 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Conversational Agents via Task-Oriented Adversarial Memory Adaptation
Jan 29, 2026Conversational agents struggle to handle long conversations due to context window limitations. Therefore, memory systems are developed to leverage essential historical information. Existing memory systems typically follow a pipeline of offline memory construction and update, and online retrieval. Despite the flexible online phase, the offline phase remains fixed and task-independent. In this phase, memory construction operates under a predefined workflow and fails to emphasize task relevant information. Meanwhile, memory updates are guided by generic metrics rather than task specific supervision. This leads to a misalignment between offline memory preparation and task requirements, which undermines downstream task performance. To this end, we propose an Adversarial Memory Adaptation mechanism (AMA) that aligns memory construction and update with task objectives by simulating task execution. Specifically, first, a challenger agent generates question answer pairs based on the original dialogues. The constructed memory is then used to answer these questions, simulating downstream inference. Subsequently, an evaluator agent assesses the responses and performs error analysis. Finally, an adapter agent analyzes the error cases and performs dual level updates on both the construction strategy and the content. Through this process, the memory system receives task aware supervision signals in advance during the offline phase, enhancing its adaptability to downstream tasks. AMA can be integrated into various existing memory systems, and extensive experiments on long dialogue benchmark LoCoMo demonstrate its effectiveness.
Attention Needs to Focus: A Unified Perspective on Attention Allocation
Jan 07, 2026The Transformer architecture, a cornerstone of modern Large Language Models (LLMs), has achieved extraordinary success in sequence modeling, primarily due to its attention mechanism. However, despite its power, the standard attention mechanism is plagued by well-documented issues: representational collapse and attention sink. Although prior work has proposed approaches for these issues, they are often studied in isolation, obscuring their deeper connection. In this paper, we present a unified perspective, arguing that both can be traced to a common root -- improper attention allocation. We identify two failure modes: 1) Attention Overload, where tokens receive comparable high weights, blurring semantic features that lead to representational collapse; 2) Attention Underload, where no token is semantically relevant, yet attention is still forced to distribute, resulting in spurious focus such as attention sink. Building on this insight, we introduce Lazy Attention, a novel mechanism designed for a more focused attention distribution. To mitigate overload, it employs positional discrimination across both heads and dimensions to sharpen token distinctions. To counteract underload, it incorporates Elastic-Softmax, a modified normalization function that relaxes the standard softmax constraint to suppress attention on irrelevant tokens. Experiments on the FineWeb-Edu corpus, evaluated across nine diverse benchmarks, demonstrate that Lazy Attention successfully mitigates attention sink and achieves competitive performance compared to both standard attention and modern architectures, while reaching up to 59.58% attention sparsity.
A Multi-Expert Structural-Semantic Hybrid Framework for Unveiling Historical Patterns in Temporal Knowledge Graphs
Jun 17, 2025Temporal knowledge graph reasoning aims to predict future events with knowledge of existing facts and plays a key role in various downstream tasks. Previous methods focused on either graph structure learning or semantic reasoning, failing to integrate dual reasoning perspectives to handle different prediction scenarios. Moreover, they lack the capability to capture the inherent differences between historical and non-historical events, which limits their generalization across different temporal contexts. To this end, we propose a Multi-Expert Structural-Semantic Hybrid (MESH) framework that employs three kinds of expert modules to integrate both structural and semantic information, guiding the reasoning process for different events. Extensive experiments on three datasets demonstrate the effectiveness of our approach.
Pseudo-Label Enhanced Prototypical Contrastive Learning for Uniformed Intent Discovery
Oct 26, 2024



New intent discovery is a crucial capability for task-oriented dialogue systems. Existing methods focus on transferring in-domain (IND) prior knowledge to out-of-domain (OOD) data through pre-training and clustering stages. They either handle the two processes in a pipeline manner, which exhibits a gap between intent representation and clustering process or use typical contrastive clustering that overlooks the potential supervised signals from the whole data. Besides, they often individually deal with open intent discovery or OOD settings. To this end, we propose a Pseudo-Label enhanced Prototypical Contrastive Learning (PLPCL) model for uniformed intent discovery. We iteratively utilize pseudo-labels to explore potential positive/negative samples for contrastive learning and bridge the gap between representation and clustering. To enable better knowledge transfer, we design a prototype learning method integrating the supervised and pseudo signals from IND and OOD samples. In addition, our method has been proven effective in two different settings of discovering new intents. Experiments on three benchmark datasets and two task settings demonstrate the effectiveness of our approach.
Learning Expressive Disentangled Speech Representations with Soft Speech Units and Adversarial Style Augmentation
May 01, 2024Voice conversion is the task to transform voice characteristics of source speech while preserving content information. Nowadays, self-supervised representation learning models are increasingly utilized in content extraction. However, in these representations, a lot of hidden speaker information leads to timbre leakage while the prosodic information of hidden units lacks use. To address these issues, we propose a novel framework for expressive voice conversion called "SAVC" based on soft speech units from HuBert-soft. Taking soft speech units as input, we design an attribute encoder to extract content and prosody features respectively. Specifically, we first introduce statistic perturbation imposed by adversarial style augmentation to eliminate speaker information. Then the prosody is implicitly modeled on soft speech units with knowledge distillation. Experiment results show that the intelligibility and naturalness of converted speech outperform previous work.
Learning Disentangled Speech Representations with Contrastive Learning and Time-Invariant Retrieval
Jan 18, 2024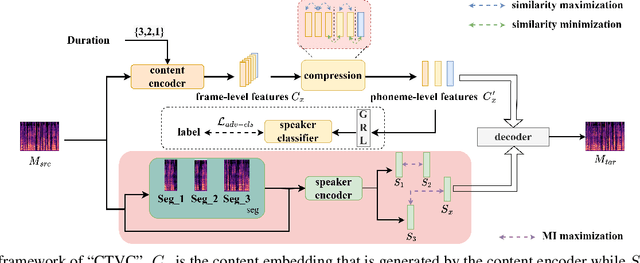
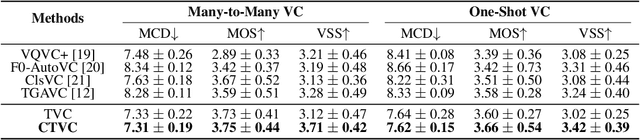
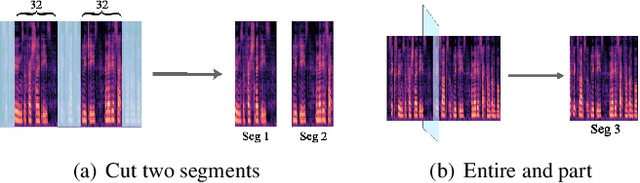

Voice conversion refers to transferring speaker identity with well-preserved content. Better disentanglement of speech representations leads to better voice conversion. Recent studies have found that phonetic information from input audio has the potential ability to well represent content. Besides, the speaker-style modeling with pre-trained models making the process more complex. To tackle these issues, we introduce a new method named "CTVC" which utilizes disentangled speech representations with contrastive learning and time-invariant retrieval. Specifically, a similarity-based compression module is used to facilitate a more intimate connection between the frame-level hidden features and linguistic information at phoneme-level. Additionally, a time-invariant retrieval is proposed for timbre extraction based on multiple segmentations and mutual information. Experimental results demonstrate that "CTVC" outperforms previous studies and improves the sound quality and similarity of converted results.
CLN-VC: Text-Free Voice Conversion Based on Fine-Grained Style Control and Contrastive Learning with Negative Samples Augmentation
Nov 15, 2023

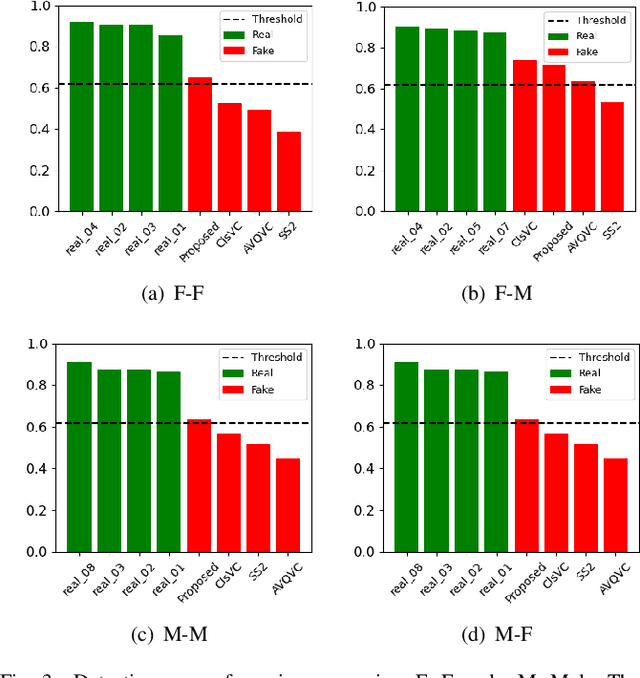
Better disentanglement of speech representation is essential to improve the quality of voice conversion. Recently contrastive learning is applied to voice conversion successfully based on speaker labels. However, the performance of model will reduce in conversion between similar speakers. Hence, we propose an augmented negative sample selection to address the issue. Specifically, we create hard negative samples based on the proposed speaker fusion module to improve learning ability of speaker encoder. Furthermore, considering the fine-grain modeling of speaker style, we employ a reference encoder to extract fine-grained style and conduct the augmented contrastive learning on global style. The experimental results show that the proposed method outperforms previous work in voice conversion tasks.
CP-EB: Talking Face Generation with Controllable Pose and Eye Blinking Embedding
Nov 15, 2023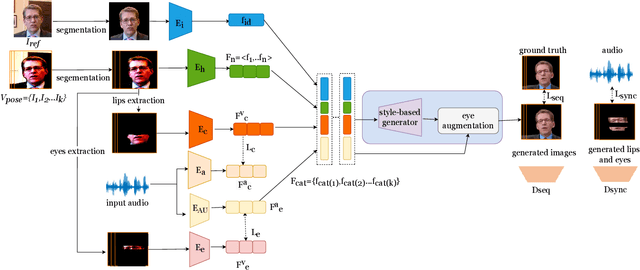
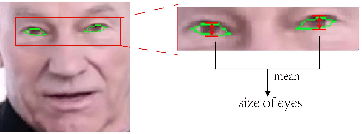
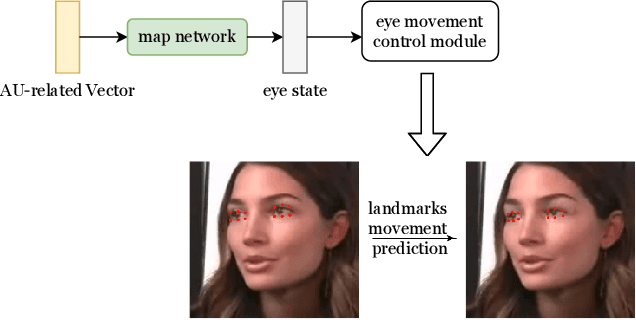

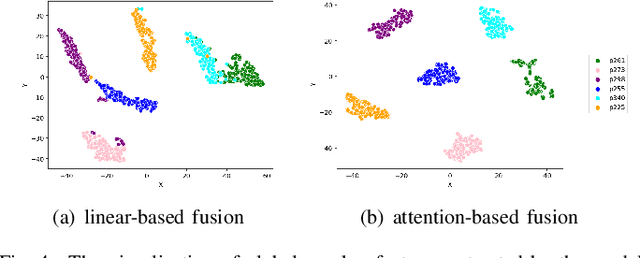
This paper proposes a talking face generation method named "CP-EB" that takes an audio signal as input and a person image as reference, to synthesize a photo-realistic people talking video with head poses controlled by a short video clip and proper eye blinking embedding. It's noted that not only the head pose but also eye blinking are both important aspects for deep fake detection. The implicit control of poses by video has already achieved by the state-of-art work. According to recent research, eye blinking has weak correlation with input audio which means eye blinks extraction from audio and generation are possible. Hence, we propose a GAN-based architecture to extract eye blink feature from input audio and reference video respectively and employ contrastive training between them, then embed it into the concatenated features of identity and poses to generate talking face images. Experimental results show that the proposed method can generate photo-realistic talking face with synchronous lips motions, natural head poses and blinking eyes.
PMVC: Data Augmentation-Based Prosody Modeling for Expressive Voice Conversion
Aug 21, 2023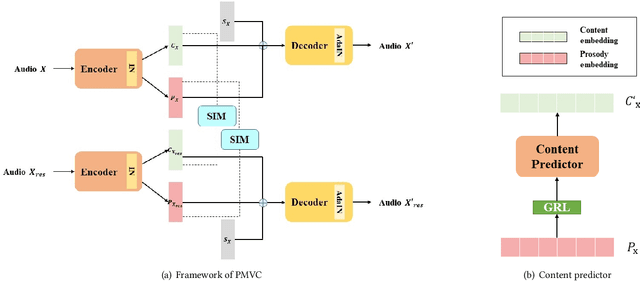



Voice conversion as the style transfer task applied to speech, refers to converting one person's speech into a new speech that sounds like another person's. Up to now, there has been a lot of research devoted to better implementation of VC tasks. However, a good voice conversion model should not only match the timbre information of the target speaker, but also expressive information such as prosody, pace, pause, etc. In this context, prosody modeling is crucial for achieving expressive voice conversion that sounds natural and convincing. Unfortunately, prosody modeling is important but challenging, especially without text transcriptions. In this paper, we firstly propose a novel voice conversion framework named 'PMVC', which effectively separates and models the content, timbre, and prosodic information from the speech without text transcriptions. Specially, we introduce a new speech augmentation algorithm for robust prosody extraction. And building upon this, mask and predict mechanism is applied in the disentanglement of prosody and content information. The experimental results on the AIShell-3 corpus supports our improvement of naturalness and similarity of converted speech.
Self-Supervised Scene Flow Estimation with 4D Automotive Radar
Mar 02, 2022
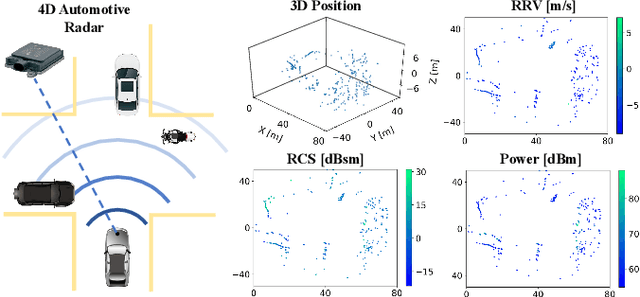
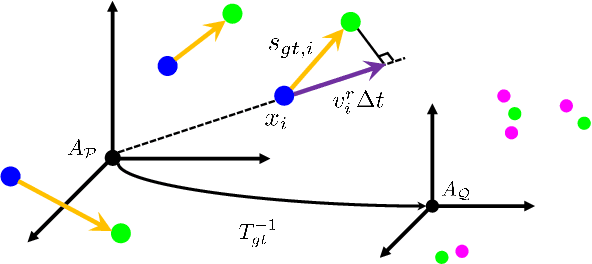
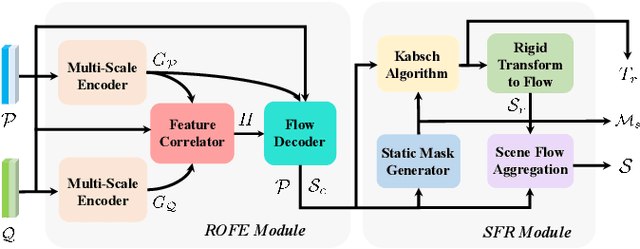
Scene flow allows autonomous vehicles to reason about the arbitrary motion of multiple independent objects which is the key to long-term mobile autonomy. While estimating the scene flow from LiDAR has progressed recently, it remains largely unknown how to estimate the scene flow from a 4D radar - an increasingly popular automotive sensor for its robustness against adverse weather and lighting conditions. Compared with the LiDAR point clouds, radar data are drastically sparser, noisier and in much lower resolution. Annotated datasets for radar scene flow are also in absence and costly to acquire in the real world. These factors jointly pose the radar scene flow estimation as a challenging problem. This work aims to address the above challenges and estimate scene flow from 4D radar point clouds by leveraging self-supervised learning. A robust scene flow estimation architecture and three novel losses are bespoken designed to cope with intractable radar data. Real-world experimental results validate that our method is able to robustly estimate the radar scene flow in the wild and effectively supports the downstream task of motion segmentation.