 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePADiff: Predictive and Adaptive Diffusion Policies for Ad Hoc Teamwork
Nov 10, 2025Ad hoc teamwork (AHT) requires agents to collaborate with previously unseen teammates, which is crucial for many real-world applications. The core challenge of AHT is to develop an ego agent that can predict and adapt to unknown teammates on the fly. Conventional RL-based approaches optimize a single expected return, which often causes policies to collapse into a single dominant behavior, thus failing to capture the multimodal cooperation patterns inherent in AHT. In this work, we introduce PADiff, a diffusion-based approach that captures agent's multimodal behaviors, unlocking its diverse cooperation modes with teammates. However, standard diffusion models lack the ability to predict and adapt in highly non-stationary AHT scenarios. To address this limitation, we propose a novel diffusion-based policy that integrates critical predictive information about teammates into the denoising process. Extensive experiments across three cooperation environments demonstrate that PADiff outperforms existing AHT methods significantly.
GeRe: Towards Efficient Anti-Forgetting in Continual Learning of LLM via General Samples Replay
Aug 06, 2025The continual learning capability of large language models (LLMs) is crucial for advancing artificial general intelligence. However, continual fine-tuning LLMs across various domains often suffers from catastrophic forgetting, characterized by: 1) significant forgetting of their general capabilities, and 2) sharp performance declines in previously learned tasks. To simultaneously address both issues in a simple yet stable manner, we propose General Sample Replay (GeRe), a framework that use usual pretraining texts for efficient anti-forgetting. Beyond revisiting the most prevalent replay-based practices under GeRe, we further leverage neural states to introduce a enhanced activation states constrained optimization method using threshold-based margin (TM) loss, which maintains activation state consistency during replay learning. We are the first to validate that a small, fixed set of pre-collected general replay samples is sufficient to resolve both concerns--retaining general capabilities while promoting overall performance across sequential tasks. Indeed, the former can inherently facilitate the latter. Through controlled experiments, we systematically compare TM with different replay strategies under the GeRe framework, including vanilla label fitting, logit imitation via KL divergence and feature imitation via L1/L2 losses. Results demonstrate that TM consistently improves performance and exhibits better robustness. Our work paves the way for efficient replay of LLMs for the future. Our code and data are available at https://github.com/Qznan/GeRe.
A Unified Framework for Multi-Domain CTR Prediction via Large Language Models
Dec 20, 2023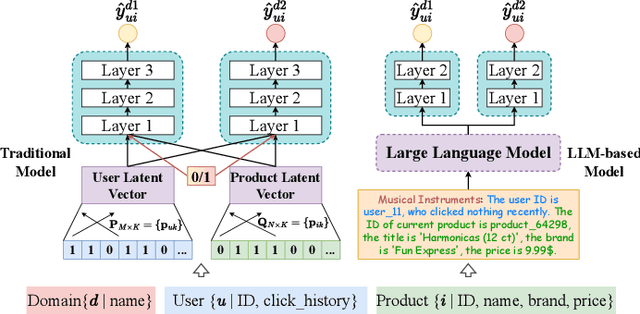
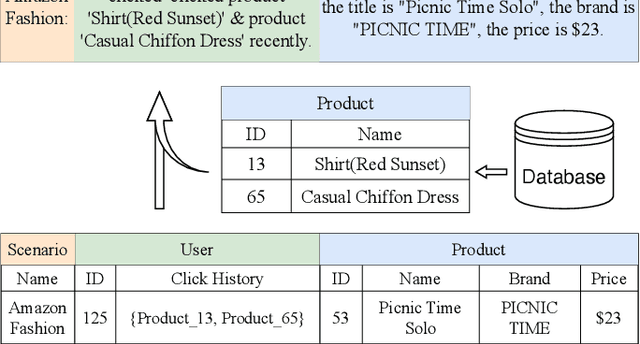
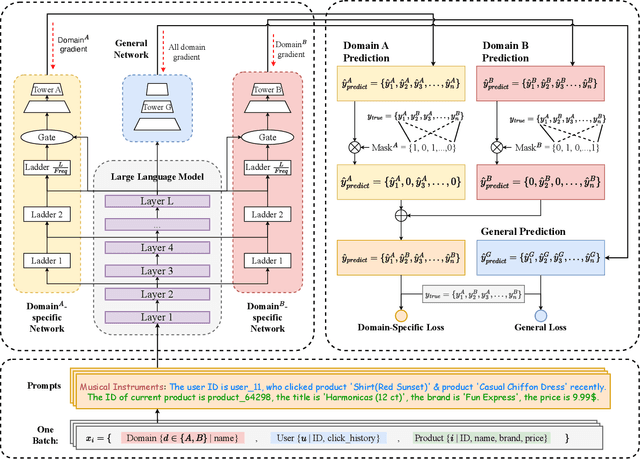
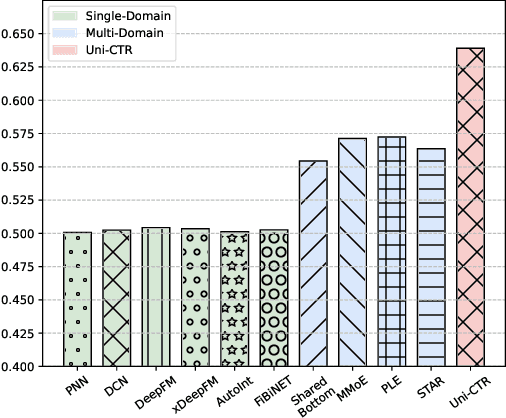
Click-Through Rate (CTR) prediction is a crucial task in online recommendation platforms as it involves estimating the probability of user engagement with advertisements or items by clicking on them. Given the availability of various services like online shopping, ride-sharing, food delivery, and professional services on commercial platforms, recommendation systems in these platforms are required to make CTR predictions across multiple domains rather than just a single domain. However, multi-domain click-through rate (MDCTR) prediction remains a challenging task in online recommendation due to the complex mutual influence between domains. Traditional MDCTR models typically encode domains as discrete identifiers, ignoring rich semantic information underlying. Consequently, they can hardly generalize to new domains. Besides, existing models can be easily dominated by some specific domains, which results in significant performance drops in the other domains (\ie the ``seesaw phenomenon``). In this paper, we propose a novel solution Uni-CTR to address the above challenges. Uni-CTR leverages a backbone Large Language Model (LLM) to learn layer-wise semantic representations that capture commonalities between domains. Uni-CTR also uses several domain-specific networks to capture the characteristics of each domain. Note that we design a masked loss strategy so that these domain-specific networks are decoupled from backbone LLM. This allows domain-specific networks to remain unchanged when incorporating new or removing domains, thereby enhancing the flexibility and scalability of the system significantly. Experimental results on three public datasets show that Uni-CTR outperforms the state-of-the-art (SOTA) MDCTR models significantly. Furthermore, Uni-CTR demonstrates remarkable effectiveness in zero-shot prediction. We have applied Uni-CTR in industrial scenarios, confirming its efficiency.
The ReprGesture entry to the GENEA Challenge 2022
Aug 25, 2022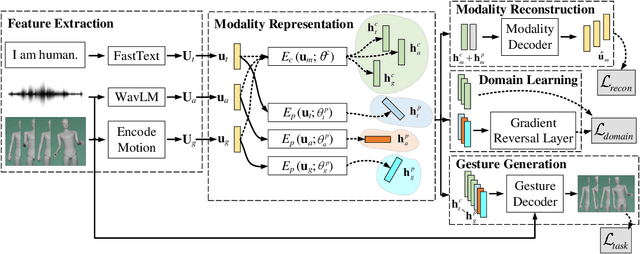
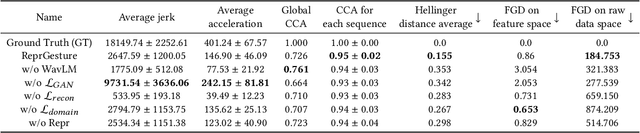

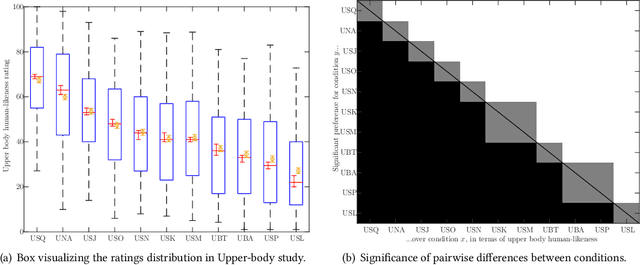
This paper describes the ReprGesture entry to the Generation and Evaluation of Non-verbal Behaviour for Embodied Agents (GENEA) challenge 2022. The GENEA challenge provides the processed datasets and performs crowdsourced evaluations to compare the performance of different gesture generation systems. In this paper, we explore an automatic gesture generation system based on multimodal representation learning. We use WavLM features for audio, FastText features for text and position and rotation matrix features for gesture. Each modality is projected to two distinct subspaces: modality-invariant and modality-specific. To learn inter-modality-invariant commonalities and capture the characters of modality-specific representations, gradient reversal layer based adversarial classifier and modality reconstruction decoders are used during training. The gesture decoder generates proper gestures using all representations and features related to the rhythm in the audio. Our code, pre-trained models and demo are available at https://github.com/YoungSeng/ReprGesture.
CMML: Contextual Modulation Meta Learning for Cold-Start Recommendation
Sep 08, 2021

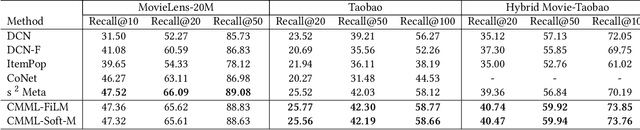
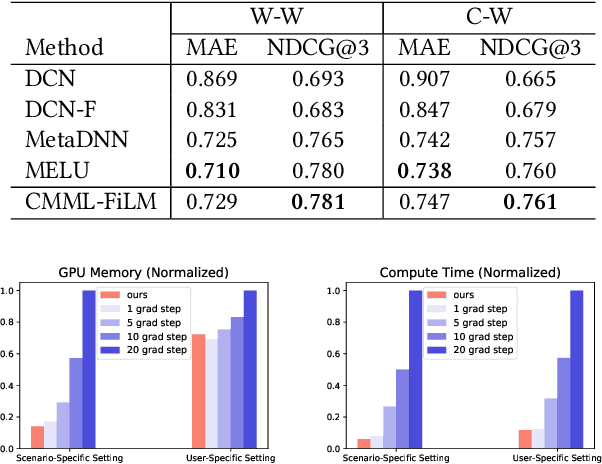
Practical recommender systems experience a cold-start problem when observed user-item interactions in the history are insufficient. Meta learning, especially gradient based one, can be adopted to tackle this problem by learning initial parameters of the model and thus allowing fast adaptation to a specific task from limited data examples. Though with significant performance improvement, it commonly suffers from two critical issues: the non-compatibility with mainstream industrial deployment and the heavy computational burdens, both due to the inner-loop gradient operation. These two issues make them hard to be applied in practical recommender systems. To enjoy the benefits of meta learning framework and mitigate these problems, we propose a recommendation framework called Contextual Modulation Meta Learning (CMML). CMML is composed of fully feed-forward operations so it is computationally efficient and completely compatible with the mainstream industrial deployment. CMML consists of three components, including a context encoder that can generate context embedding to represent a specific task, a hybrid context generator that aggregates specific user-item features with task-level context, and a contextual modulation network, which can modulate the recommendation model to adapt effectively. We validate our approach on both scenario-specific and user-specific cold-start setting on various real-world datasets, showing CMML can achieve comparable or even better performance with gradient based methods yet with much higher computational efficiency and better interpretability.
Modeling Scale-free Graphs for Knowledge-aware Recommendation
Aug 14, 2021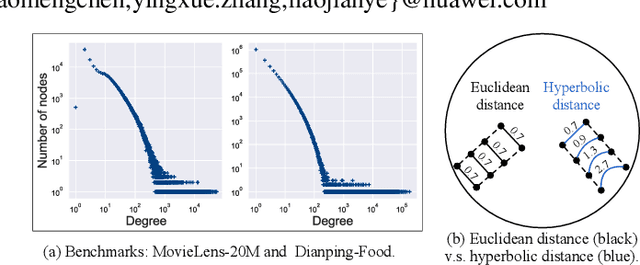
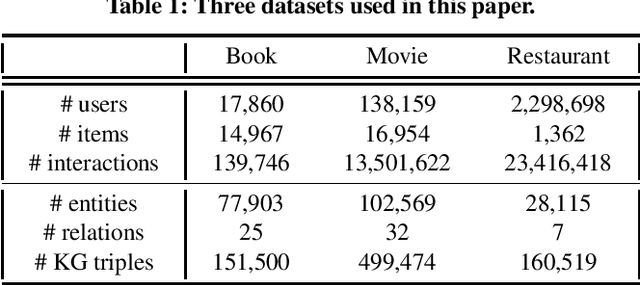
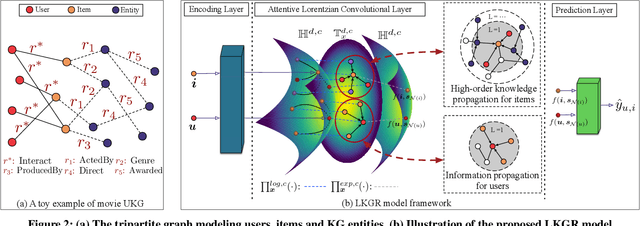
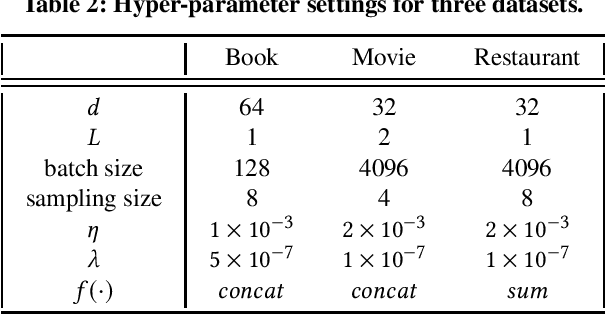
Aiming to alleviate data sparsity and cold-start problems of traditional recommender systems, incorporating knowledge graphs (KGs) to supplement auxiliary information has recently gained considerable attention. Via unifying the KG with user-item interactions into a tripartite graph, recent works explore the graph topologies to learn the low-dimensional representations of users and items with rich semantics. However, these real-world tripartite graphs are usually scale-free, the intrinsic hierarchical graph structures of which are underemphasized in existing works, consequently, leading to suboptimal recommendation performance. To address this issue and provide more accurate recommendation, we propose a knowledge-aware recommendation method with the hyperbolic geometry, namely Lorentzian Knowledge-enhanced Graph convolutional networks for Recommendation (LKGR). LKGR facilitates better modeling of scale-free tripartite graphs after the data unification. Specifically, we employ different information propagation strategies in the hyperbolic space to explicitly encode heterogeneous information from historical interactions and KGs. Our proposed knowledge-aware attention mechanism enables the model to automatically measure the information contribution, producing the coherent information aggregation in the hyperbolic space. Extensive experiments on three real-world benchmarks demonstrate that LKGR outperforms state-of-the-art methods by 2.2-29.9% of Recall@20 on Top-K recommendation.
Dynamic Horizon Value Estimation for Model-based Reinforcement Learning
Sep 21, 2020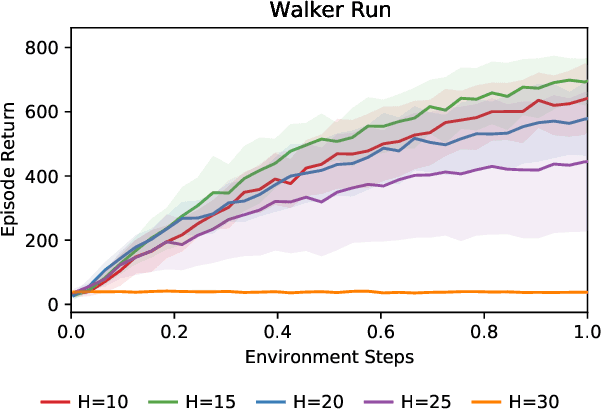


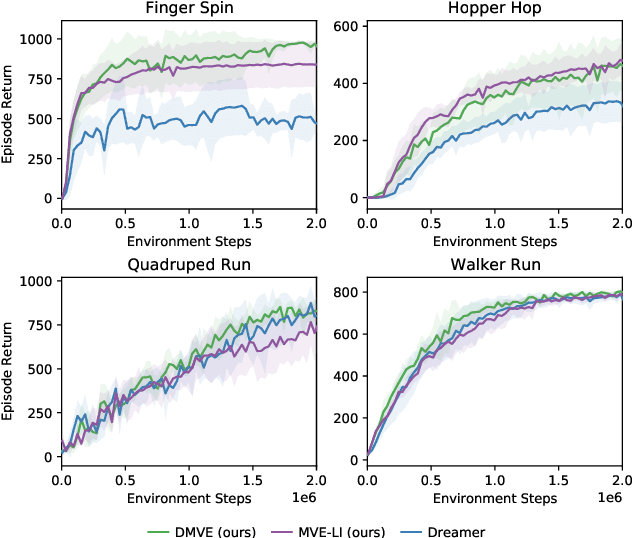
Existing model-based value expansion methods typically leverage a world model for value estimation with a fixed rollout horizon to assist policy learning. However, the fixed rollout with an inaccurate model has a potential to harm the learning process. In this paper, we investigate the idea of using the model knowledge for value expansion adaptively. We propose a novel method called Dynamic-horizon Model-based Value Expansion (DMVE) to adjust the world model usage with different rollout horizons. Inspired by reconstruction-based techniques that can be applied for visual data novelty detection, we utilize a world model with a reconstruction module for image feature extraction, in order to acquire more precise value estimation. The raw and the reconstructed images are both used to determine the appropriate horizon for adaptive value expansion. On several benchmark visual control tasks, experimental results show that DMVE outperforms all baselines in sample efficiency and final performance, indicating that DMVE can achieve more effective and accurate value estimation than state-of-the-art model-based methods.
Vehicle Traffic Driven Camera Placement for Better Metropolis Security Surveillance
Aug 20, 2018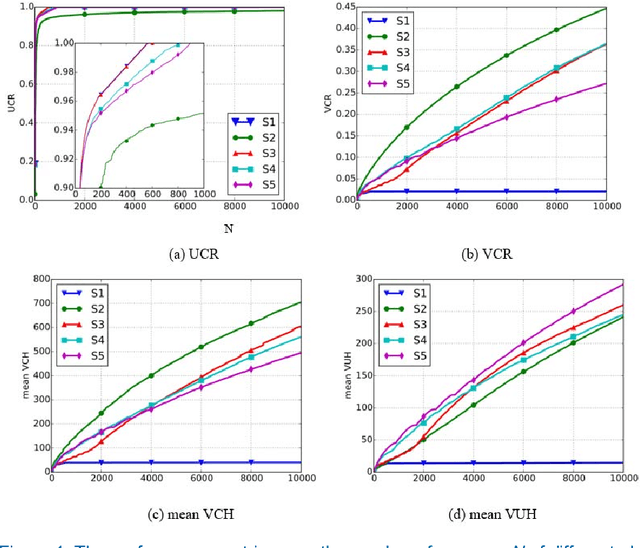
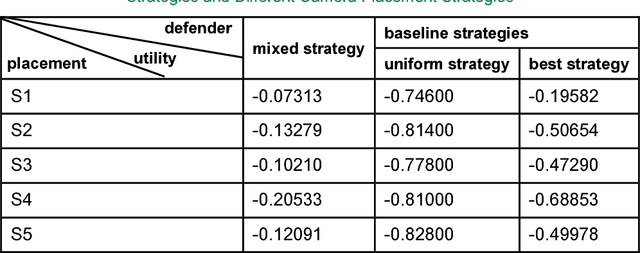

Security surveillance is one of the most important issues in smart cities, especially in an era of terrorism. Deploying a number of (video) cameras is a common surveillance approach. Given the never-ending power offered by vehicles to metropolises, exploiting vehicle traffic to design camera placement strategies could potentially facilitate security surveillance. This article constitutes the first effort toward building the linkage between vehicle traffic and security surveillance, which is a critical problem for smart cities. We expect our study could influence the decision making of surveillance camera placement, and foster more research of principled ways of security surveillance beneficial to our physical-world life. Code has been made publicly available.