 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Mixture of Latent Memories for Self-Evolving Agents
May 21, 2026Achieving self-evolution in intelligent agents requires the continual accumulation of new knowledge across changing task sequences without forgetting previously acquired abilities. Existing approaches either internalize knowledge by updating model parameters, which induces catastrophic forgetting, or rely on external memory, which fails to genuinely enhance the model's intrinsic capabilities. We propose MoLEM, a generative mixture of latent memory framework based on a dynamic mixture-of-experts (MoE). We treat multiple experts as independent carriers to generate memory. A router selects and weights experts through key-query matching, and the aggregated latent memory is injected into the reasoning process. The base model for reasoning remains entirely frozen, with all experiential knowledge internalized into the additional modules, avoiding catastrophic forgetting. For continual learning, each training stage is paired with a lightweight autoencoder that selects the appropriate routing group at inference, and inputs that match no stage fall back to the pretrained model. Experiments train the framework on continual-learning sequences spanning math, science, and code domains. After training, we evaluate the framework on the corresponding test sets to measure task learning and competence preservation across continual adaptation stages. After the full continual-learning sequence, our method improves the average accuracy by 10.40% over the Vanilla pretrained baseline, while none of the competing methods consistently exceed this baseline across different training orders.
ConSurv: Multimodal Continual Learning for Survival Analysis
Nov 13, 2025Survival prediction of cancers is crucial for clinical practice, as it informs mortality risks and influences treatment plans. However, a static model trained on a single dataset fails to adapt to the dynamically evolving clinical environment and continuous data streams, limiting its practical utility. While continual learning (CL) offers a solution to learn dynamically from new datasets, existing CL methods primarily focus on unimodal inputs and suffer from severe catastrophic forgetting in survival prediction. In real-world scenarios, multimodal inputs often provide comprehensive and complementary information, such as whole slide images and genomics; and neglecting inter-modal correlations negatively impacts the performance. To address the two challenges of catastrophic forgetting and complex inter-modal interactions between gigapixel whole slide images and genomics, we propose ConSurv, the first multimodal continual learning (MMCL) method for survival analysis. ConSurv incorporates two key components: Multi-staged Mixture of Experts (MS-MoE) and Feature Constrained Replay (FCR). MS-MoE captures both task-shared and task-specific knowledge at different learning stages of the network, including two modality encoders and the modality fusion component, learning inter-modal relationships. FCR further enhances learned knowledge and mitigates forgetting by restricting feature deviation of previous data at different levels, including encoder-level features of two modalities and the fusion-level representations. Additionally, we introduce a new benchmark integrating four datasets, Multimodal Survival Analysis Incremental Learning (MSAIL), for comprehensive evaluation in the CL setting. Extensive experiments demonstrate that ConSurv outperforms competing methods across multiple metrics.
Recent Advances of Multimodal Continual Learning: A Comprehensive Survey
Oct 07, 2024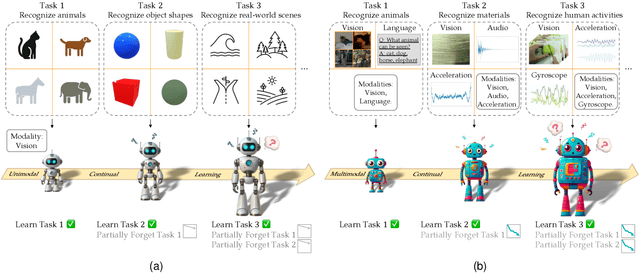
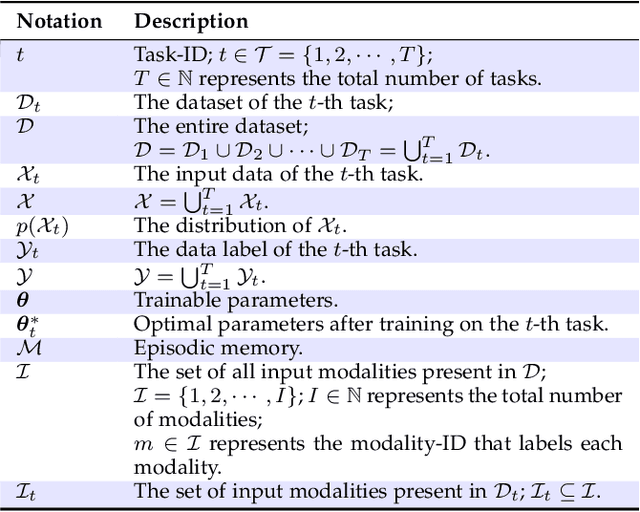
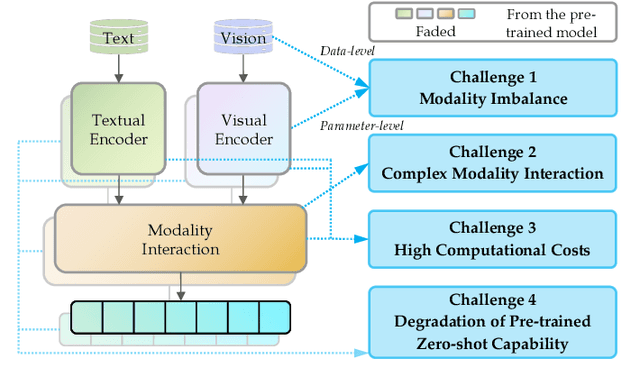
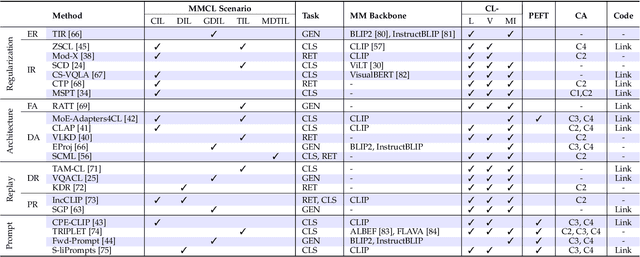
Continual learning (CL) aims to empower machine learning models to learn continually from new data, while building upon previously acquired knowledge without forgetting. As machine learning models have evolved from small to large pre-trained architectures, and from supporting unimodal to multimodal data, multimodal continual learning (MMCL) methods have recently emerged. The primary challenge of MMCL is that it goes beyond a simple stacking of unimodal CL methods, as such straightforward approaches often yield unsatisfactory performance. In this work, we present the first comprehensive survey on MMCL. We provide essential background knowledge and MMCL settings, as well as a structured taxonomy of MMCL methods. We categorize existing MMCL methods into four categories, i.e., regularization-based, architecture-based, replay-based, and prompt-based methods, explaining their methodologies and highlighting their key innovations. Additionally, to prompt further research in this field, we summarize open MMCL datasets and benchmarks, and discuss several promising future directions for investigation and development. We have also created a GitHub repository for indexing relevant MMCL papers and open resources available at https://github.com/LucyDYu/Awesome-Multimodal-Continual-Learning.
Recent Advances in Speech Language Models: A Survey
Oct 01, 2024



Large Language Models (LLMs) have recently garnered significant attention, primarily for their capabilities in text-based interactions. However, natural human interaction often relies on speech, necessitating a shift towards voice-based models. A straightforward approach to achieve this involves a pipeline of ``Automatic Speech Recognition (ASR) + LLM + Text-to-Speech (TTS)", where input speech is transcribed to text, processed by an LLM, and then converted back to speech. Despite being straightforward, this method suffers from inherent limitations, such as information loss during modality conversion and error accumulation across the three stages. To address these issues, Speech Language Models (SpeechLMs) -- end-to-end models that generate speech without converting from text -- have emerged as a promising alternative. This survey paper provides the first comprehensive overview of recent methodologies for constructing SpeechLMs, detailing the key components of their architecture and the various training recipes integral to their development. Additionally, we systematically survey the various capabilities of SpeechLMs, categorize the evaluation metrics for SpeechLMs, and discuss the challenges and future research directions in this rapidly evolving field.
An Entropy-based Text Watermarking Detection Method
Mar 20, 2024Currently, text watermarking algorithms for large language models (LLMs) can embed hidden features to texts generated by LLMs to facilitate subsequent detection, thus alleviating the problem of misuse of LLMs. Although the current text watermarking algorithms perform well in most high-entropy scenarios, its performance in low-entropy scenarios still needs to be improved. In this work, we proposed that the influence of token entropy should be fully considered in the watermark detection process, that is, the weight of each token should be adjusted according to its entropy during watermark detection, rather than setting the weight of all tokens to the same value as in previous methods. Specifically, we proposed an Entropy-based Watermark Detection (EWD) that gives higher-entropy tokens higher weights during watermark detection, so as to better reflect the degree of watermarking. Furthermore, the proposed detection process is training-free and fully automated. %In actual detection, we use a proxy-LLM to calculate the entropy of each token, without the need to use the original LLM. In the experiment, we found that our method can achieve better detection performance in low-entropy scenarios, and our method is also general and can be applied to texts with different entropy distributions. Our code and data will be available online.