 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLoTA-QAF: Lossless Ternary Adaptation for Quantization-Aware Fine-Tuning
May 24, 2025Quantization and fine-tuning are crucial for deploying large language models (LLMs) on resource-constrained edge devices. However, fine-tuning quantized models presents significant challenges, primarily stemming from: First, the mismatch in data types between the low-precision quantized weights (e.g., 4-bit) and the high-precision adaptation weights (e.g., 16-bit). This mismatch limits the computational efficiency advantage offered by quantized weights during inference. Second, potential accuracy degradation when merging these high-precision adaptation weights into the low-precision quantized weights, as the adaptation weights often necessitate approximation or truncation. Third, as far as we know, no existing methods support the lossless merging of adaptation while adjusting all quantized weights. To address these challenges, we introduce lossless ternary adaptation for quantization-aware fine-tuning (LoTA-QAF). This is a novel fine-tuning method specifically designed for quantized LLMs, enabling the lossless merging of ternary adaptation weights into quantized weights and the adjustment of all quantized weights. LoTA-QAF operates through a combination of: i) A custom-designed ternary adaptation (TA) that aligns ternary weights with the quantization grid and uses these ternary weights to adjust quantized weights. ii) A TA-based mechanism that enables the lossless merging of adaptation weights. iii) Ternary signed gradient descent (t-SignSGD) for updating the TA weights. We apply LoTA-QAF to Llama-3.1/3.3 and Qwen-2.5 model families and validate its effectiveness on several downstream tasks. On the MMLU benchmark, our method effectively recovers performance for quantized models, surpassing 16-bit LoRA by up to 5.14\%. For task-specific fine-tuning, 16-bit LoRA achieves superior results, but LoTA-QAF still outperforms other methods.
Siamese Foundation Models for Crystal Structure Prediction
Mar 13, 2025



Crystal Structure Prediction (CSP), which aims to generate stable crystal structures from compositions, represents a critical pathway for discovering novel materials. While structure prediction tasks in other domains, such as proteins, have seen remarkable progress, CSP remains a relatively underexplored area due to the more complex geometries inherent in crystal structures. In this paper, we propose Siamese foundation models specifically designed to address CSP. Our pretrain-finetune framework, named DAO, comprises two complementary foundation models: DAO-G for structure generation and DAO-P for energy prediction. Experiments on CSP benchmarks (MP-20 and MPTS-52) demonstrate that our DAO-G significantly surpasses state-of-the-art (SOTA) methods across all metrics. Extensive ablation studies further confirm that DAO-G excels in generating diverse polymorphic structures, and the dataset relaxation and energy guidance provided by DAO-P are essential for enhancing DAO-G's performance. When applied to three real-world superconductors ($\text{CsV}_3\text{Sb}_5$, $ \text{Zr}_{16}\text{Rh}_8\text{O}_4$ and $\text{Zr}_{16}\text{Pd}_8\text{O}_4$) that are known to be challenging to analyze, our foundation models achieve accurate critical temperature predictions and structure generations. For instance, on $\text{CsV}_3\text{Sb}_5$, DAO-G generates a structure close to the experimental one with an RMSE of 0.0085; DAO-P predicts the $T_c$ value with high accuracy (2.26 K vs. the ground-truth value of 2.30 K). In contrast, conventional DFT calculators like Quantum Espresso only successfully derive the structure of the first superconductor within an acceptable time, while the RMSE is nearly 8 times larger, and the computation speed is more than 1000 times slower. These compelling results collectively highlight the potential of our approach for advancing materials science research and development.
G-Refer: Graph Retrieval-Augmented Large Language Model for Explainable Recommendation
Feb 18, 2025Explainable recommendation has demonstrated significant advantages in informing users about the logic behind recommendations, thereby increasing system transparency, effectiveness, and trustworthiness. To provide personalized and interpretable explanations, existing works often combine the generation capabilities of large language models (LLMs) with collaborative filtering (CF) information. CF information extracted from the user-item interaction graph captures the user behaviors and preferences, which is crucial for providing informative explanations. However, due to the complexity of graph structure, effectively extracting the CF information from graphs still remains a challenge. Moreover, existing methods often struggle with the integration of extracted CF information with LLMs due to its implicit representation and the modality gap between graph structures and natural language explanations. To address these challenges, we propose G-Refer, a framework using graph retrieval-augmented large language models (LLMs) for explainable recommendation. Specifically, we first employ a hybrid graph retrieval mechanism to retrieve explicit CF signals from both structural and semantic perspectives. The retrieved CF information is explicitly formulated as human-understandable text by the proposed graph translation and accounts for the explanations generated by LLMs. To bridge the modality gap, we introduce knowledge pruning and retrieval-augmented fine-tuning to enhance the ability of LLMs to process and utilize the retrieved CF information to generate explanations. Extensive experiments show that G-Refer achieves superior performance compared with existing methods in both explainability and stability. Codes and data are available at https://github.com/Yuhan1i/G-Refer.
GDiffRetro: Retrosynthesis Prediction with Dual Graph Enhanced Molecular Representation and Diffusion Generation
Jan 14, 2025



Retrosynthesis prediction focuses on identifying reactants capable of synthesizing a target product. Typically, the retrosynthesis prediction involves two phases: Reaction Center Identification and Reactant Generation. However, we argue that most existing methods suffer from two limitations in the two phases: (i) Existing models do not adequately capture the ``face'' information in molecular graphs for the reaction center identification. (ii) Current approaches for the reactant generation predominantly use sequence generation in a 2D space, which lacks versatility in generating reasonable distributions for completed reactive groups and overlooks molecules' inherent 3D properties. To overcome the above limitations, we propose GDiffRetro. For the reaction center identification, GDiffRetro uniquely integrates the original graph with its corresponding dual graph to represent molecular structures, which helps guide the model to focus more on the faces in the graph. For the reactant generation, GDiffRetro employs a conditional diffusion model in 3D to further transform the obtained synthon into a complete reactant. Our experimental findings reveal that GDiffRetro outperforms state-of-the-art semi-template models across various evaluative metrics.
Are High-Degree Representations Really Unnecessary in Equivariant Graph Neural Networks?
Oct 15, 2024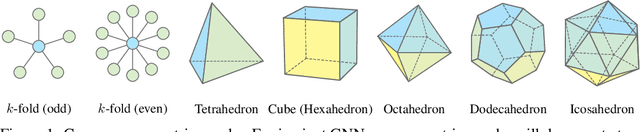
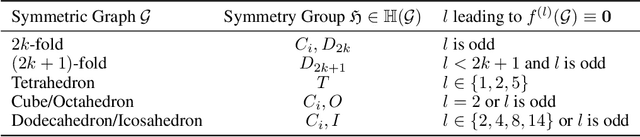
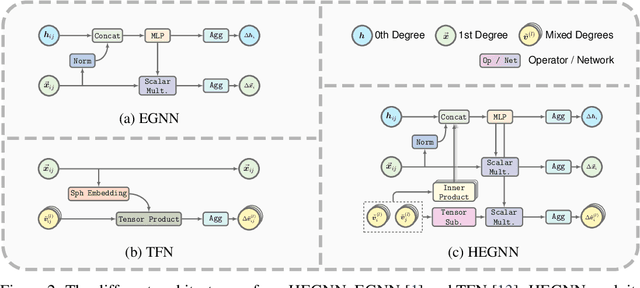
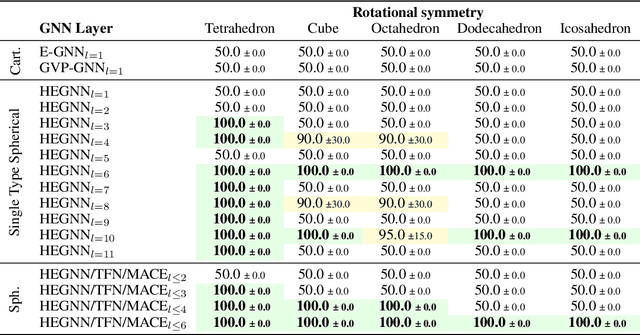
Equivariant Graph Neural Networks (GNNs) that incorporate E(3) symmetry have achieved significant success in various scientific applications. As one of the most successful models, EGNN leverages a simple scalarization technique to perform equivariant message passing over only Cartesian vectors (i.e., 1st-degree steerable vectors), enjoying greater efficiency and efficacy compared to equivariant GNNs using higher-degree steerable vectors. This success suggests that higher-degree representations might be unnecessary. In this paper, we disprove this hypothesis by exploring the expressivity of equivariant GNNs on symmetric structures, including $k$-fold rotations and regular polyhedra. We theoretically demonstrate that equivariant GNNs will always degenerate to a zero function if the degree of the output representations is fixed to 1 or other specific values. Based on this theoretical insight, we propose HEGNN, a high-degree version of EGNN to increase the expressivity by incorporating high-degree steerable vectors while maintaining EGNN's efficiency through the scalarization trick. Our extensive experiments demonstrate that HEGNN not only aligns with our theoretical analyses on toy datasets consisting of symmetric structures, but also shows substantial improvements on more complicated datasets such as $N$-body and MD17. Our theoretical findings and empirical results potentially open up new possibilities for the research of equivariant GNNs.
Molecular Graph Representation Learning Integrating Large Language Models with Domain-specific Small Models
Aug 19, 2024



Molecular property prediction is a crucial foundation for drug discovery. In recent years, pre-trained deep learning models have been widely applied to this task. Some approaches that incorporate prior biological domain knowledge into the pre-training framework have achieved impressive results. However, these methods heavily rely on biochemical experts, and retrieving and summarizing vast amounts of domain knowledge literature is both time-consuming and expensive. Large Language Models (LLMs) have demonstrated remarkable performance in understanding and efficiently providing general knowledge. Nevertheless, they occasionally exhibit hallucinations and lack precision in generating domain-specific knowledge. Conversely, Domain-specific Small Models (DSMs) possess rich domain knowledge and can accurately calculate molecular domain-related metrics. However, due to their limited model size and singular functionality, they lack the breadth of knowledge necessary for comprehensive representation learning. To leverage the advantages of both approaches in molecular property prediction, we propose a novel Molecular Graph representation learning framework that integrates Large language models and Domain-specific small models (MolGraph-LarDo). Technically, we design a two-stage prompt strategy where DSMs are introduced to calibrate the knowledge provided by LLMs, enhancing the accuracy of domain-specific information and thus enabling LLMs to generate more precise textual descriptions for molecular samples. Subsequently, we employ a multi-modal alignment method to coordinate various modalities, including molecular graphs and their corresponding descriptive texts, to guide the pre-training of molecular representations. Extensive experiments demonstrate the effectiveness of the proposed method.
Characterizing the Influence of Topology on Graph Learning Tasks
Apr 11, 2024
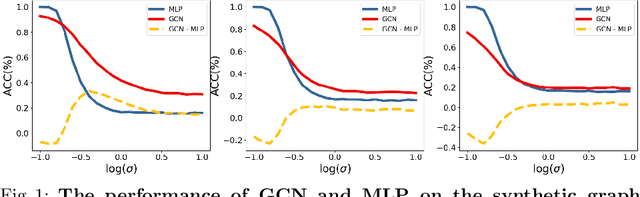
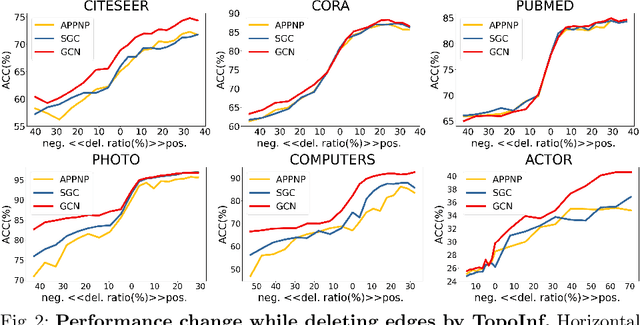
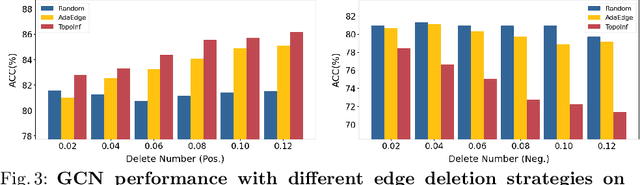
Graph neural networks (GNN) have achieved remarkable success in a wide range of tasks by encoding features combined with topology to create effective representations. However, the fundamental problem of understanding and analyzing how graph topology influences the performance of learning models on downstream tasks has not yet been well understood. In this paper, we propose a metric, TopoInf, which characterizes the influence of graph topology by measuring the level of compatibility between the topological information of graph data and downstream task objectives. We provide analysis based on the decoupled GNNs on the contextual stochastic block model to demonstrate the effectiveness of the metric. Through extensive experiments, we demonstrate that TopoInf is an effective metric for measuring topological influence on corresponding tasks and can be further leveraged to enhance graph learning.
Sculpting Molecules in 3D: A Flexible Substructure Aware Framework for Text-Oriented Molecular Optimization
Mar 06, 2024



The integration of deep learning, particularly AI-Generated Content, with high-quality data derived from ab initio calculations has emerged as a promising avenue for transforming the landscape of scientific research. However, the challenge of designing molecular drugs or materials that incorporate multi-modality prior knowledge remains a critical and complex undertaking. Specifically, achieving a practical molecular design necessitates not only meeting the diversity requirements but also addressing structural and textural constraints with various symmetries outlined by domain experts. In this article, we present an innovative approach to tackle this inverse design problem by formulating it as a multi-modality guidance generation/optimization task. Our proposed solution involves a textural-structure alignment symmetric diffusion framework for the implementation of molecular generation/optimization tasks, namely 3DToMolo. 3DToMolo aims to harmonize diverse modalities, aligning them seamlessly to produce molecular structures adhere to specified symmetric structural and textural constraints by experts in the field. Experimental trials across three guidance generation settings have shown a superior hit generation performance compared to state-of-the-art methodologies. Moreover, 3DToMolo demonstrates the capability to generate novel molecules, incorporating specified target substructures, without the need for prior knowledge. This work not only holds general significance for the advancement of deep learning methodologies but also paves the way for a transformative shift in molecular design strategies. 3DToMolo creates opportunities for a more nuanced and effective exploration of the vast chemical space, opening new frontiers in the development of molecular entities with tailored properties and functionalities.
MoD-SLAM: Monocular Dense Mapping for Unbounded 3D Scene Reconstruction
Feb 09, 2024



Neural implicit representations have recently been demonstrated in many fields including Simultaneous Localization And Mapping (SLAM). Current neural SLAM can achieve ideal results in reconstructing bounded scenes, but this relies on the input of RGB-D images. Neural-based SLAM based only on RGB images is unable to reconstruct the scale of the scene accurately, and it also suffers from scale drift due to errors accumulated during tracking. To overcome these limitations, we present MoD-SLAM, a monocular dense mapping method that allows global pose optimization and 3D reconstruction in real-time in unbounded scenes. Optimizing scene reconstruction by monocular depth estimation and using loop closure detection to update camera pose enable detailed and precise reconstruction on large scenes. Compared to previous work, our approach is more robust, scalable and versatile. Our experiments demonstrate that MoD-SLAM has more excellent mapping performance than prior neural SLAM methods, especially in large borderless scenes.
Large Language Models as Topological Structure Enhancers for Text-Attributed Graphs
Nov 24, 2023



The latest advancements in large language models (LLMs) have revolutionized the field of natural language processing (NLP). Inspired by the success of LLMs in NLP tasks, some recent work has begun investigating the potential of applying LLMs in graph learning tasks. However, most of the existing work focuses on utilizing LLMs as powerful node feature augmenters, leaving employing LLMs to enhance graph topological structures an understudied problem. In this work, we explore how to leverage the information retrieval and text generation capabilities of LLMs to refine/enhance the topological structure of text-attributed graphs (TAGs) under the node classification setting. First, we propose using LLMs to help remove unreliable edges and add reliable ones in the TAG. Specifically, we first let the LLM output the semantic similarity between node attributes through delicate prompt designs, and then perform edge deletion and edge addition based on the similarity. Second, we propose using pseudo-labels generated by the LLM to improve graph topology, that is, we introduce the pseudo-label propagation as a regularization to guide the graph neural network (GNN) in learning proper edge weights. Finally, we incorporate the two aforementioned LLM-based methods for graph topological refinement into the process of GNN training, and perform extensive experiments on four real-world datasets. The experimental results demonstrate the effectiveness of LLM-based graph topology refinement (achieving a 0.15%--2.47% performance gain on public benchmarks).