 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReVSI: Rebuilding Visual Spatial Intelligence Evaluation for Accurate Assessment of VLM 3D Reasoning
Apr 27, 2026Current evaluations of spatial intelligence can be systematically invalid under modern vision-language model (VLM) settings. First, many benchmarks derive question-answer (QA) pairs from point-cloud-based 3D annotations originally curated for traditional 3D perception. When such annotations are treated as ground truth for video-based evaluation, reconstruction and annotation artifacts can miss objects that are clearly visible in the video, mislabel object identities, or corrupt geometry-dependent answers (e.g., size), yielding incorrect or ambiguous QA pairs. Second, evaluations often assume full-scene access, while many VLMs operate on sparsely sampled frames (e.g., 16-64), making many questions effectively unanswerable under the actual model inputs. We improve evaluation validity by introducing ReVSI, a benchmark and protocol that ensures each QA pair is answerable and correct under the model's actual inputs. To this end, we re-annotate objects and geometry across 381 scenes from 5 datasets to improve data quality, and regenerate all QA pairs with rigorous bias mitigation and human verification using professional 3D annotation tools. We further enhance evaluation controllability by providing variants across multiple frame budgets (16/32/64/all) and fine-grained object visibility metadata, enabling controlled diagnostic analyses. Evaluations of general and domain-specific VLMs on ReVSI reveal systematic failure modes that are obscured by prior benchmarks, yielding a more reliable and diagnostic assessment of spatial intelligence.
CREST: Constraint-Release Execution for Multi-Robot Warehouse Shelf Rearrangement
Mar 27, 2026Double-Deck Multi-Agent Pickup and Delivery (DD-MAPD) models the multi-robot shelf rearrangement problem in automated warehouses. MAPF-DECOMP is a recent framework that first computes collision-free shelf trajectories with a MAPF solver and then assigns agents to execute them. While efficient, it enforces strict trajectory dependencies, often leading to poor execution quality due to idle agents and unnecessary shelf switching. We introduce CREST, a new execution framework that achieves more continuous shelf carrying by proactively releasing trajectory constraints during execution. Experiments on diverse warehouse layouts show that CREST consistently outperforms MAPF-DECOMP, reducing metrics related to agent travel, makespan, and shelf switching by up to 40.5\%, 33.3\%, and 44.4\%, respectively, with even greater benefits under lift/place overhead. These results underscore the importance of execution-aware constraint release for scalable warehouse rearrangement. Code and data are available at https://github.com/ChristinaTan0704/CREST.
Robust Multimodal Segmentation with Representation Regularization and Hybrid Prototype Distillation
May 19, 2025Multi-modal semantic segmentation (MMSS) faces significant challenges in real-world scenarios due to dynamic environments, sensor failures, and noise interference, creating a gap between theoretical models and practical performance. To address this, we propose a two-stage framework called RobustSeg, which enhances multi-modal robustness through two key components: the Hybrid Prototype Distillation Module (HPDM) and the Representation Regularization Module (RRM). In the first stage, RobustSeg pre-trains a multi-modal teacher model using complete modalities. In the second stage, a student model is trained with random modality dropout while learning from the teacher via HPDM and RRM. HPDM transforms features into compact prototypes, enabling cross-modal hybrid knowledge distillation and mitigating bias from missing modalities. RRM reduces representation discrepancies between the teacher and student by optimizing functional entropy through the log-Sobolev inequality. Extensive experiments on three public benchmarks demonstrate that RobustSeg outperforms previous state-of-the-art methods, achieving improvements of +2.76%, +4.56%, and +0.98%, respectively. Code is available at: https://github.com/RobustSeg/RobustSeg.
Measures of Variability for Risk-averse Policy Gradient
Apr 15, 2025Risk-averse reinforcement learning (RARL) is critical for decision-making under uncertainty, which is especially valuable in high-stake applications. However, most existing works focus on risk measures, e.g., conditional value-at-risk (CVaR), while measures of variability remain underexplored. In this paper, we comprehensively study nine common measures of variability, namely Variance, Gini Deviation, Mean Deviation, Mean-Median Deviation, Standard Deviation, Inter-Quantile Range, CVaR Deviation, Semi_Variance, and Semi_Standard Deviation. Among them, four metrics have not been previously studied in RARL. We derive policy gradient formulas for these unstudied metrics, improve gradient estimation for Gini Deviation, analyze their gradient properties, and incorporate them with the REINFORCE and PPO frameworks to penalize the dispersion of returns. Our empirical study reveals that variance-based metrics lead to unstable policy updates. In contrast, CVaR Deviation and Gini Deviation show consistent performance across different randomness and evaluation domains, achieving high returns while effectively learning risk-averse policies. Mean Deviation and Semi_Standard Deviation are also competitive across different scenarios. This work provides a comprehensive overview of variability measures in RARL, offering practical insights for risk-aware decision-making and guiding future research on risk metrics and RARL algorithms.
SEAGraph: Unveiling the Whole Story of Paper Review Comments
Dec 16, 2024



Peer review, as a cornerstone of scientific research, ensures the integrity and quality of scholarly work by providing authors with objective feedback for refinement. However, in the traditional peer review process, authors often receive vague or insufficiently detailed feedback, which provides limited assistance and leads to a more time-consuming review cycle. If authors can identify some specific weaknesses in their paper, they can not only address the reviewer's concerns but also improve their work. This raises the critical question of how to enhance authors' comprehension of review comments. In this paper, we present SEAGraph, a novel framework developed to clarify review comments by uncovering the underlying intentions behind them. We construct two types of graphs for each paper: the semantic mind graph, which captures the author's thought process, and the hierarchical background graph, which delineates the research domains related to the paper. A retrieval method is then designed to extract relevant content from both graphs, facilitating coherent explanations for the review comments. Extensive experiments show that SEAGraph excels in review comment understanding tasks, offering significant benefits to authors.
RELIEF: Reinforcement Learning Empowered Graph Feature Prompt Tuning
Aug 06, 2024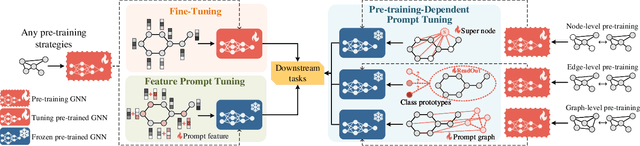
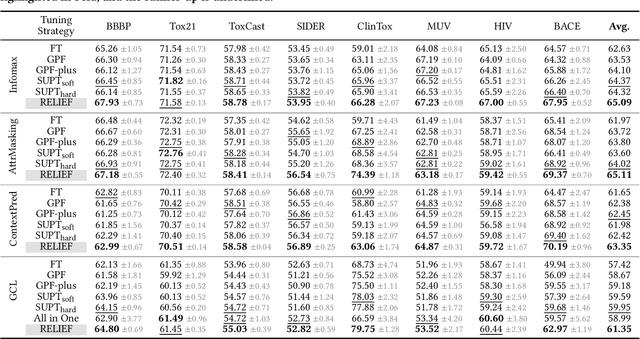
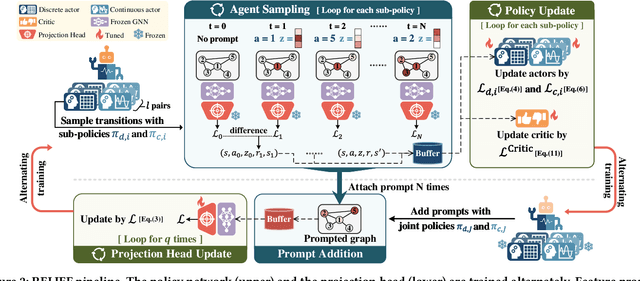
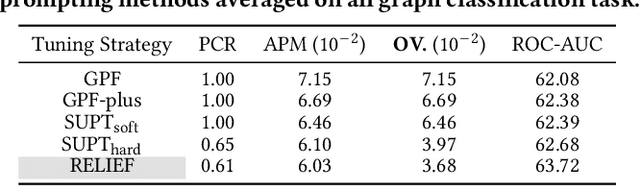
The advent of the "pre-train, prompt" paradigm has recently extended its generalization ability and data efficiency to graph representation learning, following its achievements in Natural Language Processing (NLP). Initial graph prompt tuning approaches tailored specialized prompting functions for Graph Neural Network (GNN) models pre-trained with specific strategies, such as edge prediction, thus limiting their applicability. In contrast, another pioneering line of research has explored universal prompting via adding prompts to the input graph's feature space, thereby removing the reliance on specific pre-training strategies. However, the necessity to add feature prompts to all nodes remains an open question. Motivated by findings from prompt tuning research in the NLP domain, which suggest that highly capable pre-trained models need less conditioning signal to achieve desired behaviors, we advocate for strategically incorporating necessary and lightweight feature prompts to certain graph nodes to enhance downstream task performance. This introduces a combinatorial optimization problem, requiring a policy to decide 1) which nodes to prompt and 2) what specific feature prompts to attach. We then address the problem by framing the prompt incorporation process as a sequential decision-making problem and propose our method, RELIEF, which employs Reinforcement Learning (RL) to optimize it. At each step, the RL agent selects a node (discrete action) and determines the prompt content (continuous action), aiming to maximize cumulative performance gain. Extensive experiments on graph and node-level tasks with various pre-training strategies in few-shot scenarios demonstrate that our RELIEF outperforms fine-tuning and other prompt-based approaches in classification performance and data efficiency.
Benchmarking Large Neighborhood Search for Multi-Agent Path Finding
Jul 12, 2024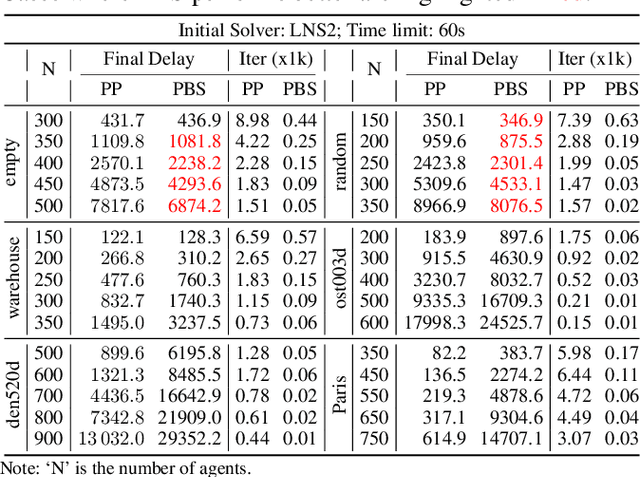
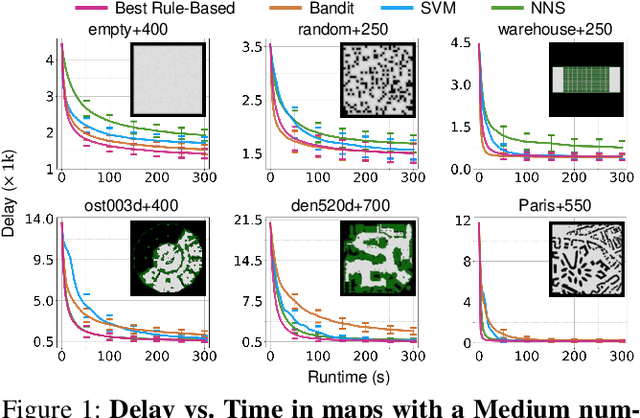

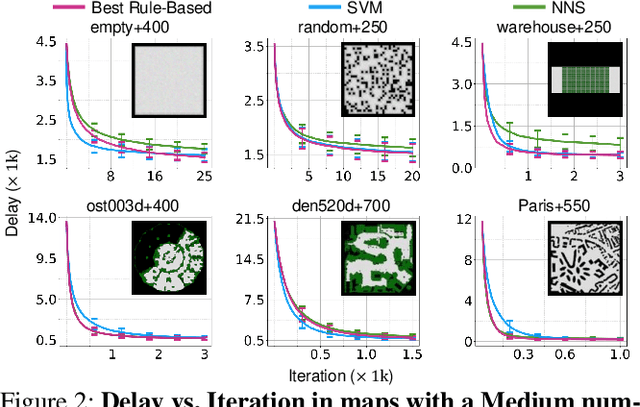
Multi-Agent Path Finding (MAPF) aims to arrange collision-free goal-reaching paths for a group of agents. Anytime MAPF solvers based on large neighborhood search (LNS) have gained prominence recently due to their flexibility and scalability. Neighborhood selection strategy is crucial to the success of MAPF-LNS and a flurry of methods have been proposed. However, several pitfalls exist and hinder a comprehensive evaluation of these new methods, which mainly include: 1) Lower than actual or incorrect baseline performance; 2) Lack of a unified evaluation setting and criterion; 3) Lack of a codebase or executable model for supervised learning methods. To overcome these challenges, we conduct a fair comparison across prominent methods on the same benchmark and hyperparameter search settings. Additionally, we propose a simple neighborhood selection strategy which marks a clear advancement in terms of runtime efficiency in large maps with large number of agents. Our benchmarking evaluation promotes new challenges for existing learning based methods and presents opportunities for future research when machine learning is integrated with MAPF-LNS. Code and data are available at https://github.com/ChristinaTan0704/mapf-lns-benchmark.
MapTracker: Tracking with Strided Memory Fusion for Consistent Vector HD Mapping
Mar 23, 2024



This paper presents a vector HD-mapping algorithm that formulates the mapping as a tracking task and uses a history of memory latents to ensure consistent reconstructions over time. Our method, MapTracker, accumulates a sensor stream into memory buffers of two latent representations: 1) Raster latents in the bird's-eye-view (BEV) space and 2) Vector latents over the road elements (i.e., pedestrian-crossings, lane-dividers, and road-boundaries). The approach borrows the query propagation paradigm from the tracking literature that explicitly associates tracked road elements from the previous frame to the current, while fusing a subset of memory latents selected with distance strides to further enhance temporal consistency. A vector latent is decoded to reconstruct the geometry of a road element. The paper further makes benchmark contributions by 1) Improving processing code for existing datasets to produce consistent ground truth with temporal alignments and 2) Augmenting existing mAP metrics with consistency checks. MapTracker significantly outperforms existing methods on both nuScenes and Agroverse2 datasets by over 8% and 19% on the conventional and the new consistency-aware metrics, respectively. The code will be available on our project page: https://map-tracker.github.io.
Prompt Tuning for Multi-View Graph Contrastive Learning
Oct 16, 2023In recent years, "pre-training and fine-tuning" has emerged as a promising approach in addressing the issues of label dependency and poor generalization performance in traditional GNNs. To reduce labeling requirement, the "pre-train, fine-tune" and "pre-train, prompt" paradigms have become increasingly common. In particular, prompt tuning is a popular alternative to "pre-training and fine-tuning" in natural language processing, which is designed to narrow the gap between pre-training and downstream objectives. However, existing study of prompting on graphs is still limited, lacking a framework that can accommodate commonly used graph pre-training methods and downstream tasks. In this paper, we propose a multi-view graph contrastive learning method as pretext and design a prompting tuning for it. Specifically, we first reformulate graph pre-training and downstream tasks into a common format. Second, we construct multi-view contrasts to capture relevant information of graphs by GNN. Third, we design a prompting tuning method for our multi-view graph contrastive learning method to bridge the gap between pretexts and downsteam tasks. Finally, we conduct extensive experiments on benchmark datasets to evaluate and analyze our proposed method.
Empower Text-Attributed Graphs Learning with Large Language Models (LLMs)
Oct 15, 2023



Text-attributed graphs have recently garnered significant attention due to their wide range of applications in web domains. Existing methodologies employ word embedding models for acquiring text representations as node features, which are subsequently fed into Graph Neural Networks (GNNs) for training. Recently, the advent of Large Language Models (LLMs) has introduced their powerful capabilities in information retrieval and text generation, which can greatly enhance the text attributes of graph data. Furthermore, the acquisition and labeling of extensive datasets are both costly and time-consuming endeavors. Consequently, few-shot learning has emerged as a crucial problem in the context of graph learning tasks. In order to tackle this challenge, we propose a lightweight paradigm called ENG, which adopts a plug-and-play approach to empower text-attributed graphs through node generation using LLMs. Specifically, we utilize LLMs to extract semantic information from the labels and generate samples that belong to these categories as exemplars. Subsequently, we employ an edge predictor to capture the structural information inherent in the raw dataset and integrate the newly generated samples into the original graph. This approach harnesses LLMs for enhancing class-level information and seamlessly introduces labeled nodes and edges without modifying the raw dataset, thereby facilitating the node classification task in few-shot scenarios. Extensive experiments demonstrate the outstanding performance of our proposed paradigm, particularly in low-shot scenarios. For instance, in the 1-shot setting of the ogbn-arxiv dataset, ENG achieves a 76% improvement over the baseline model.