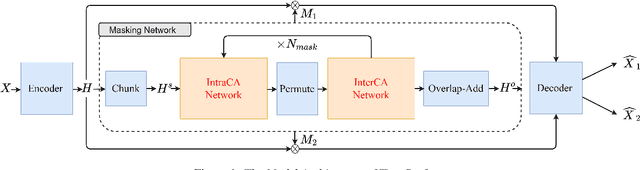

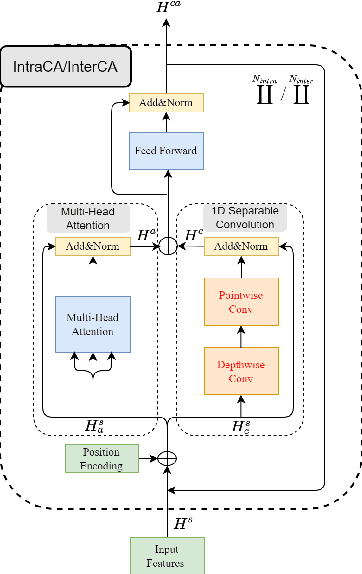
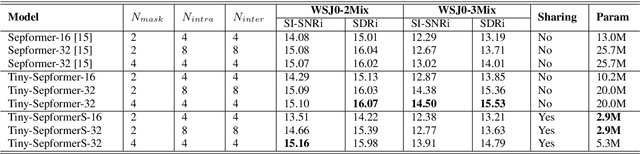
Time-domain Transformer neural networks have proven their superiority in speech separation tasks. However, these models usually have a large number of network parameters, thus often encountering the problem of GPU memory explosion. In this paper, we proposed Tiny-Sepformer, a tiny version of Transformer network for speech separation. We present two techniques to reduce the model parameters and memory consumption: (1) Convolution-Attention (CA) block, spliting the vanilla Transformer to two paths, multi-head attention and 1D depthwise separable convolution, (2) parameter sharing, sharing the layer parameters within the CA block. In our experiments, Tiny-Sepformer could greatly reduce the model size, and achieves comparable separation performance with vanilla Sepformer on WSJ0-2/3Mix datasets.