 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttention Needs to Focus: A Unified Perspective on Attention Allocation
Jan 07, 2026The Transformer architecture, a cornerstone of modern Large Language Models (LLMs), has achieved extraordinary success in sequence modeling, primarily due to its attention mechanism. However, despite its power, the standard attention mechanism is plagued by well-documented issues: representational collapse and attention sink. Although prior work has proposed approaches for these issues, they are often studied in isolation, obscuring their deeper connection. In this paper, we present a unified perspective, arguing that both can be traced to a common root -- improper attention allocation. We identify two failure modes: 1) Attention Overload, where tokens receive comparable high weights, blurring semantic features that lead to representational collapse; 2) Attention Underload, where no token is semantically relevant, yet attention is still forced to distribute, resulting in spurious focus such as attention sink. Building on this insight, we introduce Lazy Attention, a novel mechanism designed for a more focused attention distribution. To mitigate overload, it employs positional discrimination across both heads and dimensions to sharpen token distinctions. To counteract underload, it incorporates Elastic-Softmax, a modified normalization function that relaxes the standard softmax constraint to suppress attention on irrelevant tokens. Experiments on the FineWeb-Edu corpus, evaluated across nine diverse benchmarks, demonstrate that Lazy Attention successfully mitigates attention sink and achieves competitive performance compared to both standard attention and modern architectures, while reaching up to 59.58% attention sparsity.
A Multi-Expert Structural-Semantic Hybrid Framework for Unveiling Historical Patterns in Temporal Knowledge Graphs
Jun 17, 2025Temporal knowledge graph reasoning aims to predict future events with knowledge of existing facts and plays a key role in various downstream tasks. Previous methods focused on either graph structure learning or semantic reasoning, failing to integrate dual reasoning perspectives to handle different prediction scenarios. Moreover, they lack the capability to capture the inherent differences between historical and non-historical events, which limits their generalization across different temporal contexts. To this end, we propose a Multi-Expert Structural-Semantic Hybrid (MESH) framework that employs three kinds of expert modules to integrate both structural and semantic information, guiding the reasoning process for different events. Extensive experiments on three datasets demonstrate the effectiveness of our approach.
Model Merging for Knowledge Editing
Jun 14, 2025Large Language Models (LLMs) require continuous updates to maintain accurate and current knowledge as the world evolves. While existing knowledge editing approaches offer various solutions for knowledge updating, they often struggle with sequential editing scenarios and harm the general capabilities of the model, thereby significantly hampering their practical applicability. This paper proposes a two-stage framework combining robust supervised fine-tuning (R-SFT) with model merging for knowledge editing. Our method first fine-tunes the LLM to internalize new knowledge fully, then merges the fine-tuned model with the original foundation model to preserve newly acquired knowledge and general capabilities. Experimental results demonstrate that our approach significantly outperforms existing methods in sequential editing while better preserving the original performance of the model, all without requiring any architectural changes. Code is available at: https://github.com/Applied-Machine-Learning-Lab/MM4KE.
* 11 pages, 3 figures
Training-free LLM Merging for Multi-task Learning
Jun 14, 2025



Large Language Models (LLMs) have demonstrated exceptional capabilities across diverse natural language processing (NLP) tasks. The release of open-source LLMs like LLaMA and Qwen has triggered the development of numerous fine-tuned models tailored for various tasks and languages. In this paper, we explore an important question: is it possible to combine these specialized models to create a unified model with multi-task capabilities. We introduces Hierarchical Iterative Merging (Hi-Merging), a training-free method for unifying different specialized LLMs into a single model. Specifically, Hi-Merging employs model-wise and layer-wise pruning and scaling, guided by contribution analysis, to mitigate parameter conflicts. Extensive experiments on multiple-choice and question-answering tasks in both Chinese and English validate Hi-Merging's ability for multi-task learning. The results demonstrate that Hi-Merging consistently outperforms existing merging techniques and surpasses the performance of models fine-tuned on combined datasets in most scenarios. Code is available at: https://github.com/Applied-Machine-Learning-Lab/Hi-Merging.
* 14 pages, 6 figures
Sliding Window Attention Training for Efficient Large Language Models
Feb 26, 2025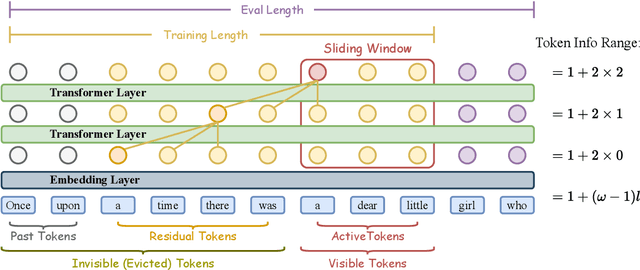
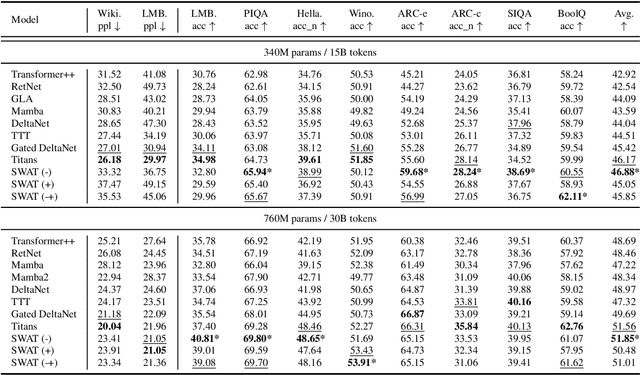
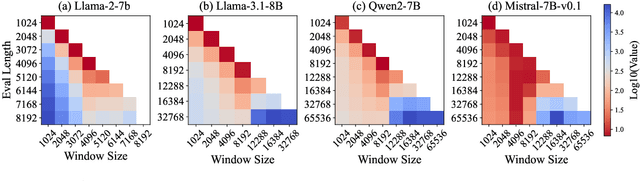
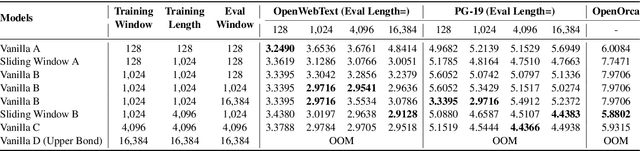
Recent advances in transformer-based Large Language Models (LLMs) have demonstrated remarkable capabilities across various tasks. However, their quadratic computational complexity concerning sequence length remains a significant bottleneck for processing long documents. As a result, many efforts like sparse attention and state space models have been proposed to improve the efficiency of LLMs over long sequences. Though effective, these approaches compromise the performance or introduce structural complexity. This calls for a simple yet efficient model that preserves the fundamental Transformer architecture. To this end, we introduce SWAT, which enables efficient long-context handling via Sliding Window Attention Training. This paper first attributes the inefficiency of Transformers to the attention sink phenomenon resulting from the high variance of softmax operation. Then, we replace softmax with the sigmoid function and utilize a balanced ALiBi and Rotary Position Embedding for efficient information compression and retention. Experiments demonstrate that SWAT achieves SOTA performance compared with state-of-the-art linear recurrent architectures on eight benchmarks. Code is available at https://anonymous.4open.science/r/SWAT-attention.
LLM4MSR: An LLM-Enhanced Paradigm for Multi-Scenario Recommendation
Jun 18, 2024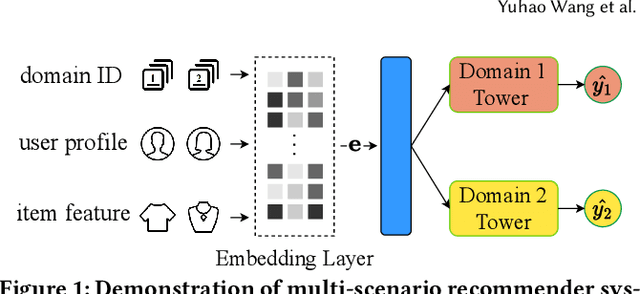
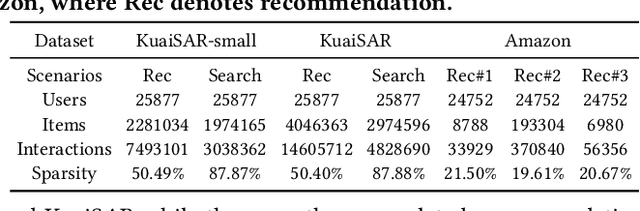
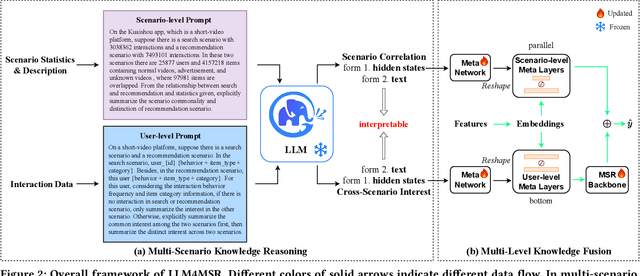
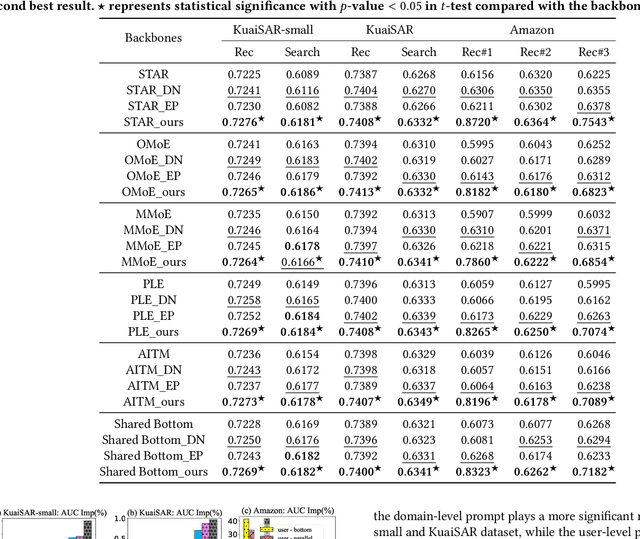
As the demand for more personalized recommendation grows and a dramatic boom in commercial scenarios arises, the study on multi-scenario recommendation (MSR) has attracted much attention, which uses the data from all scenarios to simultaneously improve their recommendation performance. However, existing methods tend to integrate insufficient scenario knowledge and neglect learning personalized cross-scenario preferences, thus leading to suboptimal performance and inadequate interpretability. Meanwhile, though large language model (LLM) has shown great capability of reasoning and capturing semantic information, the high inference latency and high computation cost of tuning hinder its implementation in industrial recommender systems. To fill these gaps, we propose an effective efficient interpretable LLM-enhanced paradigm LLM4MSR in this work. Specifically, we first leverage LLM to uncover multi-level knowledge including scenario correlations and users' cross-scenario interests from the designed scenario- and user-level prompt without fine-tuning the LLM, then adopt hierarchical meta networks to generate multi-level meta layers to explicitly improves the scenario-aware and personalized recommendation capability. Our experiments on KuaiSAR-small, KuaiSAR, and Amazon datasets validate two significant advantages of LLM4MSR: (i) the effectiveness and compatibility with different multi-scenario backbone models (achieving 1.5%, 1%, and 40% AUC improvement on three datasets), (ii) high efficiency and deployability on industrial recommender systems, and (iii) improved interpretability. The implemented code and data is available to ease reproduction.
A Unified Framework for Multi-Domain CTR Prediction via Large Language Models
Dec 20, 2023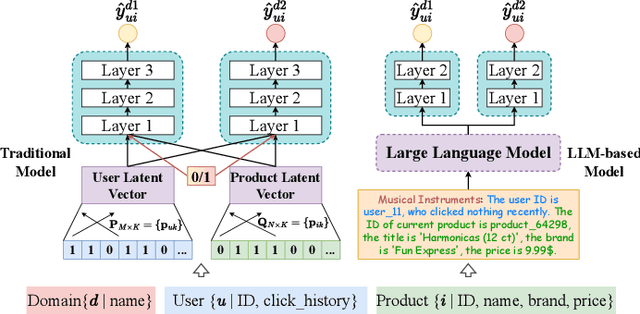
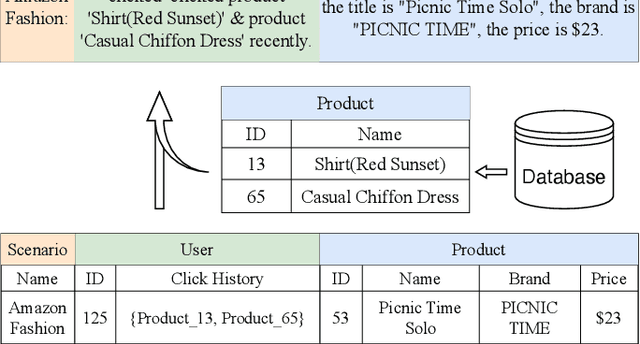
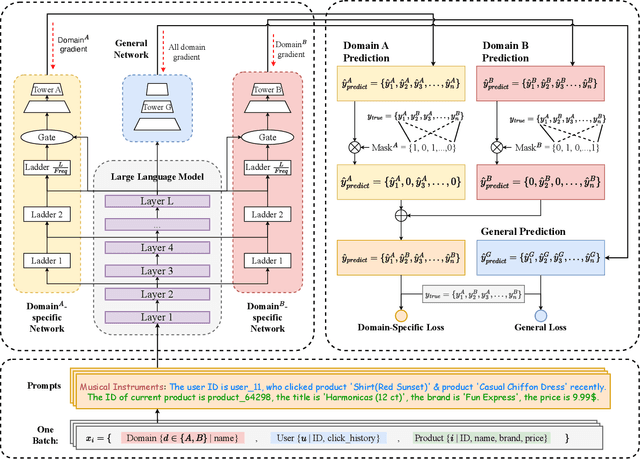
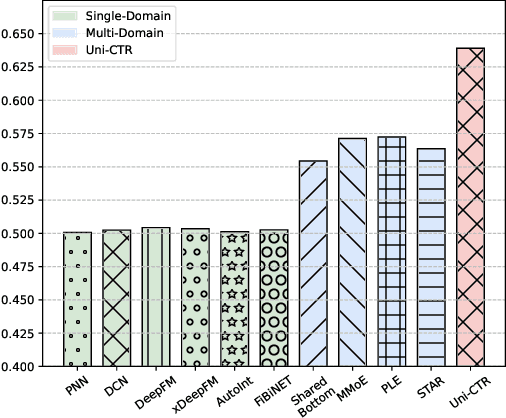
Click-Through Rate (CTR) prediction is a crucial task in online recommendation platforms as it involves estimating the probability of user engagement with advertisements or items by clicking on them. Given the availability of various services like online shopping, ride-sharing, food delivery, and professional services on commercial platforms, recommendation systems in these platforms are required to make CTR predictions across multiple domains rather than just a single domain. However, multi-domain click-through rate (MDCTR) prediction remains a challenging task in online recommendation due to the complex mutual influence between domains. Traditional MDCTR models typically encode domains as discrete identifiers, ignoring rich semantic information underlying. Consequently, they can hardly generalize to new domains. Besides, existing models can be easily dominated by some specific domains, which results in significant performance drops in the other domains (\ie the ``seesaw phenomenon``). In this paper, we propose a novel solution Uni-CTR to address the above challenges. Uni-CTR leverages a backbone Large Language Model (LLM) to learn layer-wise semantic representations that capture commonalities between domains. Uni-CTR also uses several domain-specific networks to capture the characteristics of each domain. Note that we design a masked loss strategy so that these domain-specific networks are decoupled from backbone LLM. This allows domain-specific networks to remain unchanged when incorporating new or removing domains, thereby enhancing the flexibility and scalability of the system significantly. Experimental results on three public datasets show that Uni-CTR outperforms the state-of-the-art (SOTA) MDCTR models significantly. Furthermore, Uni-CTR demonstrates remarkable effectiveness in zero-shot prediction. We have applied Uni-CTR in industrial scenarios, confirming its efficiency.