 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFew-Shot Distribution-Aligned Flow Matching for Data Synthesis in Medical Image Segmentation
Apr 03, 2026Data heterogeneity hinders clinical deployment of medical image analysis models, and generative data augmentation helps mitigate this issue. However, recent diffusion-based methods that synthesize image-mask pairs often ignore distribution shifts between generated and real images across scenarios, and such mismatches can markedly degrade downstream performance. To address this issue, we propose AlignFlow, a flow matching model that aligns with the target reference image distribution via differentiable reward fine-tuning, and remains effective even when only a small number of reference images are provided. Specifically, we divide the training of the flow matching model into two stages: in the first stage, the model fits the training data to generate plausible images; Then, we introduce a distribution alignment mechanism and employ differentiable reward to steer the generated images toward the distribution of the given samples from the target domain. In addition, to enhance the diversity of generated masks, we also design a flow matching based mask generation to complement the diversity in regions of interest. Extensive experiments demonstrate the effectiveness of our approach, i.e., performance improvement by 3.5-4.0% in mDice and 3.5-5.6% in mIoU across a variety of datasets and scenarios.
ReCreate: Reasoning and Creating Domain Agents Driven by Experience
Jan 16, 2026Large Language Model agents are reshaping the industrial landscape. However, most practical agents remain human-designed because tasks differ widely, making them labor-intensive to build. This situation poses a central question: can we automatically create and adapt domain agents in the wild? While several recent approaches have sought to automate agent creation, they typically treat agent generation as a black-box procedure and rely solely on final performance metrics to guide the process. Such strategies overlook critical evidence explaining why an agent succeeds or fails, and often require high computational costs. To address these limitations, we propose ReCreate, an experience-driven framework for the automatic creation of domain agents. ReCreate systematically leverages agent interaction histories, which provide rich concrete signals on both the causes of success or failure and the avenues for improvement. Specifically, we introduce an agent-as-optimizer paradigm that effectively learns from experience via three key components: (i) an experience storage and retrieval mechanism for on-demand inspection; (ii) a reasoning-creating synergy pipeline that maps execution experience into scaffold edits; and (iii) hierarchical updates that abstract instance-level details into reusable domain patterns. In experiments across diverse domains, ReCreate consistently outperforms human-designed agents and existing automated agent generation methods, even when starting from minimal seed scaffolds.
Accelerating PDE Data Generation via Differential Operator Action in Solution Space
Feb 04, 2024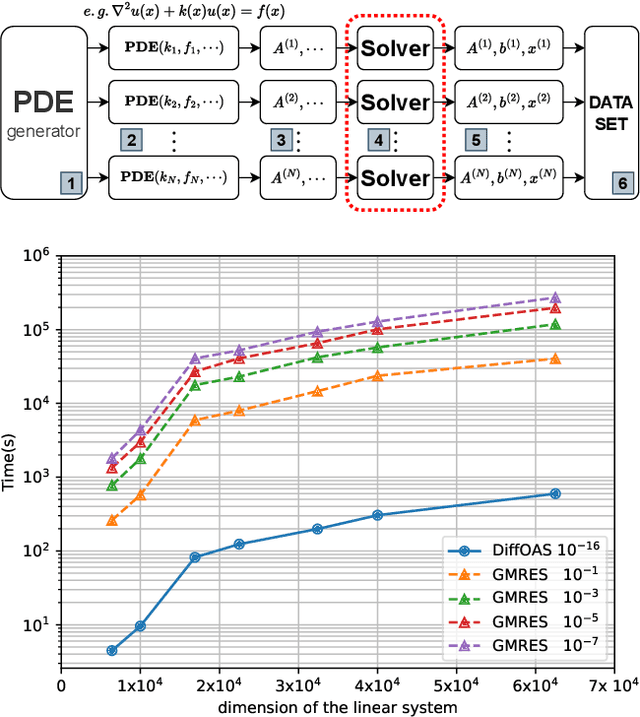



Recent advancements in data-driven approaches, such as Neural Operator (NO), have demonstrated their effectiveness in reducing the solving time of Partial Differential Equations (PDEs). However, one major challenge faced by these approaches is the requirement for a large amount of high-precision training data, which needs significant computational costs during the generation process. To address this challenge, we propose a novel PDE dataset generation algorithm, namely Differential Operator Action in Solution space (DiffOAS), which speeds up the data generation process and enhances the precision of the generated data simultaneously. Specifically, DiffOAS obtains a few basic PDE solutions and then combines them to get solutions. It applies differential operators on these solutions, a process we call 'operator action', to efficiently generate precise PDE data points. Theoretical analysis shows that the time complexity of DiffOAS method is one order lower than the existing generation method. Experimental results show that DiffOAS accelerates the generation of large-scale datasets with 10,000 instances by 300 times. Even with just 5% of the generation time, NO trained on the data generated by DiffOAS exhibits comparable performance to that using the existing generation method, which highlights the efficiency of DiffOAS.
BC4LLM: Trusted Artificial Intelligence When Blockchain Meets Large Language Models
Oct 10, 2023In recent years, artificial intelligence (AI) and machine learning (ML) are reshaping society's production methods and productivity, and also changing the paradigm of scientific research. Among them, the AI language model represented by ChatGPT has made great progress. Such large language models (LLMs) serve people in the form of AI-generated content (AIGC) and are widely used in consulting, healthcare, and education. However, it is difficult to guarantee the authenticity and reliability of AIGC learning data. In addition, there are also hidden dangers of privacy disclosure in distributed AI training. Moreover, the content generated by LLMs is difficult to identify and trace, and it is difficult to cross-platform mutual recognition. The above information security issues in the coming era of AI powered by LLMs will be infinitely amplified and affect everyone's life. Therefore, we consider empowering LLMs using blockchain technology with superior security features to propose a vision for trusted AI. This paper mainly introduces the motivation and technical route of blockchain for LLM (BC4LLM), including reliable learning corpus, secure training process, and identifiable generated content. Meanwhile, this paper also reviews the potential applications and future challenges, especially in the frontier communication networks field, including network resource allocation, dynamic spectrum sharing, and semantic communication. Based on the above work combined and the prospect of blockchain and LLMs, it is expected to help the early realization of trusted AI and provide guidance for the academic community.
Dynamic Alignment Mask CTC: Improved Mask-CTC with Aligned Cross Entropy
Mar 14, 2023



Because of predicting all the target tokens in parallel, the non-autoregressive models greatly improve the decoding efficiency of speech recognition compared with traditional autoregressive models. In this work, we present dynamic alignment Mask CTC, introducing two methods: (1) Aligned Cross Entropy (AXE), finding the monotonic alignment that minimizes the cross-entropy loss through dynamic programming, (2) Dynamic Rectification, creating new training samples by replacing some masks with model predicted tokens. The AXE ignores the absolute position alignment between prediction and ground truth sentence and focuses on tokens matching in relative order. The dynamic rectification method makes the model capable of simulating the non-mask but possible wrong tokens, even if they have high confidence. Our experiments on WSJ dataset demonstrated that not only AXE loss but also the rectification method could improve the WER performance of Mask CTC.
Tiny-Sepformer: A Tiny Time-Domain Transformer Network for Speech Separation
Jun 30, 2022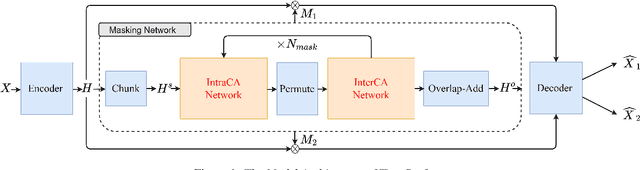

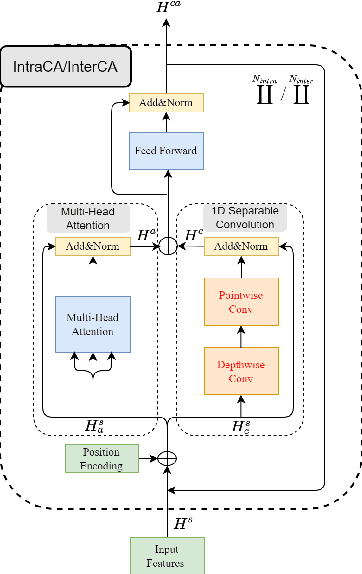
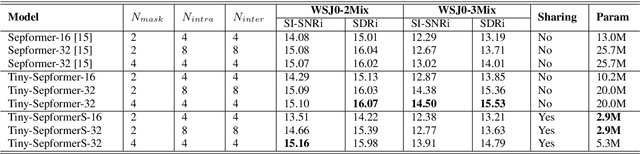
Time-domain Transformer neural networks have proven their superiority in speech separation tasks. However, these models usually have a large number of network parameters, thus often encountering the problem of GPU memory explosion. In this paper, we proposed Tiny-Sepformer, a tiny version of Transformer network for speech separation. We present two techniques to reduce the model parameters and memory consumption: (1) Convolution-Attention (CA) block, spliting the vanilla Transformer to two paths, multi-head attention and 1D depthwise separable convolution, (2) parameter sharing, sharing the layer parameters within the CA block. In our experiments, Tiny-Sepformer could greatly reduce the model size, and achieves comparable separation performance with vanilla Sepformer on WSJ0-2/3Mix datasets.
Speech Augmentation Based Unsupervised Learning for Keyword Spotting
May 28, 2022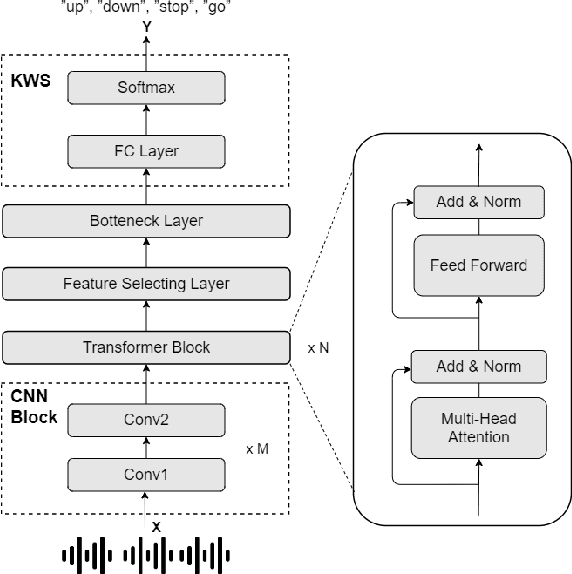
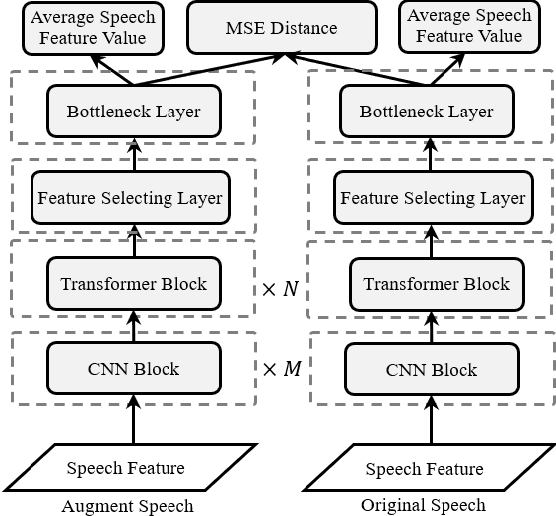

In this paper, we investigated a speech augmentation based unsupervised learning approach for keyword spotting (KWS) task. KWS is a useful speech application, yet also heavily depends on the labeled data. We designed a CNN-Attention architecture to conduct the KWS task. CNN layers focus on the local acoustic features, and attention layers model the long-time dependency. To improve the robustness of KWS model, we also proposed an unsupervised learning method. The unsupervised loss is based on the similarity between the original and augmented speech features, as well as the audio reconstructing information. Two speech augmentation methods are explored in the unsupervised learning: speed and intensity. The experiments on Google Speech Commands V2 Dataset demonstrated that our CNN-Attention model has competitive results. Moreover, the augmentation based unsupervised learning could further improve the classification accuracy of KWS task. In our experiments, with augmentation based unsupervised learning, our KWS model achieves better performance than other unsupervised methods, such as CPC, APC, and MPC.
Adaptive Activation Network For Low Resource Multilingual Speech Recognition
May 28, 2022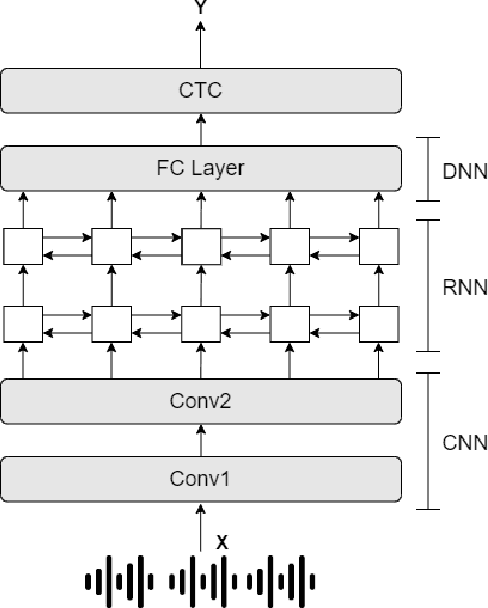
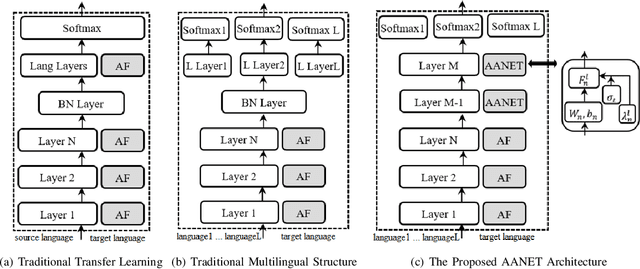

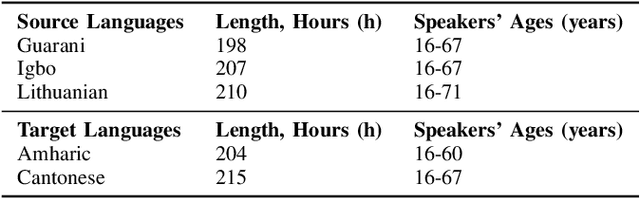
Low resource automatic speech recognition (ASR) is a useful but thorny task, since deep learning ASR models usually need huge amounts of training data. The existing models mostly established a bottleneck (BN) layer by pre-training on a large source language, and transferring to the low resource target language. In this work, we introduced an adaptive activation network to the upper layers of ASR model, and applied different activation functions to different languages. We also proposed two approaches to train the model: (1) cross-lingual learning, replacing the activation function from source language to target language, (2) multilingual learning, jointly training the Connectionist Temporal Classification (CTC) loss of each language and the relevance of different languages. Our experiments on IARPA Babel datasets demonstrated that our approaches outperform the from-scratch training and traditional bottleneck feature based methods. In addition, combining the cross-lingual learning and multilingual learning together could further improve the performance of multilingual speech recognition.
Loss Prediction: End-to-End Active Learning Approach For Speech Recognition
Jul 09, 2021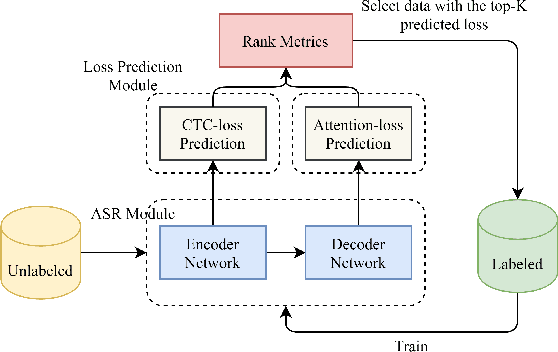
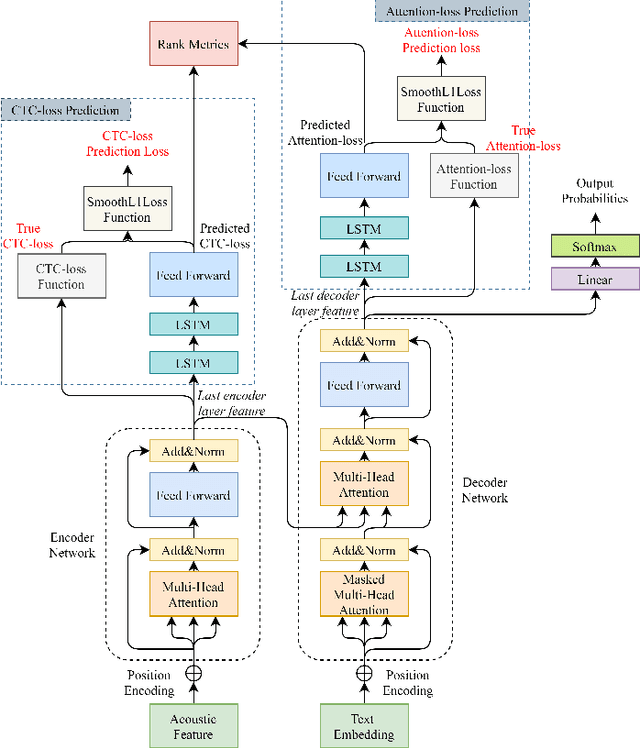
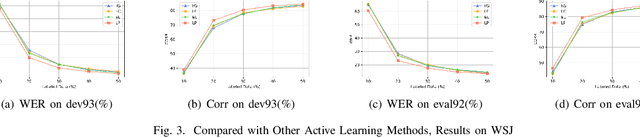

End-to-end speech recognition systems usually require huge amounts of labeling resource, while annotating the speech data is complicated and expensive. Active learning is the solution by selecting the most valuable samples for annotation. In this paper, we proposed to use a predicted loss that estimates the uncertainty of the sample. The CTC (Connectionist Temporal Classification) and attention loss are informative for speech recognition since they are computed based on all decoding paths and alignments. We defined an end-to-end active learning pipeline, training an ASR/LP (Automatic Speech Recognition/Loss Prediction) joint model. The proposed approach was validated on an English and a Chinese speech recognition task. The experiments show that our approach achieves competitive results, outperforming random selection, least confidence, and estimated loss method.
Dropout Regularization for Self-Supervised Learning of Transformer Encoder Speech Representation
Jul 09, 2021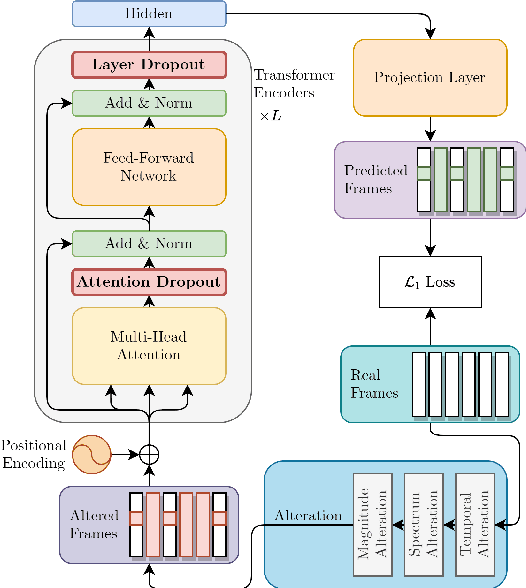
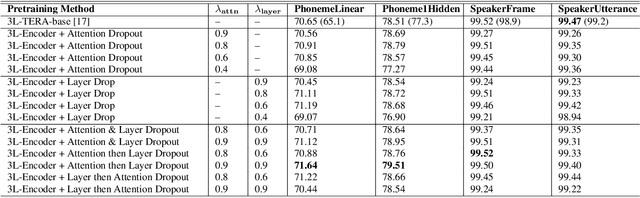

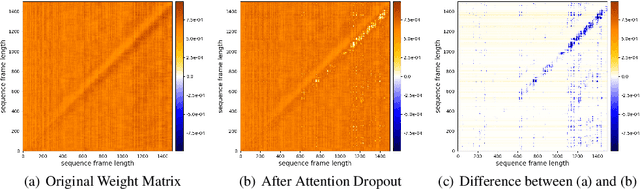
Predicting the altered acoustic frames is an effective way of self-supervised learning for speech representation. However, it is challenging to prevent the pretrained model from overfitting. In this paper, we proposed to introduce two dropout regularization methods into the pretraining of transformer encoder: (1) attention dropout, (2) layer dropout. Both of the two dropout methods encourage the model to utilize global speech information, and avoid just copying local spectrum features when reconstructing the masked frames. We evaluated the proposed methods on phoneme classification and speaker recognition tasks. The experiments demonstrate that our dropout approaches achieve competitive results, and improve the performance of classification accuracy on downstream tasks.