 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConSurv: Multimodal Continual Learning for Survival Analysis
Nov 13, 2025Survival prediction of cancers is crucial for clinical practice, as it informs mortality risks and influences treatment plans. However, a static model trained on a single dataset fails to adapt to the dynamically evolving clinical environment and continuous data streams, limiting its practical utility. While continual learning (CL) offers a solution to learn dynamically from new datasets, existing CL methods primarily focus on unimodal inputs and suffer from severe catastrophic forgetting in survival prediction. In real-world scenarios, multimodal inputs often provide comprehensive and complementary information, such as whole slide images and genomics; and neglecting inter-modal correlations negatively impacts the performance. To address the two challenges of catastrophic forgetting and complex inter-modal interactions between gigapixel whole slide images and genomics, we propose ConSurv, the first multimodal continual learning (MMCL) method for survival analysis. ConSurv incorporates two key components: Multi-staged Mixture of Experts (MS-MoE) and Feature Constrained Replay (FCR). MS-MoE captures both task-shared and task-specific knowledge at different learning stages of the network, including two modality encoders and the modality fusion component, learning inter-modal relationships. FCR further enhances learned knowledge and mitigates forgetting by restricting feature deviation of previous data at different levels, including encoder-level features of two modalities and the fusion-level representations. Additionally, we introduce a new benchmark integrating four datasets, Multimodal Survival Analysis Incremental Learning (MSAIL), for comprehensive evaluation in the CL setting. Extensive experiments demonstrate that ConSurv outperforms competing methods across multiple metrics.
G-Refer: Graph Retrieval-Augmented Large Language Model for Explainable Recommendation
Feb 18, 2025Explainable recommendation has demonstrated significant advantages in informing users about the logic behind recommendations, thereby increasing system transparency, effectiveness, and trustworthiness. To provide personalized and interpretable explanations, existing works often combine the generation capabilities of large language models (LLMs) with collaborative filtering (CF) information. CF information extracted from the user-item interaction graph captures the user behaviors and preferences, which is crucial for providing informative explanations. However, due to the complexity of graph structure, effectively extracting the CF information from graphs still remains a challenge. Moreover, existing methods often struggle with the integration of extracted CF information with LLMs due to its implicit representation and the modality gap between graph structures and natural language explanations. To address these challenges, we propose G-Refer, a framework using graph retrieval-augmented large language models (LLMs) for explainable recommendation. Specifically, we first employ a hybrid graph retrieval mechanism to retrieve explicit CF signals from both structural and semantic perspectives. The retrieved CF information is explicitly formulated as human-understandable text by the proposed graph translation and accounts for the explanations generated by LLMs. To bridge the modality gap, we introduce knowledge pruning and retrieval-augmented fine-tuning to enhance the ability of LLMs to process and utilize the retrieved CF information to generate explanations. Extensive experiments show that G-Refer achieves superior performance compared with existing methods in both explainability and stability. Codes and data are available at https://github.com/Yuhan1i/G-Refer.
Recent Advances of Multimodal Continual Learning: A Comprehensive Survey
Oct 07, 2024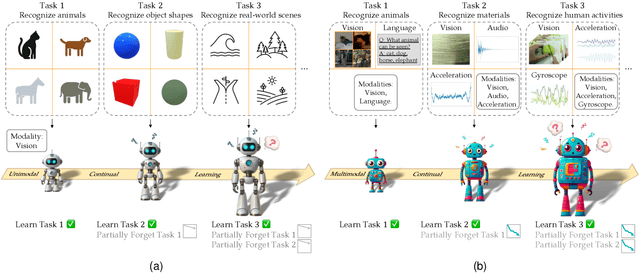
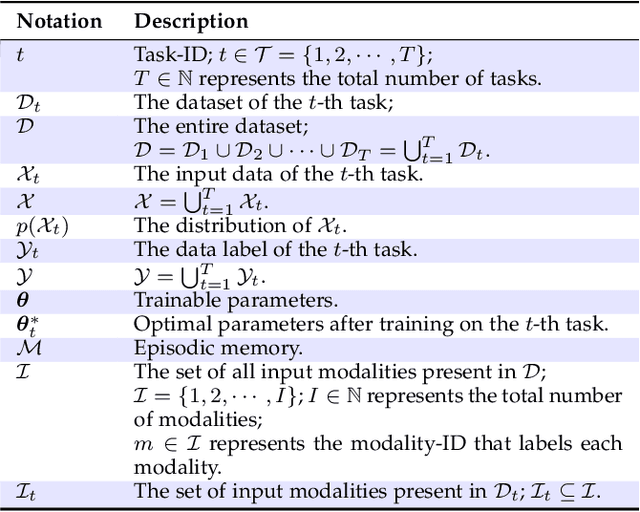
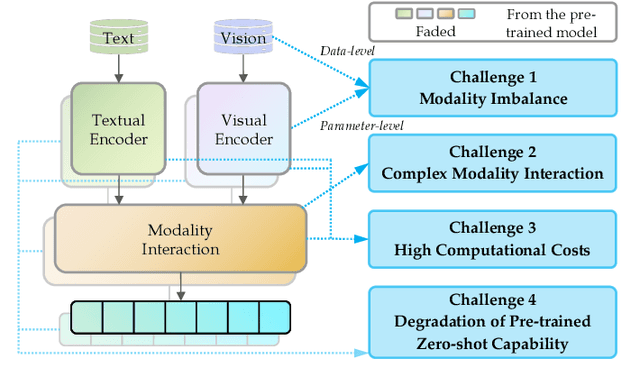
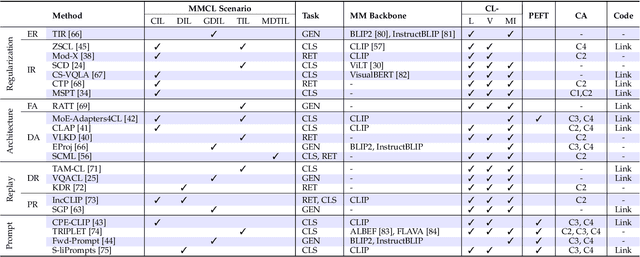
Continual learning (CL) aims to empower machine learning models to learn continually from new data, while building upon previously acquired knowledge without forgetting. As machine learning models have evolved from small to large pre-trained architectures, and from supporting unimodal to multimodal data, multimodal continual learning (MMCL) methods have recently emerged. The primary challenge of MMCL is that it goes beyond a simple stacking of unimodal CL methods, as such straightforward approaches often yield unsatisfactory performance. In this work, we present the first comprehensive survey on MMCL. We provide essential background knowledge and MMCL settings, as well as a structured taxonomy of MMCL methods. We categorize existing MMCL methods into four categories, i.e., regularization-based, architecture-based, replay-based, and prompt-based methods, explaining their methodologies and highlighting their key innovations. Additionally, to prompt further research in this field, we summarize open MMCL datasets and benchmarks, and discuss several promising future directions for investigation and development. We have also created a GitHub repository for indexing relevant MMCL papers and open resources available at https://github.com/LucyDYu/Awesome-Multimodal-Continual-Learning.
Knowledge-aware Neural Networks with Personalized Feature Referencing for Cold-start Recommendation
Sep 28, 2022



Incorporating knowledge graphs (KGs) as side information in recommendation has recently attracted considerable attention. Despite the success in general recommendation scenarios, prior methods may fall short of performance satisfaction for the cold-start problem in which users are associated with very limited interactive information. Since the conventional methods rely on exploring the interaction topology, they may however fail to capture sufficient information in cold-start scenarios. To mitigate the problem, we propose a novel Knowledge-aware Neural Networks with Personalized Feature Referencing Mechanism, namely KPER. Different from most prior methods which simply enrich the targets' semantics from KGs, e.g., product attributes, KPER utilizes the KGs as a "semantic bridge" to extract feature references for cold-start users or items. Specifically, given cold-start targets, KPER first probes semantically relevant but not necessarily structurally close users or items as adaptive seeds for referencing features. Then a Gated Information Aggregation module is introduced to learn the combinatorial latent features for cold-start users and items. Our extensive experiments over four real-world datasets show that, KPER consistently outperforms all competing methods in cold-start scenarios, whilst maintaining superiority in general scenarios without compromising overall performance, e.g., by achieving 0.81%-16.08% and 1.01%-14.49% performance improvement across all datasets in Top-10 recommendation.
DAGNN: Demand-aware Graph Neural Networks for Session-based Recommendation
May 30, 2021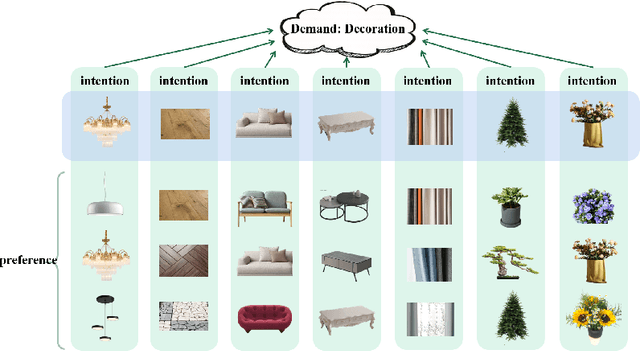



Session-based recommendations have been widely adopted for various online video and E-commerce Websites. Most existing approaches are intuitively proposed to discover underlying interests or preferences out of the anonymous session data. This apparently ignores the fact these sequential behaviors usually reflect session user's potential demand, i.e., a semantic level factor, and therefore how to estimate underlying demands from a session is challenging. To address aforementioned issue, this paper proposes a demand-aware graph neural networks (DAGNN). Particularly, a demand modeling component is designed to first extract session demand and the underlying multiple demands of each session is estimated using the global demand matrix. Then, the demand-aware graph neural network is designed to extract session demand graph to learn the demand-aware item embedddings for the later recommendations. The mutual information loss is further designed to enhance the quality of the learnt embeddings. Extensive experiments are evaluated on several real-world datasets and the proposed model achieves the SOTA model performance.
Probing Negative Sampling Strategies to Learn GraphRepresentations via Unsupervised Contrastive Learning
Apr 13, 2021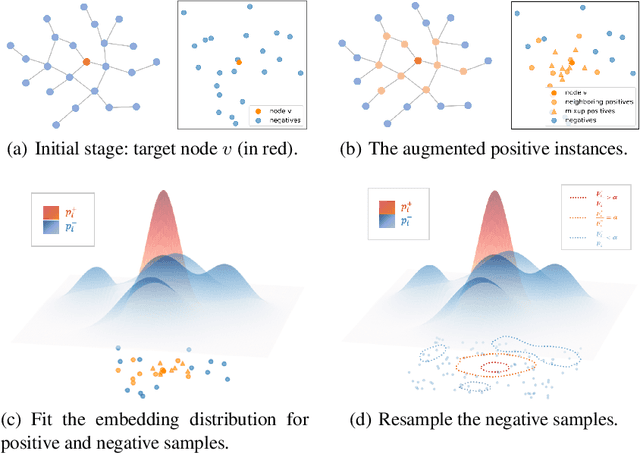

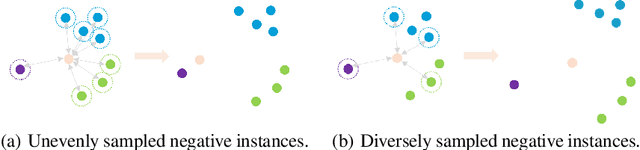
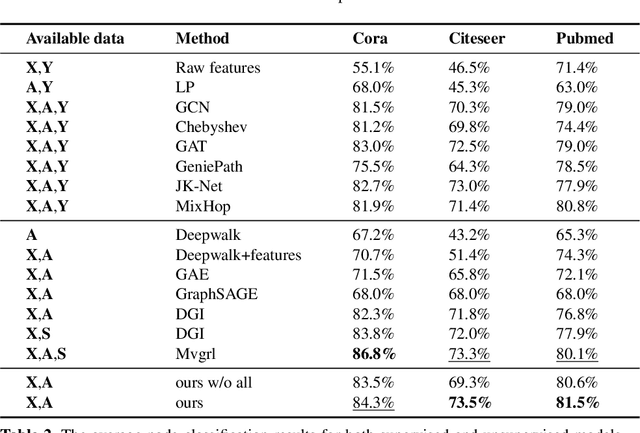
Graph representation learning has long been an important yet challenging task for various real-world applications. However, their downstream tasks are mainly performed in the settings of supervised or semi-supervised learning. Inspired by recent advances in unsupervised contrastive learning, this paper is thus motivated to investigate how the node-wise contrastive learning could be performed. Particularly, we respectively resolve the class collision issue and the imbalanced negative data distribution issue. Extensive experiments are performed on three real-world datasets and the proposed approach achieves the SOTA model performance.