 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePAOLI: Pose-free Articulated Object Learning from Sparse-view Images
Sep 04, 2025We present a novel self-supervised framework for learning articulated object representations from sparse-view, unposed images. Unlike prior methods that require dense multi-view observations and ground-truth camera poses, our approach operates with as few as four views per articulation and no camera supervision. To address the inherent challenges, we first reconstruct each articulation independently using recent advances in sparse-view 3D reconstruction, then learn a deformation field that establishes dense correspondences across poses. A progressive disentanglement strategy further separates static from moving parts, enabling robust separation of camera and object motion. Finally, we jointly optimize geometry, appearance, and kinematics with a self-supervised loss that enforces cross-view and cross-pose consistency. Experiments on the standard benchmark and real-world examples demonstrate that our method produces accurate and detailed articulated object representations under significantly weaker input assumptions than existing approaches.
Articulate your NeRF: Unsupervised articulated object modeling via conditional view synthesis
Jun 24, 2024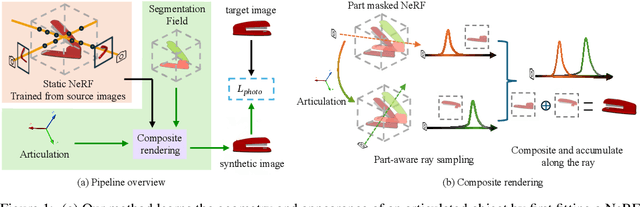
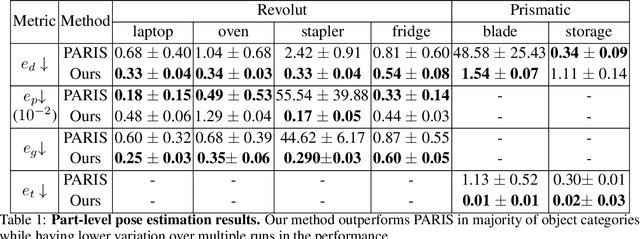
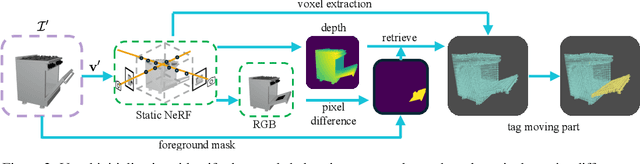
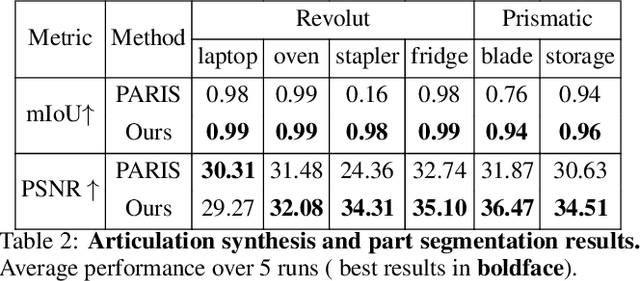
We propose a novel unsupervised method to learn the pose and part-segmentation of articulated objects with rigid parts. Given two observations of an object in different articulation states, our method learns the geometry and appearance of object parts by using an implicit model from the first observation, distils the part segmentation and articulation from the second observation while rendering the latter observation. Additionally, to tackle the complexities in the joint optimization of part segmentation and articulation, we propose a voxel grid-based initialization strategy and a decoupled optimization procedure. Compared to the prior unsupervised work, our model obtains significantly better performance, and generalizes to objects with multiple parts while it can be efficiently from few views for the latter observation.
See Beyond Seeing: Robust 3D Object Detection from Point Clouds via Cross-Modal Hallucination
Sep 29, 2023



This paper presents a novel framework for robust 3D object detection from point clouds via cross-modal hallucination. Our proposed approach is agnostic to either hallucination direction between LiDAR and 4D radar. We introduce multiple alignments on both spatial and feature levels to achieve simultaneous backbone refinement and hallucination generation. Specifically, spatial alignment is proposed to deal with the geometry discrepancy for better instance matching between LiDAR and radar. The feature alignment step further bridges the intrinsic attribute gap between the sensing modalities and stabilizes the training. The trained object detection models can deal with difficult detection cases better, even though only single-modal data is used as the input during the inference stage. Extensive experiments on the View-of-Delft (VoD) dataset show that our proposed method outperforms the state-of-the-art (SOTA) methods for both radar and LiDAR object detection while maintaining competitive efficiency in runtime.
Self-Supervised Scene Flow Estimation with 4D Automotive Radar
Mar 02, 2022
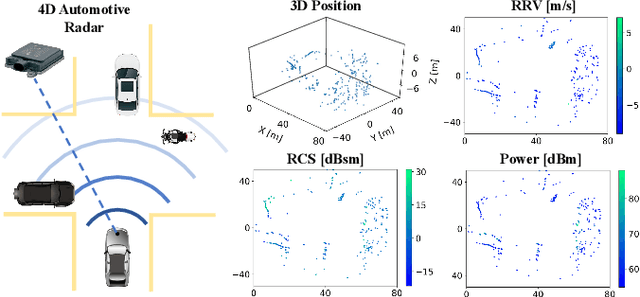
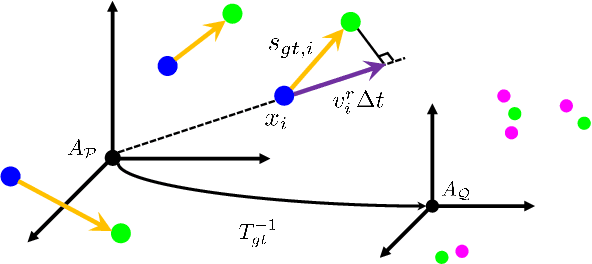
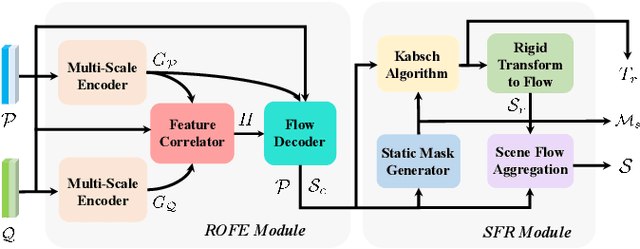
Scene flow allows autonomous vehicles to reason about the arbitrary motion of multiple independent objects which is the key to long-term mobile autonomy. While estimating the scene flow from LiDAR has progressed recently, it remains largely unknown how to estimate the scene flow from a 4D radar - an increasingly popular automotive sensor for its robustness against adverse weather and lighting conditions. Compared with the LiDAR point clouds, radar data are drastically sparser, noisier and in much lower resolution. Annotated datasets for radar scene flow are also in absence and costly to acquire in the real world. These factors jointly pose the radar scene flow estimation as a challenging problem. This work aims to address the above challenges and estimate scene flow from 4D radar point clouds by leveraging self-supervised learning. A robust scene flow estimation architecture and three novel losses are bespoken designed to cope with intractable radar data. Real-world experimental results validate that our method is able to robustly estimate the radar scene flow in the wild and effectively supports the downstream task of motion segmentation.