 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArticulate your NeRF: Unsupervised articulated object modeling via conditional view synthesis
Paper and Code
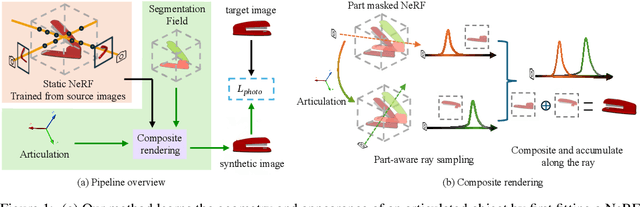
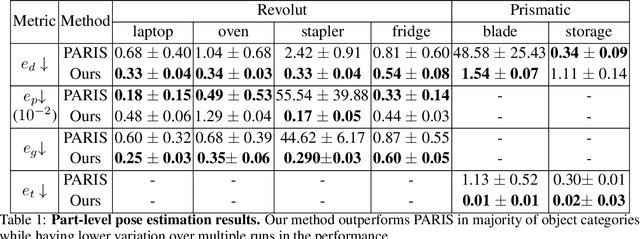
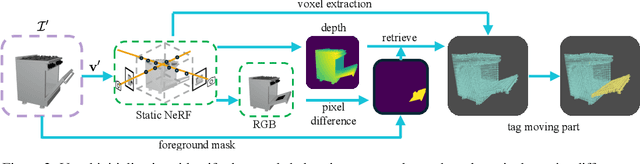
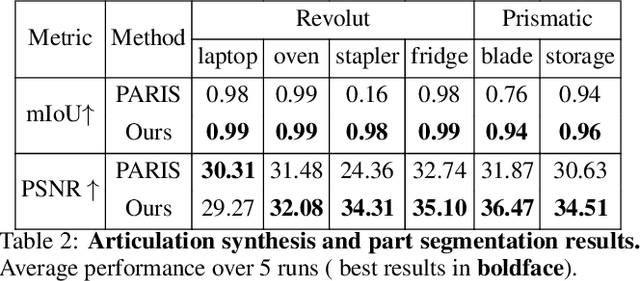
We propose a novel unsupervised method to learn the pose and part-segmentation of articulated objects with rigid parts. Given two observations of an object in different articulation states, our method learns the geometry and appearance of object parts by using an implicit model from the first observation, distils the part segmentation and articulation from the second observation while rendering the latter observation. Additionally, to tackle the complexities in the joint optimization of part segmentation and articulation, we propose a voxel grid-based initialization strategy and a decoupled optimization procedure. Compared to the prior unsupervised work, our model obtains significantly better performance, and generalizes to objects with multiple parts while it can be efficiently from few views for the latter observation.