 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Activation Network For Low Resource Multilingual Speech Recognition
Paper and Code
May 28, 2022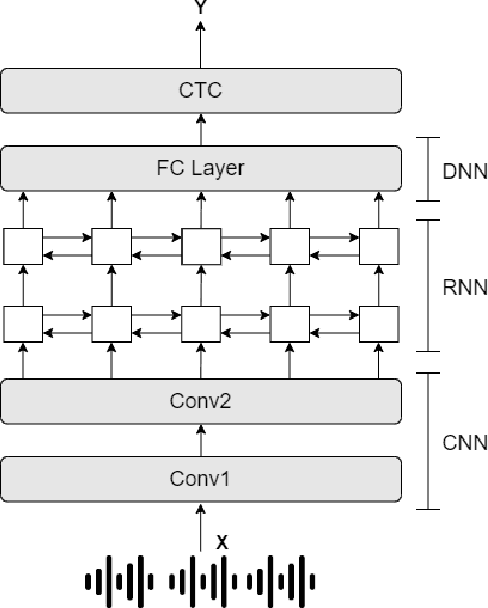
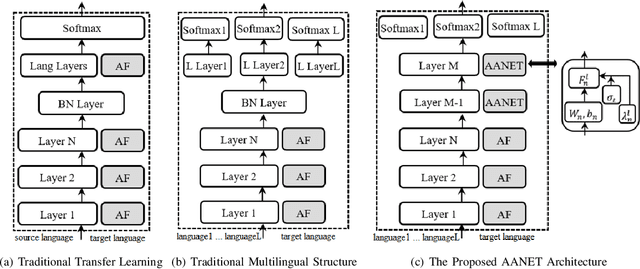

Low resource automatic speech recognition (ASR) is a useful but thorny task, since deep learning ASR models usually need huge amounts of training data. The existing models mostly established a bottleneck (BN) layer by pre-training on a large source language, and transferring to the low resource target language. In this work, we introduced an adaptive activation network to the upper layers of ASR model, and applied different activation functions to different languages. We also proposed two approaches to train the model: (1) cross-lingual learning, replacing the activation function from source language to target language, (2) multilingual learning, jointly training the Connectionist Temporal Classification (CTC) loss of each language and the relevance of different languages. Our experiments on IARPA Babel datasets demonstrated that our approaches outperform the from-scratch training and traditional bottleneck feature based methods. In addition, combining the cross-lingual learning and multilingual learning together could further improve the performance of multilingual speech recognition.