 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D Point Cloud Generation via Autoregressive Up-sampling
Mar 11, 2025We introduce a pioneering autoregressive generative model for 3D point cloud generation. Inspired by visual autoregressive modeling (VAR), we conceptualize point cloud generation as an autoregressive up-sampling process. This leads to our novel model, PointARU, which progressively refines 3D point clouds from coarse to fine scales. PointARU follows a two-stage training paradigm: first, it learns multi-scale discrete representations of point clouds, and then it trains an autoregressive transformer for next-scale prediction. To address the inherent unordered and irregular structure of point clouds, we incorporate specialized point-based up-sampling network modules in both stages and integrate 3D absolute positional encoding based on the decoded point cloud at each scale during the second stage. Our model surpasses state-of-the-art (SoTA) diffusion-based approaches in both generation quality and parameter efficiency across diverse experimental settings, marking a new milestone for autoregressive methods in 3D point cloud generation. Furthermore, PointARU demonstrates exceptional performance in completing partial 3D shapes and up-sampling sparse point clouds, outperforming existing generative models in these tasks.
Continual Optimization with Symmetry Teleportation for Multi-Task Learning
Mar 06, 2025



Multi-task learning (MTL) is a widely explored paradigm that enables the simultaneous learning of multiple tasks using a single model. Despite numerous solutions, the key issues of optimization conflict and task imbalance remain under-addressed, limiting performance. Unlike existing optimization-based approaches that typically reweight task losses or gradients to mitigate conflicts or promote progress, we propose a novel approach based on Continual Optimization with Symmetry Teleportation (COST). During MTL optimization, when an optimization conflict arises, we seek an alternative loss-equivalent point on the loss landscape to reduce conflict. Specifically, we utilize a low-rank adapter (LoRA) to facilitate this practical teleportation by designing convergent, loss-invariant objectives. Additionally, we introduce a historical trajectory reuse strategy to continually leverage the benefits of advanced optimizers. Extensive experiments on multiple mainstream datasets demonstrate the effectiveness of our approach. COST is a plug-and-play solution that enhances a wide range of existing MTL methods. When integrated with state-of-the-art methods, COST achieves superior performance.
VoxEval: Benchmarking the Knowledge Understanding Capabilities of End-to-End Spoken Language Models
Jan 09, 2025



With the growing demand for developing speech-based interaction models, end-to-end Spoken Language Models (SLMs) have emerged as a promising solution. When engaging in conversations with humans, it is essential for these models to comprehend a wide range of world knowledge. In this paper, we introduce VoxEval, a novel speech question-answering benchmark specifically designed to assess SLMs' knowledge understanding through purely speech-based interactions. Unlike existing AudioQA benchmarks, VoxEval maintains speech format for both questions and answers, evaluates model robustness across diverse audio conditions (varying timbres, audio qualities, and speaking styles), and pioneers the assessment of challenging domains like mathematical problem-solving in spoken format. Our comprehensive evaluation of recent SLMs using VoxEval reveals significant performance limitations in current models, highlighting crucial areas for future improvements.
Recent Advances in Speech Language Models: A Survey
Oct 01, 2024



Large Language Models (LLMs) have recently garnered significant attention, primarily for their capabilities in text-based interactions. However, natural human interaction often relies on speech, necessitating a shift towards voice-based models. A straightforward approach to achieve this involves a pipeline of ``Automatic Speech Recognition (ASR) + LLM + Text-to-Speech (TTS)", where input speech is transcribed to text, processed by an LLM, and then converted back to speech. Despite being straightforward, this method suffers from inherent limitations, such as information loss during modality conversion and error accumulation across the three stages. To address these issues, Speech Language Models (SpeechLMs) -- end-to-end models that generate speech without converting from text -- have emerged as a promising alternative. This survey paper provides the first comprehensive overview of recent methodologies for constructing SpeechLMs, detailing the key components of their architecture and the various training recipes integral to their development. Additionally, we systematically survey the various capabilities of SpeechLMs, categorize the evaluation metrics for SpeechLMs, and discuss the challenges and future research directions in this rapidly evolving field.
Step-On-Feet Tuning: Scaling Self-Alignment of LLMs via Bootstrapping
Feb 22, 2024Self-alignment is an effective way to reduce the cost of human annotation while ensuring promising model capability. However, most current methods complete the data collection and training steps in a single round, which may overlook the continuously improving ability of self-aligned models. This gives rise to a key query: What if we do multi-time bootstrapping self-alignment? Does this strategy enhance model performance or lead to rapid degradation? In this paper, our pioneering exploration delves into the impact of bootstrapping self-alignment on large language models. Our findings reveal that bootstrapping self-alignment markedly surpasses the single-round approach, by guaranteeing data diversity from in-context learning. To further exploit the capabilities of bootstrapping, we investigate and adjust the training order of data, which yields improved performance of the model. Drawing on these findings, we propose Step-On-Feet Tuning (SOFT) which leverages model's continuously enhanced few-shot ability to boost zero or one-shot performance. Based on easy-to-hard training recipe, we propose SOFT+ which further boost self-alignment's performance. Our experiments demonstrate the efficiency of SOFT (SOFT+) across various classification and generation tasks, highlighting the potential of bootstrapping self-alignment on continually enhancing model alignment performance.
A Unified View of Deep Learning for Reaction and Retrosynthesis Prediction: Current Status and Future Challenges
Jun 28, 2023Reaction and retrosynthesis prediction are fundamental tasks in computational chemistry that have recently garnered attention from both the machine learning and drug discovery communities. Various deep learning approaches have been proposed to tackle these problems, and some have achieved initial success. In this survey, we conduct a comprehensive investigation of advanced deep learning-based models for reaction and retrosynthesis prediction. We summarize the design mechanisms, strengths, and weaknesses of state-of-the-art approaches. Then, we discuss the limitations of current solutions and open challenges in the problem itself. Finally, we present promising directions to facilitate future research. To our knowledge, this paper is the first comprehensive and systematic survey that seeks to provide a unified understanding of reaction and retrosynthesis prediction.
Doubly Stochastic Graph-based Non-autoregressive Reaction Prediction
Jun 05, 2023Organic reaction prediction is a critical task in drug discovery. Recently, researchers have achieved non-autoregressive reaction prediction by modeling the redistribution of electrons, resulting in state-of-the-art top-1 accuracy, and enabling parallel sampling. However, the current non-autoregressive decoder does not satisfy two essential rules of electron redistribution modeling simultaneously: the electron-counting rule and the symmetry rule. This violation of the physical constraints of chemical reactions impairs model performance. In this work, we propose a new framework called that combines two doubly stochastic self-attention mappings to obtain electron redistribution predictions that follow both constraints. We further extend our solution to a general multi-head attention mechanism with augmented constraints. To achieve this, we apply Sinkhorn's algorithm to iteratively update self-attention mappings, which imposes doubly conservative constraints as additional informative priors on electron redistribution modeling. We theoretically demonstrate that our can simultaneously satisfy both rules, which the current decoder mechanism cannot do. Empirical results show that our approach consistently improves the predictive performance of non-autoregressive models and does not bring an unbearable additional computational cost.
Graph-adaptive Rectified Linear Unit for Graph Neural Networks
Feb 13, 2022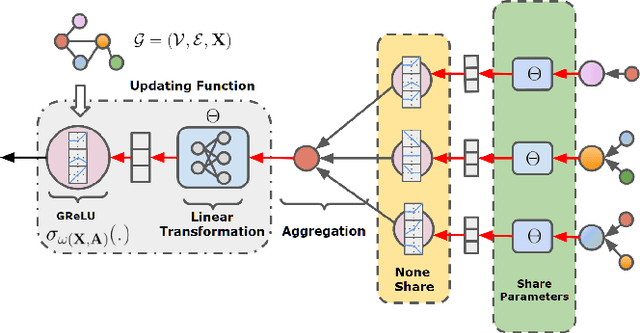

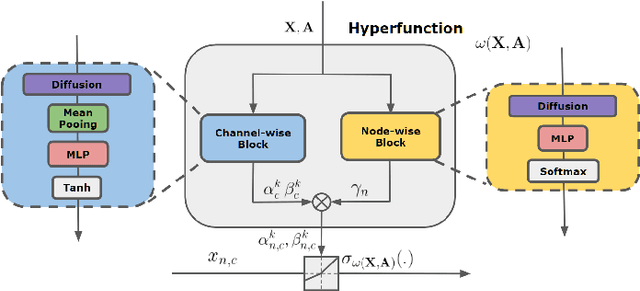
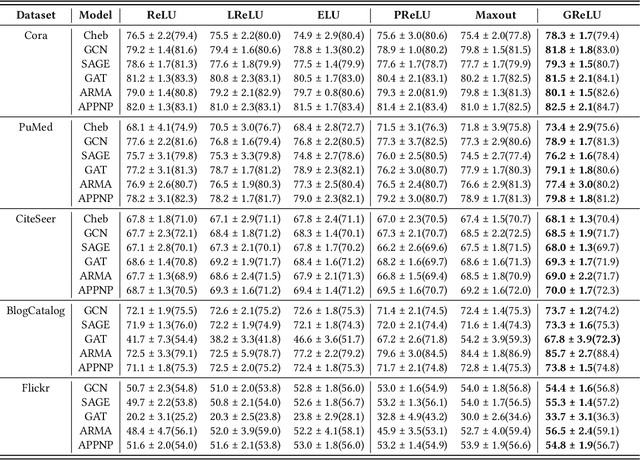
Graph Neural Networks (GNNs) have achieved remarkable success by extending traditional convolution to learning on non-Euclidean data. The key to the GNNs is adopting the neural message-passing paradigm with two stages: aggregation and update. The current design of GNNs considers the topology information in the aggregation stage. However, in the updating stage, all nodes share the same updating function. The identical updating function treats each node embedding as i.i.d. random variables and thus ignores the implicit relationships between neighborhoods, which limits the capacity of the GNNs. The updating function is usually implemented with a linear transformation followed by a non-linear activation function. To make the updating function topology-aware, we inject the topological information into the non-linear activation function and propose Graph-adaptive Rectified Linear Unit (GReLU), which is a new parametric activation function incorporating the neighborhood information in a novel and efficient way. The parameters of GReLU are obtained from a hyperfunction based on both node features and the corresponding adjacent matrix. To reduce the risk of overfitting and the computational cost, we decompose the hyperfunction as two independent components for nodes and features respectively. We conduct comprehensive experiments to show that our plug-and-play GReLU method is efficient and effective given different GNN backbones and various downstream tasks.
Modeling Scale-free Graphs for Knowledge-aware Recommendation
Aug 14, 2021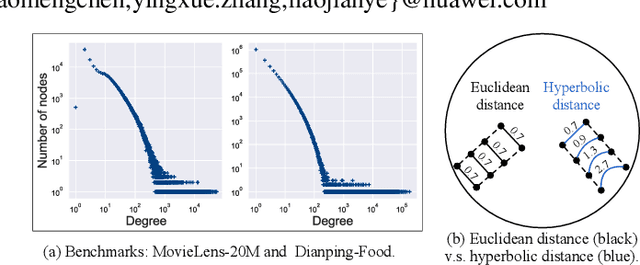
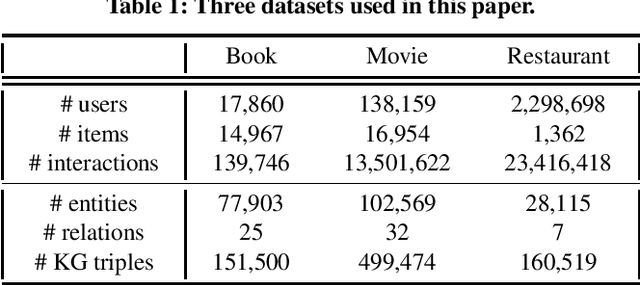
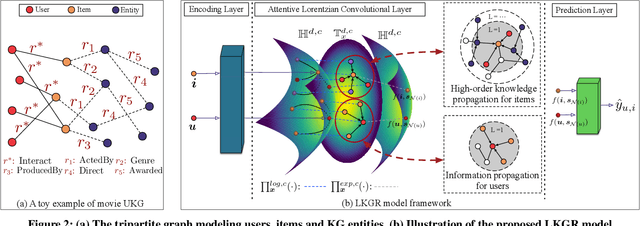
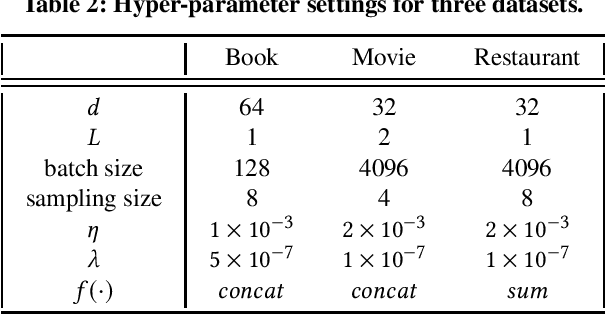
Aiming to alleviate data sparsity and cold-start problems of traditional recommender systems, incorporating knowledge graphs (KGs) to supplement auxiliary information has recently gained considerable attention. Via unifying the KG with user-item interactions into a tripartite graph, recent works explore the graph topologies to learn the low-dimensional representations of users and items with rich semantics. However, these real-world tripartite graphs are usually scale-free, the intrinsic hierarchical graph structures of which are underemphasized in existing works, consequently, leading to suboptimal recommendation performance. To address this issue and provide more accurate recommendation, we propose a knowledge-aware recommendation method with the hyperbolic geometry, namely Lorentzian Knowledge-enhanced Graph convolutional networks for Recommendation (LKGR). LKGR facilitates better modeling of scale-free tripartite graphs after the data unification. Specifically, we employ different information propagation strategies in the hyperbolic space to explicitly encode heterogeneous information from historical interactions and KGs. Our proposed knowledge-aware attention mechanism enables the model to automatically measure the information contribution, producing the coherent information aggregation in the hyperbolic space. Extensive experiments on three real-world benchmarks demonstrate that LKGR outperforms state-of-the-art methods by 2.2-29.9% of Recall@20 on Top-K recommendation.
FeatureNorm: L2 Feature Normalization for Dynamic Graph Embedding
Feb 27, 2021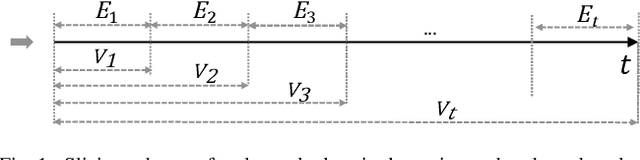
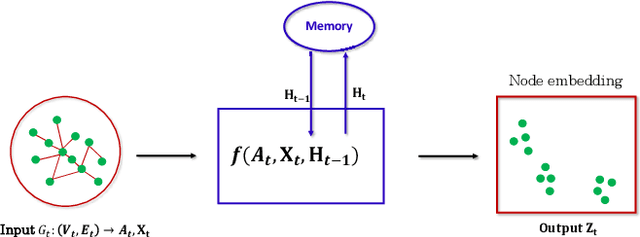
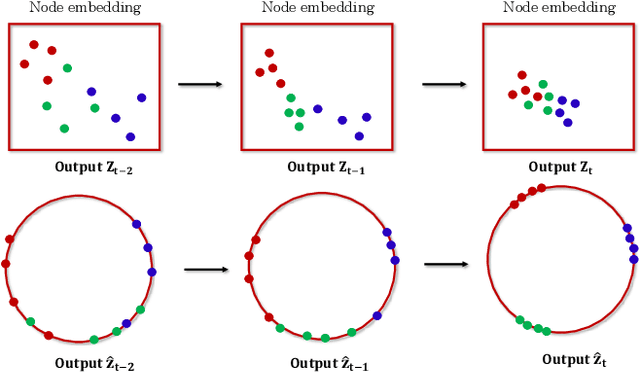
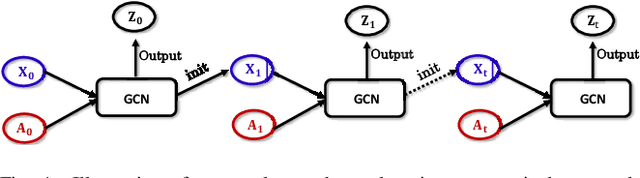
Dynamic graphs arise in a plethora of practical scenarios such as social networks, communication networks, and financial transaction networks. Given a dynamic graph, it is fundamental and essential to learn a graph representation that is expected not only to preserve structural proximity but also jointly capture the time-evolving patterns. Recently, graph convolutional network (GCN) has been widely explored and used in non-Euclidean application domains. The main success of GCN, especially in handling dependencies and passing messages within nodes, lies in its approximation to Laplacian smoothing. As a matter of fact, this smoothing technique can not only encourage must-link node pairs to get closer but also push cannot-link pairs to shrink together, which potentially cause serious feature shrink or oversmoothing problem, especially when stacking graph convolution in multiple layers or steps. For learning time-evolving patterns, a natural solution is to preserve historical state and combine it with the current interactions to obtain the most recent representation. Then the serious feature shrink or oversmoothing problem could happen when stacking graph convolution explicitly or implicitly according to current prevalent methods, which would make nodes too similar to distinguish each other. To solve this problem in dynamic graph embedding, we analyze the shrinking properties in the node embedding space at first, and then design a simple yet versatile method, which exploits L2 feature normalization constraint to rescale all nodes to hypersphere of a unit ball so that nodes would not shrink together, and yet similar nodes can still get closer. Extensive experiments on four real-world dynamic graph datasets compared with competitive baseline models demonstrate the effectiveness of the proposed method.