 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLN-VC: Text-Free Voice Conversion Based on Fine-Grained Style Control and Contrastive Learning with Negative Samples Augmentation
Paper and Code


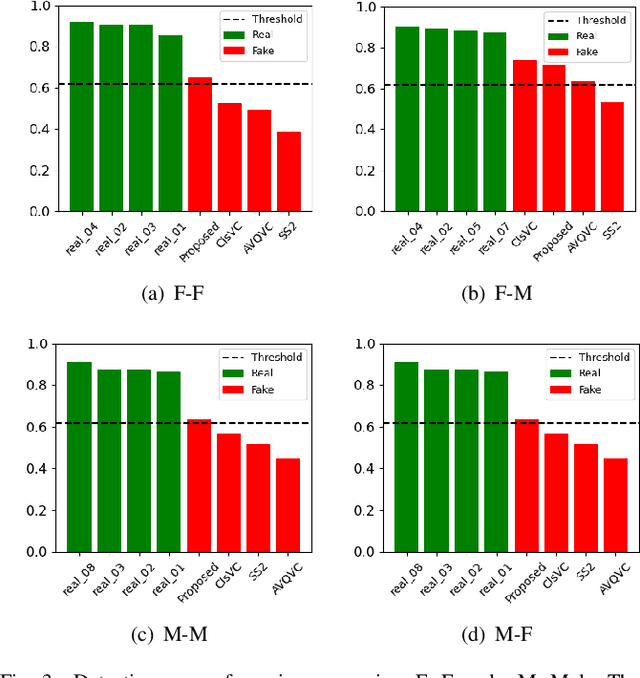
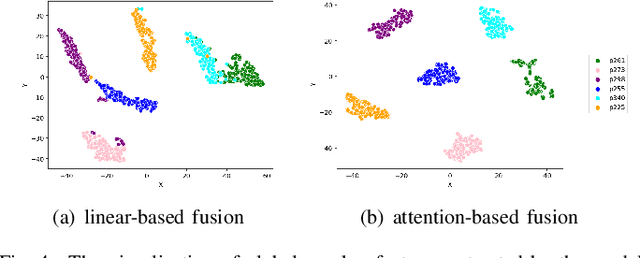
Better disentanglement of speech representation is essential to improve the quality of voice conversion. Recently contrastive learning is applied to voice conversion successfully based on speaker labels. However, the performance of model will reduce in conversion between similar speakers. Hence, we propose an augmented negative sample selection to address the issue. Specifically, we create hard negative samples based on the proposed speaker fusion module to improve learning ability of speaker encoder. Furthermore, considering the fine-grain modeling of speaker style, we employ a reference encoder to extract fine-grained style and conduct the augmented contrastive learning on global style. The experimental results show that the proposed method outperforms previous work in voice conversion tasks.