 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeech Representation Disentanglement with Adversarial Mutual Information Learning for One-shot Voice Conversion
Paper and Code
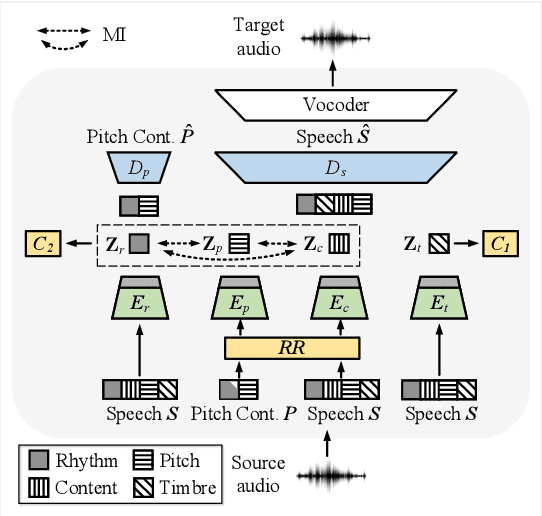

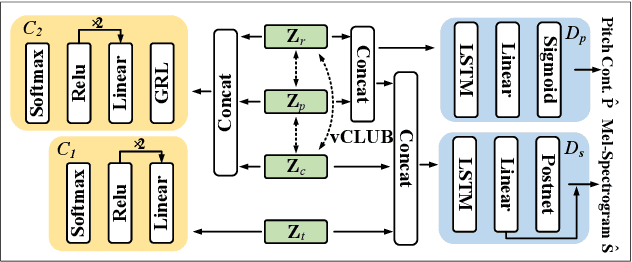
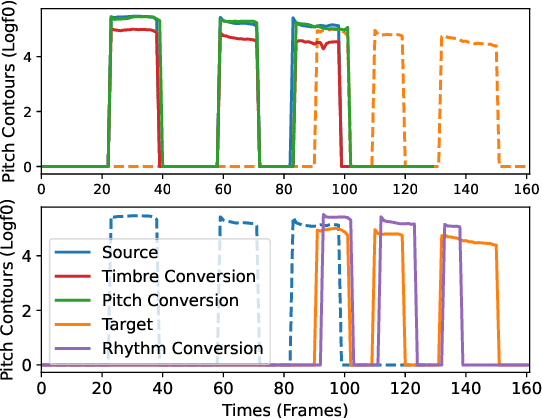
One-shot voice conversion (VC) with only a single target speaker's speech for reference has become a hot research topic. Existing works generally disentangle timbre, while information about pitch, rhythm and content is still mixed together. To perform one-shot VC effectively with further disentangling these speech components, we employ random resampling for pitch and content encoder and use the variational contrastive log-ratio upper bound of mutual information and gradient reversal layer based adversarial mutual information learning to ensure the different parts of the latent space containing only the desired disentangled representation during training. Experiments on the VCTK dataset show the model achieves state-of-the-art performance for one-shot VC in terms of naturalness and intellgibility. In addition, we can transfer characteristics of one-shot VC on timbre, pitch and rhythm separately by speech representation disentanglement. Our code, pre-trained models and demo are available at https://im1eon.github.io/IS2022-SRDVC/.